Top 50 Impala Interview Questions and Answers
In this tutorial on Impala Interview Questions, we have covered top 50 Impala Interview Questions and answers. Basically, we will provide you 50 Impala Interview Questions for best preparation.
Also, these Impala Interview Questions includes deep aspects of Impala for freshers as well as for experienced professionals. These Impala Interview Questions will surely help you to sort out your every concept of Impala.
Top 50 Impala Interview Questions and Answers
So, here, is the list of Top 50 prominent Impala Interview Questions.
Que 1. What is Impala?
Ans. Basically, for processing huge volumes of data Impala is an MPP (Massive Parallel Processing) SQL query engine which is stored in Hadoop cluster.
Moreover, this is an advantage that it is an open-source software which is written in C++ and Java. Also, it offers high performance and low latency compared to other SQL engines for Hadoop.
To be more specific, it is the highest-performing SQL engine that offers the fastest way to access data that is stored in Hadoop Distributed File System HDFS.
Que 2. Why we need Impala Hadoop?
Ans. Along with the scalability and flexibility of Apache Hadoop, Impala combines the SQL support and multi-user performance of a traditional analytic database, by utilizing standard components. Like HDFS, HBase, Metastore, YARN, and Sentry.
Also, users can communicate with HDFS or HBase using SQL queries With Impala, even in a faster way compared to other SQL engines like Hive.
It can read almost all the file formats used by Hadoop. Like Parquet, Avro, RCFile.
Moreover, it uses the same metadata, SQL syntax (Hive SQL), ODBC driver, and user interface (Hue Beeswax) as Apache Hive. Also, offers a familiar and unified platform for batch-oriented or real-time queries.
Impala is not based on MapReduce algorithms, unlike Apache Hive.
Hence, Impala faster than Apache Hive, since it reduces the latency of utilizing MapReduce.
Que 3. State some Impala Hadoop Benefits.
Ans. Some of the benefits are:
- Impala is very familiar SQL interface. Especially data scientists and analysts already know.
- It also offers the ability to query high volumes of data (“Big Data“) in Apache Hadoop.
- Also, it provides distributed queries for convenient scaling in a cluster environment. It offers to use of cost-effective commodity hardware.
- By using Impala it is possible to share data files between different components with no copy or export/import step.
Que 4. What are the best features of Impala?
Ans. There are several best features of Impala. They are :
- Open Source
Basically, under the Apache license, Cloudera Impala is available freely as open source.
- In-memory Processing
While it’s come to processing, Cloudera Impala supports in-memory data processing. That implies without any data movement it accesses/analyzes data that is stored on Hadoop data nodes.
- Easy Data Access
However, using SQL-like queries, we can easily access data using Impala. Moreover, Impala offers Common data access interfaces. That includes:
i. JDBC driver.
ii. ODBC driver.
- Faster Access
While we compare Impala to another SQL engines, Impala offers faster access to the data in HDFS.
- Storage Systems
We can easily store data in storage systems. Such as HDFS, Apache HBase, and Amazon s3.
i. HDFS file formats: delimited text files, Parquet, Avro, SequenceFile, and RCFile.
ii. Compression codecs: Snappy, GZIP, Deflate, BZIP.
- Easy Integration
It is possible to integrate Impala with business intelligence tools. Such as; Tableau, Pentaho, Micro strategy, and Zoom data.
- Joins and Functions
Including SELECT, joins, and aggregate functions, Impala offers most common SQL-92 features of Hive Query Language (HiveQL).
Que 5. What are Impala Architecture Components?
Ans. Basically, the Impala engine consists of different daemon processes that run on specific hosts within your CDH cluster.
i. The Impala Daemon
While it comes to Impala Daemon, it is one of the core components of the Hadoop Impala. Basically, it runs on every node in the CDH cluster. It generally identified by the Impalad process.
Moreover, we use it to read and write the data files. In addition, it accepts the queries transmitted from impala-shell command, ODBC, JDBC or Hue.
ii. The Impala Statestore
To check the health of all Impala Daemons on all the data nodes in the Hadoop cluster we use The Impala Statestore. Also, we call it a process statestored.
However, Only in the Hadoop cluster one such process we need on one host.
The major advantage of this Daemon is it informs all the Impala Daemons if an Impala Daemon goes down. Hence, they can avoid the failed node while distributing future queries.
iii. The Impala Catalog Service
The Catalog Service tells metadata changes from Impala SQL statements to all the Datanodes in Hadoop cluster. Basically, by Daemon process catalogd it is physically represented. Also, we only need one such process on one host in the Hadoop cluster.
Generally, as catalog services are passed through statestored, statestored and catalogd process will be running on the same host.
Moreover, it also avoids the need to issue REFRESH and INVALIDATE METADATA statements. Even when the metadata changes are performed by statements issued through Impala.
Basic Impala Interview Questions for freshers
These Impala Interview Questions are of basic level for fresher. However experienced can also refer them to revise their knowledge on Impala interview Questions.
Que 6. What are Impala Built-in Functions?
Ans. In order to perform several functions like mathematical calculations, string manipulation, date calculations, and other kinds of data transformations directly in SELECT statements we can use Impala Built-in Functions.
We can get results with all formatting, calculating, and type conversions applied, with the built-in functions SQL query in Impala. Despite performing time-consuming postprocessing in another application we can use the Impala Built-in Functions.
Impala support following categories of built-in functions. Such as:
- Mathematical Functions
- Type Conversion Functions
- Date and Time Functions
- Conditional Functions
- String Functions
- Aggregation functions
Que 7. How to call Impala Built-in Functions.
Ans. In order to call any of these Impala functions by using the SELECT statement. Basically, for any required arguments we can omit the FROM clause and supply literal values, for the most function:
select abs(-1);
select concat(‘The rain ‘, ‘in Spain’);
select po
Que 8. What is Impala Data Types?
Ans. There is a huge set of data types available in Impala. Basically, those Impala Data Types we use for table columns, expression values, and function arguments and return values. Each Impala Data Types serves a specific purpose. Types are:
- BIGINT
- BOOLEAN
- CHAR
- DECIMAL
- DOUBLE
- FLOAT
- INT
- SMALLINT
- STRING
- TIMESTAMP
- TINYINT
- VARCHAR
- ARRAY
- Map
- Struct
Que 9. State some advantages of Impala:
Ans. There are several advantages of Cloudera Impala. So, here is a list of those advantages.
- Fast Speed
Basically, we can process data that is stored in HDFS at lightning-fast speed with traditional SQL knowledge, by using Impala.
- No need to move data
However, while working with Impala, we don’t need data transformation and data movement for data stored on Hadoop. Even if the data processing is carried where the data resides (on Hadoop cluster),
- Easy Access
Also, we can access the data that is stored in HDFS, HBase, and Amazon s3 without the knowledge of Java (MapReduce jobs), by using Imala. That implies we can access them with a basic idea of SQL queries.
- Short Procedure
Basically, while we write queries in business tools, the data has to be gone through a complicated extract-transform-load (ETL) cycle. However, this procedure is shortened with Impala.
Moreover, with the new techniques, time-consuming stages of loading & reorganizing is resolved. Like, exploratory data analysis & data discovery making the process faster.
- File Format
However, for large-scale queries typical in data warehouse scenarios, Impala is pioneering the use of the Parquet file format, a columnar storage layout. Basically, that is very optimized for it.
Que 10. State some disadvantages of Impala.
Ans. Some of the drawbacks of using Impala are as follows −
i. No support SerDe
There is no support for Serialization and Deserialization in Impala.
ii. No custom binary files
Basically, we cannot read custom binary files in Impala. It only read text files.
iii. Need to refresh
However, we need to refresh the tables always, when we add new records/ files to the data directory in HDFS.
iv. No support for triggers
Also, it does not provide any support for triggers.
v. No Updation
In Impala, We cannot update or delete individual records.
Que 11. Describe Impala Shell (impala-shell Command).
Ans. Basically, to set up databases and tables, insert data, and issue queries, we can use the Impala shell tool (impala-shell). Moreover, we can submit SQL statements in an interactive session for ad hoc queries and exploration.
Also, to process a single statement or a script file or to process a single statement or a script file we can specify command-line options.
In addition, it supports all the same SQL statements listed in Impala SQL Statements along with some shell-only commands. Hence, that we can use for tuning performance and diagnosing problems.
Que 12. Does Impala Use Caching?
Ans. No. There is no provision of caching table data in Impala. However, it does cache some table and file metadata. But queries might run faster on subsequent iterations because the data set was cached in the OS buffer cache, Impala does not explicitly control this.
Although, in CDH 5, Impala takes advantage of the HDFS caching feature. Hence, we can designate which tables or partitions are cached through the CACHED and UNCACHED clauses of the CREATE TABLE and ALTER TABLE statements.
Also, through the hdfscacheadmin command, Impala can take advantage of data that is pinned in the HDFS cache.
Que 13. How to control Access to Data in Impala?
Ans. Basically, through Authorization, Authentication, and Auditing we can control data access in Cloudera Impala. Also, for user authorization, we can use the Sentry open source project. Sentry includes a detailed authorization framework for Hadoop.
Also, associates various privileges with each user of the computer. In addition, by using authorization techniques we can control access to Impala data.
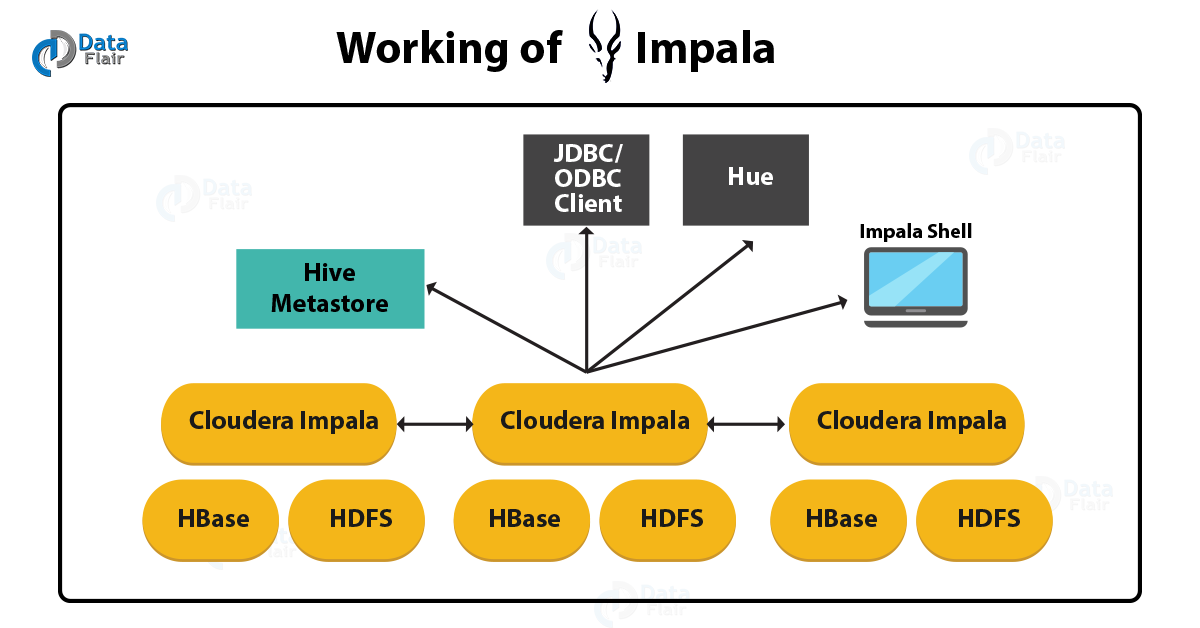
Impala Interview Questions – Working of Impala
Que 14. How Apache Impala Works with CDH
Ans. This below graphic illustrates how Impala is positioned in the broader Cloudera environment:
So, above Architecture diagram, implies how Impala relates to other Hadoop components.
Like HDFS, the Hive Metastore database, client programs [ JDBC and ODBC applications] and the Hue web UI.
There are following components the Impala solution is composed of. Such as:
i. Clients
To issue queries or complete administrative tasks such as connecting to Impala we can use these interfaces.
ii. Hive Metastore
to store information about the data available to Impala, we use it.
iii. Impala
Basically, a process, which runs on DataNodes, coordinates and executes queries. By using Impala clients, each instance of Impala can receive, plan, and coordinate queries. However, all queries are distributed among Impala nodes. So, these nodes then act as workers, executing parallel query fragments.
iv. HBase and HDFS
It is generally a Storage for data to be queried.
Que 15. What are the names of Daemons in Impala?
Ans. They are:
i. ImpalaD (impala Daemon)
ii. StatestoreD
iii. CatalogD
Frequently Asked Impala Interview Questions
Que 16 to Que 22 are frequently asked Impala interview question which to my opinion everyone should refer before appearing for an interview.
Que 16. What are distinct Operators in Impala?
Ans. While we want to filter the results or to remove duplicates, we use The DISTINCT operator in a SELECT statement:
— Returns the unique values from one column.
— NULL is included in the set of values if any rows have a NULL in this column.
select distinct c_birth_country from Employees;
— Returns the unique combinations of values from multiple columns.
select distinct c_salutation, c_last_name from Employees;
Moreover, to find how many different values a column contains, we can use DISTINCT in combination with an aggregation function.Typically COUNT():
— Counts the unique values from one column.
— NULL is not included as a distinct value in the count.
select count(distinct c_birth_country) from Employees;
— Counts the unique combinations of values from multiple columns.
select count(distinct c_salutation, c_last_name) from Employees;
However, make sure that using DISTINCT in more than one aggregation function in the same query is not supported by Impala SQL.
To understand more, we could not have a single query with both COUNT(DISTINCT c_first_name) and COUNT(DISTINCT c_last_name) in the SELECT list.
Que 17. What is Troubleshooting for Impala?
Ans. Basically, being able to diagnose and debug problems in Impala, is what we call Impala Troubleshooting/performance tuning.
It includes performance, network connectivity, out-of-memory conditions, disk space usage, and crash or hangs conditions in any of the Impala-related daemons. However, there are several ways, we can follow for diagnosing and debugging of above-mentioned problems. Such as:
- Impala performance tuning
- Impala Troubleshooting Quick Reference.
- Troubleshooting Impala SQL Syntax Issues
- Impala Web User Interface for Debugging
Que 18. Relational Databases and Impala
Ans. Here are some of the key differences between SQL and Impala Query language
- Impala
It uses an SQL like query language that is similar to HiveQL.
- Relational databases
It use SQL language.
- Impala
In Impala, you cannot update or delete individual records.
- Relational Databases
Here, it is possible to update or delete individual records.
- Impala
It does not support transactions.
- Relational databases
It support transactions.
- Impala
It does not support indexing.
- Relational Databases
It support indexing.
Que 19 Hive, HBase, and Impala.
Ans. Here is a comparative analysis of HBase, Hive, and Impala.
– HBase
HBase is wide-column store database based on Apache Hadoop. It uses the concepts of BigTable.
– Hive
Hive is a data warehouse software. Using this, we can access and manage large distributed datasets, built on Hadoop.
-Impala
Impala is a tool to manage, analyze data that is stored on Hadoop.
-HBase
The data model of HBase is wide column store.
– Hive
Hive follows the Relational model.
-Impala
Impala follows the Relational model.
– HBase
HBase is developed using Java language.
– Hive
Hive is developed using Java language.
-Impala
Impala is developed using C++.
– HBase
The data model of HBase is schema-free.
– Hive
Here, the data model of Hive is Schema-based.
-Impala
The data model of Impala is Schema-based.
– HBase
HBase provides Java, RESTful and, Thrift API’s.
–Hive
Hive provides JDBC, ODBC, Thrift API’s.
-Impala
Impala provides JDBC and ODBC API’s.
– HBase
Supports programming languages like C, C#, C++, Groovy, Java PHP, Python, and Scala.
–Hive
Supports programming languages like C++, Java, PHP, and Python.
-Impala
Impala supports all languages supporting JDBC/ODBC.
– HBase
It offers support for triggers.
–Hive
Hive does not provide any support for triggers.
-Impala
It does not provide any support for triggers.
Que 20. Does Impala Support Generic Jdbc?
Ans It supports the HiveServer2 JDBC driver.
Que 21. Is Avro Supported?
Ans. Yes, it supports Avro. Impala has always been able to query Avro tables. To load existing Avro data files into a table, we can use the Impala LOAD DATAstatement.
Que 22. How Do I Know How Many Impala Nodes Are In My Cluster?
Ans. Basically, how many impalad nodes are currently available, The Impala statestore keeps track. Through the statestore web interface, we can see this information.
Impala Interview Questions for Experienced
Que. 23 to Que. 40 are Impala Interview Questions for Experienced People which are a bit advanced.
Que 23. Can Any Impala Query Also Be Executed In Hive?
Ans. Yes. Impala queries can also be completed in Hive. However, there are some minor differences in how some queries are handled. Also, with some functional limitations, Impala SQL is a subset of HiveQL, such as transforms.
Que 24. What Are Good Use Cases For Impala As Opposed To Hive Or MapReduce?
Ans. For interactive exploratory analytics on large data sets, Impala is well-suited to executing SQL queries. Also, for very long-running, batch-oriented tasks, Hive and MapReduce are appropriate. Likes ETL.
Que25. Is Mapreduce Required For Impala? Will Impala Continue To Work As Expected If Mapreduce Is Stopped?
Ans. No. Impala does not use MapReduce at all.
Que 26. Can Impala Be Used For Complex Event Processing?
Ans. By dedicated stream-processing systems, Complex Event Processing (CEP) is usually performed. Impala most closely resembles a relational database. Hence, it is not a stream-processing system.
Que 27. How Do I Configure Hadoop High Availability (ha) For Impala?
Ans. To relay requests back and forth to the Impala servers we can set up a proxy server, for load balancing and high availability.
Que 28. What Is The Maximum Number Of Rows In A Table?
Ans. We can not say any maximum number. Because some customers have used Impala to query a table with over a trillion rows.
Que 29. On Which Hosts Does Impala Run?
Ans. However, for good performance, Cloudera strongly recommends running the impalad daemon on each DataNode. But it is not a hard requirement.
Since the data must be transmitted from one host to another for processing by “remote reads” if there are data blocks with no Impala daemons running on any of the hosts containing replicas of those blocks, queries involving that data could be very inefficient. Although, it is a condition Impala normally tries to avoid.
Que 30. How Are Joins Performed In Impala?
Ans. Using a cost-based method, Impala automatically determines the most efficient order in which to join tables, on the basis of their overall size and number of rows.
As per new feature, for efficient join performance, the COMPUTE STATS statement gathers information about each table that is crucial. For join queries, Impala chooses between two techniques, known as “broadcast joins” and “partitioned joins”.
Que 31. What Happens If There Is An Error In Impala?
Ans. However, there is not a single point of failure in Impala. To handle incoming queries all Impala daemons are fully able.
All queries with fragments running on that machine will fail if a machine fails, however. We can just rerun the query if there is a failure because queries are expected to return quickly.
Que 32. How Does Impala Process Join Queries For Large Tables?
Ans. To allow joins between tables and result sets of various sizes, Impala utilizes multiple strategies. While, joining a large table with a small one, the data from the small table is transmitted to each node for intermediate processing.
The data from one of the tables are divided into pieces, and each node processes only selected pieces, when joining two large tables.
Que 33. What Is Impala’s Aggregation Strategy?
Ans. It only supports in-memory hash aggregation. If the memory requirements for a join or aggregation operation exceed the memory limit for a particular host, In Impala 2.0 and higher, It uses a temporary work area on disk to help the query complete successfully.
Que 34. How Is Impala Metadata Managed?
Ans. There are two pieces of metadata, Impala uses. Such as the catalog information from the Hive metastore and the file metadata from the NameNode. Currently, this metadata is lazily populated and cached when an impalad needs it to plan a query.
Que 35. What Load Do Concurrent Queries Produce On The Namenode?
Ans. The load Impala generates is very similar to MapReduce. Impala contacts the NameNode during the planning phase to get the file metadata. Every impalad will read files as part of normal processing of the query.
Que 36. What size is recommended for each node?
Ans. Generally, in each node, 128 GB RAM is recommended.
Que 37. What is the no. of threads created by ImpalaD?
Ans. Here, no. of threads created by impalaD = 2 or 3x no of cores.
Que 38. What does Impala do for fast access?
Ans. For fast access, ImpalaD’s caches the metadata.
Que 39. What Impala use for Authentication?
Ans. It supports Kerberos authentication.
Que 40. What is used to store data generally?
Ans. In order to store information about the data available to Impala, we use it. Let’s understand this with the example. Here, the Metastore lets Impala know what databases are available. Also, it informs about what the structure of those databases is.
Advanced Impala Interview Questions
Below are some advanced Impala Interview Questions. However freshers can also refer them for advanced knowledge.
Que 41. Can Impala Do User-defined Functions (udfs)?Ans. Impala 1.2 and higher does support UDFs and UDAs. we can either write native Impala UDFs and UDAs in C++ or reuse UDFs (but not UDAs) originally written in Java for use with Hive.
Que 42. Is It possible to share data files between different components?
Ans. By using Impala it is possible to share data files between different components with no copy or export/import step.
Que 43. Does if offer scaling?
Ans. It provides distributed queries for convenient scaling in a cluster environment. Also, offers to use of cost-effective commodity hardware.
Que 44. Is There A Dual Table?
Ans. To running queries against a single-row table named DUAL to try out expressions, built-in functions, and UDFs. It does not have a DUAL table. Also, we can issue a SELECTstatement without any table name, to achieve the same result,
select 2+2;
select substr(‘hello’,2,1);
select pow(10,6);
Que 45. How Do I Load A Big Csv File Into A Partitioned Table?
Ans. In order to load a data file into a partitioned table, use a two-stage process. Especially, when the data file includes fields like year, month, and so on that correspond to the partition key columns. to bring the data into an unpartitioned text table, use the LOAD DATA or CREATE EXTERNAL TABLE statement.
Further, use an INSERT … SELECT statement to copy the data from the unpartitioned table to a partitioned one. Also, include a PARTITION clause in the INSERTstatement to specify the partition key columns.
Que 46. Can I Do Insert … Select * Into A Partitioned Table?
Ans. The columns corresponding to the partition key columns must appear last in the columns returned by the SELECT * when you use the INSERT … SELECT * syntax to copy data into a partitioned table. We can create the table with the partition key columns defined last.
Also, we can use the CREATE VIEW statement to create a view that reorders the columns: put the partition key columns last, then do the INSERT … SELECT * from the view.
Que 47. How can it help for avoiding costly modeling?
Ans. It is a single system for Big Data processing and analytics. Hence, through this customers can avoid costly modeling and ETL just for analytics.
Que 48. Does Impala Support Generic Jdbc?
Ans. Impala supports the HiveServer2 JDBC driver.
Que 49. Is The Hdfs Block Size Reduced To Achieve Faster Query Results?
Ans. No. Impala does not make any changes to the HDFS or HBase data sets.
Basically, the default Parquet block size is relatively large (256 MB in Impala 2.0 and later; 1 GB in earlier releases). Also, we can control the block size when creating Parquet files using the PARQUET_FILE_SIZE query option.
Que 50. State Use cases of Impala.
Ans. Impala Use Cases and Applications are:
- Do BI-style Queries on Hadoop
While it comes to BI/analytic queries on Hadoop especially those which are not delivered by batch frameworks such as Apache Hive, Impala offers low latency and high concurrency for them. Moreover, it scales linearly, even in multi-tenant environments.
- Unify Your Infrastructure
In Impala, there is no redundant infrastructure or data conversion/duplication is possible. Hence, that implies we need to utilize the same file and data formats and metadata, security, and resource management frameworks as your Hadoop deployment.
- Implement Quickly
Basically, Impala utilizes the same metadata and ODBC driver for Apache Hive users. Such as Hive, Impala supports SQL. Hence, we do not require to think about re-inventing the implementation wheel.
- Count on Enterprise-class Security
However, there is a beautiful feature of Authentication. So, for that Impala is integrated with native Hadoop security and Kerberos. Moreover, we can also ensure that the right users and applications are authorized for the right data by using the Sentry module.
- Retain Freedom from Lock-in
Also, it is available easily, which mean it is an Open source (Apache License).
This was all on Impala Interview Questions.
Conclusion: Impala Interview Questions
As a result, we have seen top 50 Impala Interview Questions. So, I hope this Impala Interview Questions will help you in the interview preparation. Furthermore, if you feel any query in this Impala Interview Questions, or you want to add some questions here, you can freely ask in comment box.
We work very hard to provide you quality material
Could you take 15 seconds and share your happy experience on Google




