Flume Data Flow – Types & Failure Handling in Apache Flume
If you want to know how data flows in Apache Flume then you have landed at the right place. This article explains the complete data flow mechanism in Apache Flume.
In this article, you will explore different data flow like multi-hop flow, fan-in flow, and fan-out flow. The article also covers failure handling to understand the topic in detail.
What is Apache Flume?
Apache Flume is an open-source distributed system for transferring streaming data from various applications to the central repository like HDFS, or HBase. It is highly reliable, extensible, robust, and fault-tolerant.
Apache Flume is useful for delivering log data from different sources to Hadoop HDFS. Its components are:
1. Flume Event
Flume event is the independent unit of data to be transferred from external sources to the central repository.
2. Flume Agent
It is a JVM process that consists of components (source, channels, and sink) through which the data flows from the external source to the next destination.
The Flume agent consists of a source, sink, and channel.
a. Source
It is the component of the flume agent which receives events from the external source like web servers.
b. Channels
The channel is a passive component that stores the event transferred by source until it is consumed by the sink. It is a bridge between the source and the sink.
c. Sink
The sink is the component of the flume agent that consumes data from the flume channel and pushes it to the central repository or forward it to the source of the next flume agent.
Introduction to Apache Flume Data Flow
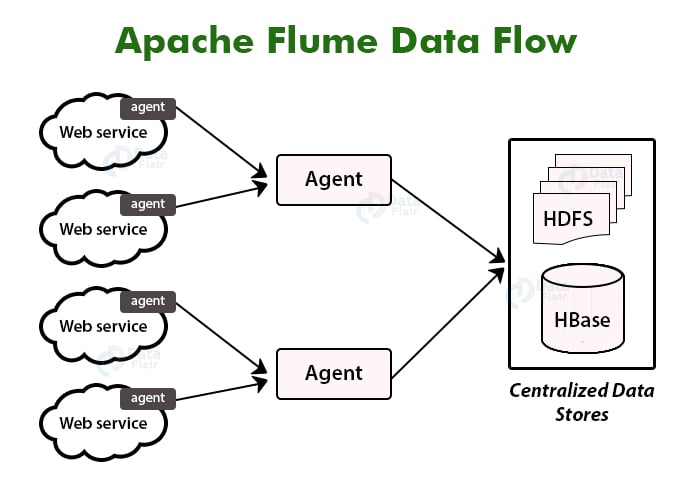
Apache Flume collects data from data generators like web servers and sends them to central repositories like HDFS.
The Flume collects data from data generators through Flume agents. The web servers have Flume agents running on them.
There can be an intermediate node in Flume data flow which aggregates data from Flume agents and passes them to the central repository. There can be multiple in Flume flow.
Agents pass the data to next agent or to the final destination ie external sink like HDFS.
Types of Data Flow in Flume
1. Multi-hop flow

In Flume flow, there can be more than one agent. The event (data) may travel through multiple agents before reaching the final destination. This is Multi-hop flow.
2. Fan-in flow

In Flume, data from multiple sources can be transferred through one channel. This is known as Fan-in flow.
3. Fan-out flow
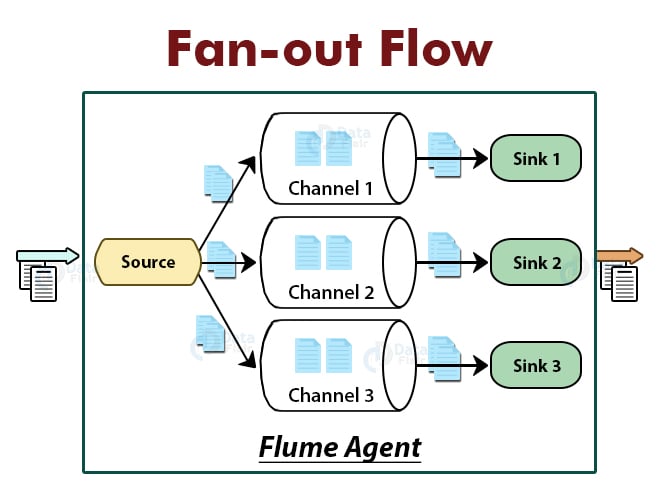
In fan-out flow, data flows from one source to multiple channels. There are two modes of fan-out flow. They are replicating and multiplexing.
a. Replicating
In the Replicating mode, the event (data) is replicated to all the configured channels.
b. Multiplexing
In multiplexing mode, event (data) is sent to selected channels based on the information in the event header.
Flume Failure Handling
Apache Flume has an in-built feature of Failure Handling. For each event in Flume, two transactions take place. One transaction occurs at the sender side and another at the receiver side. The sender sends the event to the receiver.
The receiver after receiving the event commits its own transaction and sends back a received signal to the sender. The sender after receiving the signal from the receiver commits its transaction. The sender will not commit its transaction until it receives a “received signal” from the receiver.
Summary
Apache Flume is a distributed system for collecting, aggregating, and transporting events from external sources to HDFS or HBase. The Flume agent runs on the webserver and collects data from web servers.
There can be multiple agents in the flume data flow, intermediate agents aggregate data from previous agents and push them on the central repository. Flume data flow is of three types that are multi-hop, fan-in, and fan-out flow.
In multi-hop, data travels through multiple agents before reaching the destination. In fan-in flow, data from multiple sources get transferred through one channel, and in fan-out flow, data from one source is transferred to multiple channels.
Did you like our efforts? If Yes, please give DataFlair 5 Stars on Google





content is very informative and simple to understand