Impala Architecture | Components of Impala
As we all know, Impala is an MPP (Massive Parallel Processing) query execution engine. It has three main components in its Architecture such as Impala daemon (ImpalaD), Impala Statestore, and Impala metadata or metastore.
So, in this blog, “Impala Architecture”, we will learn the whole concept of Impala Architecture. Apart from components of Impala, we will also learn its Query Processing Interfaces as well as Query Execution Procedure.
So, let’s start Impala Architecture.
Impala Architecture
Basically, the Impala engine consists of different daemon processes that run on specific hosts within your CDH cluster. So, let’s discuss each one by one. If you face any query in this Impala Architecture article, Please Comment.
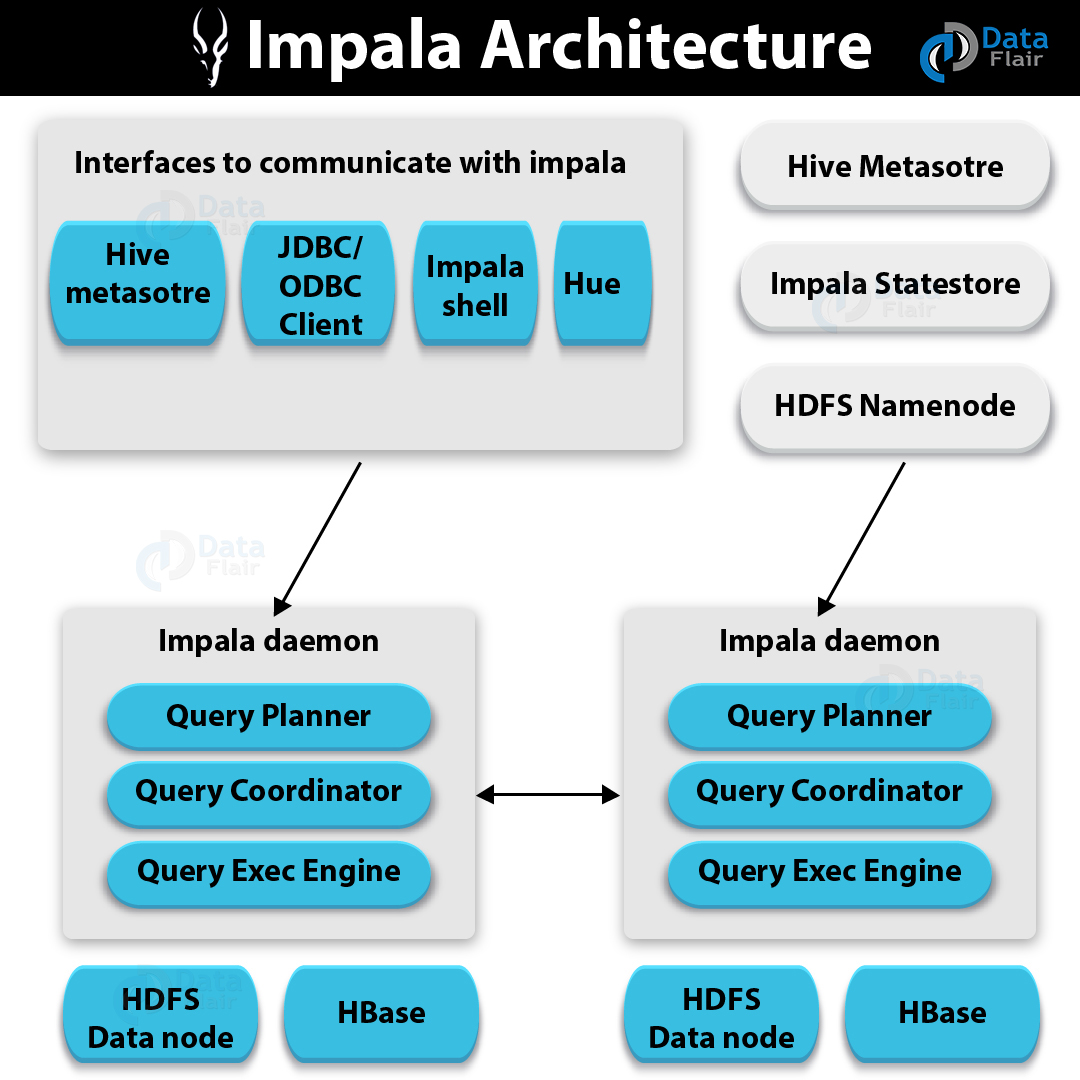
Impala Architecture – Components of Impala
i. Impala Daemon
While it comes to Impala Daemon, it is one of the core components of the Hadoop Impala. Basically, it runs on every node in the CDH cluster. It generally identified by the Impalad process.
Moreover, we use it to read and write the data files. In addition, it accepts the queries transmitted from impala-shell command, ODBC, JDBC or Hue.
Moreover, on any Datanode, we can connect and submit the query to the Impala Daemon. Further, from all nodes, it also collects the results back.
Also, to confirm which node is healthy and accepts the new work, Impala Daemon will always be communicating to statestore.
Moreover, whenever any Impala node in the cluster creates, alter, drops any object or any statement like insert, load data is processed, each Daemon will also receive the broadcasted message.
ii. Impala Statestore
To check the health of all Impala Daemons on all the data nodes in the Hadoop cluster we use The Impala Statestore. Also, we call it a process statestored. However, only in the Hadoop cluster one such process we need on one host.
The major advantage of this Daemon is it informs all the Impala Daemons if an Impala Daemon goes down. Hence, they can avoid the failed node while distributing future queries.
iii. Impala Catalog Service
The Catalog Service tells metadata changes from Impala SQL statements to all the Datanodes in Hadoop cluster. Basically, by Daemon process catalogD it is physically represented.
Also, we only need one such process on one host in the Hadoop cluster. Generally, as catalog services are passed through statestored, statestored and catalogd process will be running on the same host.
Moreover, it also avoids the need to issue REFRESH and INVALIDATE METADATA statements. Even when the metadata changes are performed by statements issued through Impala.
Impala Query Processing Interfaces
However, Impala offers three interfaces in order to process queries such as:
i. Impala-shell
Basically, by typing the command impala-shell in the editor, we can start the Impala shell. But it happens after setting up Impala using the Cloudera VM.
ii. Hue interface
Moreover, using the Hue browser we can easily process Impala queries. Also, we have Impala query editor in the Hue browser. Thus, there we can type and execute the Impala queries. Although, at first, we need to logging to the Hue browser in order to access this editor.
iii. ODBC/JDBC drivers
Impala offers ODBC/JDBC drivers, as same as other databases. Moreover, we can connect to impala through programming languages by using these drivers. Hence, that supports these drivers and build applications that process queries in Impala using those programming languages.
Impala Query Execution Procedure
Basically, using any of the interfaces provided, whenever users pass a query, this is accepted by one of the Impala in the cluster. In addition, for that particular query, this Impala is treated as a coordinator.
Further, using the Table Schema from the Hive metastore the query coordinator verifies whether the query is appropriate, just after receiving the query.
Afterward, from HDFS namenode it collects the information about the location of the data which is required to execute the query. Then, to execute the query it sends this information to other Impalads.
Moreover, we can see that all the other Impala daemons read the specified data block. Also, processes the query. However, the query coordinator collects the result back and delivers it to the user, once the daemons complete their tasks.
This was all about Impala Architecture Tutorial. Hope you like our explanations of the Components of Impala.
Conclusion
As a result, we have seen the whole concept of Impala Architecture. Still, if any doubt occurs regarding Impala Architecture feel free to ask in the comment section.
Did we exceed your expectations?
If Yes, share your valuable feedback on Google




