Impala Tutorial for Beginners | Impala Hadoop Tutorial
Basically, to overcome the slowness of Hive Queries, Cloudera offers a separate tool and that tool is what we call Impala. However, there is much more to know about the Impala.
So, in this Impala Tutorial for beginners, we will learn the whole concept of Cloudera Impala. It includes Impala’s benefits, working as well as its features. Moreover, we will also learn about Daemons in Impala in this Impala Tutorials.
What is Impala? – An Impala Overview
A tool which we use to overcome the slowness of Hive Queries is what we call Impala. This separate tool was provided by Cloudera distribution. Syntactically Impala queries run very faster than Hive Queries even after they are more or less same as Hive Queries.
It offers high-performance, low-latency SQL queries. Impala is the best option while we are dealing with medium sized datasets and we expect the real-time response from our queries. However, make sure Impala is available only in Hadoop distribution.
Since MapReduce store intermediate results in the file system, Impala is not built on MapReduce. Hence, it is very slow for real-time query processing.
In addition, Impala has its own execution engine. Basically, that stores the intermediate results in In-memory. Therefore, when compared to other tools which use MapReduce its query execution is very fast.
Some Key Points
- It offers high-performance, low-latency SQL queries.
- Moreover, to share databases and tables between both Impala and Hive it integrates very well with the Hive Metastore.
- Also, it is Compatible with HiveQL Syntax
- We can easily integrate with HBase database system and Amazon Simple Storage System (S3) by using Impala. Also, it provides SQL front-end access to these.
In other words, we can run a query, evaluate the results immediately, and fine-tune the query, by using Impala. In October 2012, this engine was introduced with a public beta test distribution.
However, the final version was made available in May 2013. Moreover, to analyze Hadoop data via SQL or other business intelligence tools, analysts and data scientists use Impala.
Also, we can perform interactive, ad-hoc and batch queries together in the Hadoop system, by using Impala’s MPP (M-P-P) style execution along with other Hadoop processing MapReduce frameworks. If you face any queries in this impala tutorial, Please Comment.
Why Impala Hadoop?
Business intelligence data was typically condensed into a manageable chunk of high-value information, before Impala. Also, this process is minimized with Impala.
However, in Hadoop, the data arrives after fewer steps, whereas Impala queries it immediately. Also, the high-capacity and high-speed storage system of a Hadoop cluster let you bring in all the data.
Moreover, we can skip the time-consuming steps of loading and reorganizing data since Impala can query raw data files. For querying analytic data it offers new possibilities.
In addition, to query this type of data we can use exploratory data analysis and data discovery techniques. Next, in Impala tutorial, let’s see the major Impala Hadoop Benefits.
Impala Hadoop Benefits
- Impala is very familiar SQL interface. Especially data scientists and analysts already know.
- It also offers the ability to query high volumes of data (“Big Data“) in Apache Hadoop.
- Also, it provides distributed queries for convenient scaling in a cluster environment. It offers to use of cost-effective commodity hardware.
- By using Impala it is possible to share data files between different components with no copy or export/import step.
- Moreover, it is a single system for big data processing and analytics. Hence, through this customers can avoid costly modeling and ETL just for analytics.
How Impala Works with CDH
Let’s see the below graphic in this Apache Impala tutorial that illustrates how Impala is positioned in the broader environment:
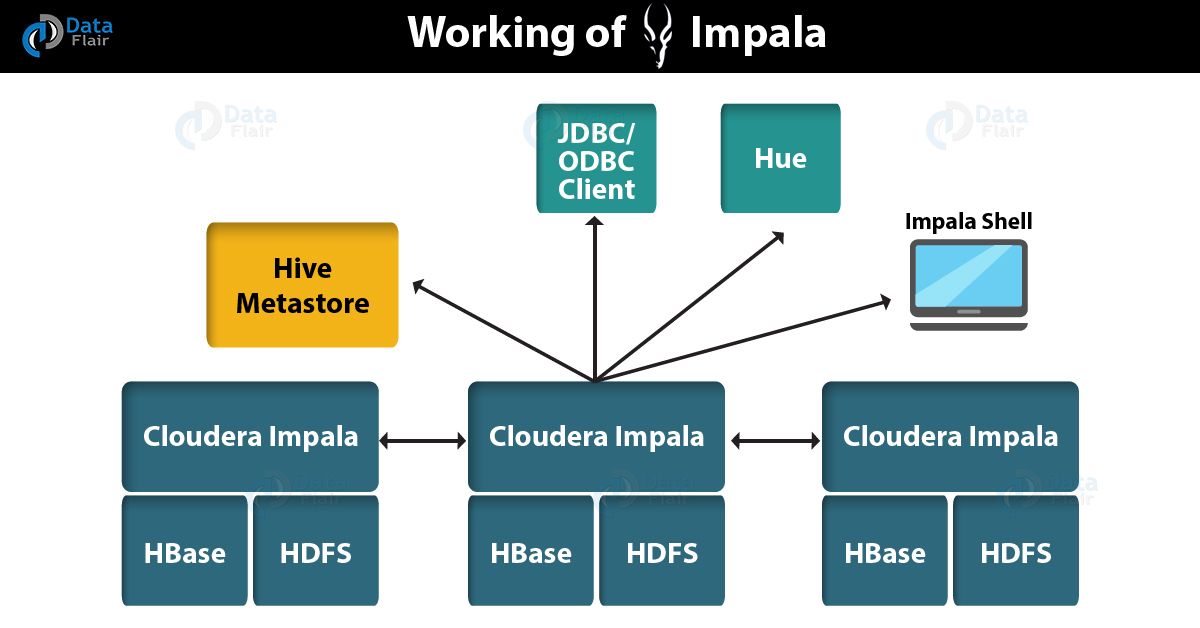
Impala Tutorial – Working of Impala
So, above Architecture diagram, implies how Impala relates to other Hadoop components. Like HDFS, the Hive Metastore database, client programs [ JDBC and ODBC applications] and the Hue web UI.
There are following components the Impala solution is composed of such as:
a. Clients
Many of the entities can interact with Impala. Such as Hue, ODBC clients, JDBC clients, and the Impala Shell. Basically, to issue queries or complete administrative tasks such as connecting to Impala we can use these interfaces.
b. Hive Metastore
In order to store information about the data available to Impala, we use it. Let’s understand this with the example. Here, the Metastore lets Impala know what databases are available. Also, it informs about what the structure of those databases is.
c. Impala
Basically, a process, which runs on DataNodes, coordinates and executes queries. By using Impala clients, each instance of Impala can receive, plan, and coordinate queries.
However, all queries are distributed among Impala nodes. So, these nodes then act as workers, executing parallel query fragments.
d. HBase and HDFS
It is generally a storage for data to be queried.
However, using Impala which queries are executed, they are handled as follows:
- Through ODBC or JDBC, user applications send SQL queries to Impala. Afterwards, that offers standardized querying interfaces.
- To determine what tasks need to be performed by impalad instances across the cluster Impala parses the query and analyzes it. Moreover, for optimal efficiency execution is planned.
- Also, by local impalad instances to provide data, services such as HDFS and HBase are accessed.
- Moreover, each impalad returns data to the coordinating impalad. Then that sends these results to the client.
Impala Features
Impala provides support for:
1. Impala offers support for most common SQL-92 features of Hive Query Language (HiveQL). It includes SELECT, joins, and aggregate functions.
2. Moreover, it also provides support for HDFS, HBase, and Amazon Simple Storage System (S3) storage. It includes:
– HDFS file formats: delimited text files, Parquet, Avro, SequenceFile, and RCFile.
– Compression codecs: Snappy, GZIP, Deflate, BZIP.
3. Also, supports common data access interfaces. Includes:
– JDBC driver.
– ODBC driver.
4. However, it supports Hue Beeswax and the Impala Query UI.
5. Also, supports impala-shell command-line interface.
6. Moreover, supports Kerberos authentication.
Any doubt yet in Impala Tutorial for beginners? Please Comment.
Daemons in Impala

Impala Daemons
a. Impala D (Impala Daemon)
Basically, this daemon will be one per node. Moreover, on every data node, it will be installed. They form the core of the Impala execution engine and are the ones reading data from HDFS/HBase and aggregating/processing it.
That is somehow a real work. In addition, we can say all ImpalaD’s are equivalent.
In addition, to store the mapping between table and files this daemon will use Hive metastore. Also, uses HDFS NN to get the mapping between files and blocks. Therefore, to get/process the data impala uses hive metastore and Name Node.
- This daemon accepts queries from several tools such as; the impala-shell command, Hue, JDBC, or ODBC.
- It distributes work across the cluster and parallelizes the queries. Further, it transmits intermediate query results back to the central coordinator node.
- Moreover, while this daemon runs on a data node on which user submitted a query, that acts as a coordinator node for that query. However, running on other nodes the ImpalaD daemons submits their partial results to this coordinator node. Further, by aggregating/combining partial results coordinator node prepares the final result.
Moreover, there are 3 major components of ImpalaD such as:
- Query Planner
- Coordinator
- Executor
Let’s discuss each component in detail:
- The Query Planner
Basically, for parsing out the query, Query Planner is responsible. However, this planning occurs in 2 parts.
- Since all the data in the cluster resided on just one node, a single node plan is made, at first.
- Afterwards, on the basis of the location of various data sources in the cluster, this single node plan is converted to a distributed plan (thereby leveraging data locality).
- Query Coordinator
For coordinating the execution of the entire query Query Coordinator is responsible. Basically, to read and process data, it sends requests to various executors. Afterward, it receives the data back from these executors and streams it back to the client via JDBC/ODBC.
- Executor
Also, aggregations of data Executor is responsible. Especially, the data which is read locally or if not available locally could be streamed from executors of other Impala daemons.
b. StatestoreD
It implements the Impala statestore service. That monitors the availability of Impala services across the cluster. Also, handles situations such as nodes becoming unavailable or becoming available again.
- It installed on 1 instance of an N node cluster.
- We can say Statestore daemon is a name service. That implies that it keeps track of which ImpalaD’s are up and running, and relays this information to all the ImpalaD’s in the cluster. Hence, they are aware of this information when distributing tasks to other ImpalaD’s.
- Also, make sure it isn’t a single point of failure. Even when state stored dies, albeit, with stale name service data, Impala daemons still continue to function.
c. CatalogD
Generally, on 1 instance of an N node cluster, CatalogD is installed. Also, via the state stored it distributes metadata to Impala daemons. Also, make sure it isn’t a single point of failure.
In any way, impala daemons still continue to function. To invalidate the metadata if there is an update to it the user has to manually run a command.
However, we need to issue REFRESH or INVALIDATE METADATA on an Impala node before executing a query there if we create any table, load data, and so on through Hive. Now let’s discuss other important points in Impala Tutorial in the below section.
Other Important Points in Impala Tutorial
- For fast access, ImpalaD’s caches the metadata.
- Moreover, for parquet format(columnar oriented format), Impala will be the best fit
- Also, it will use OS cache.
- Generally, in each node, 128 GB RAM is recommended.
- In the small cluster, Scales well up to 100s of users
- Also, we can create tables or we can use tables in the hive, in Impala
- Load Test
- Here, no. of threads created by impalaD = 2 or 3x no of cores
- In Impala, intermediate results generally store in In-memory.
- Joins
– Also, in the FROM clause of a query, largest table should be listed first.
– In Impala, BROADCAST Join is a Default join.
– For one big table and many small tables, Broadcast join is the best fit.
– Also, large data cannot be stored in in-memory, BROADCAST join is not good for two large tables.
– We have to use PARTITIONED join, for two large tables.
Controlling Access to Data
Basically, through Authorization, Authentication, and Auditing we can control data access in Impala. Also, for user authorization, we can use the Sentry open source project. Sentry includes a detailed authorization framework for Hadoop.
Also, associates various privileges with each user of the computer. In addition, by using authorization techniques we can control access to Impala data.
This was all about Impala Tutorial for beginners.
Conclusion: Impala Tutorial
Hence, in this Impala Tutorial for beginners, we have seen the complete lesson to Impala. Still, if any query occurs in Impala tutorial, feel free to ask in the comment section. Also, keep visiting our site for more blogs on Impala.
Hope you like the Impala Tutorial.
If you are Happy with DataFlair, do not forget to make us happy with your positive feedback on Google





I am a beginner to Impala and Hadoop. To which databse, Impala SQL is used?