Apache Flume Architecture – Flume Agent, Event, Client
In this article, you will study the architecture of Apache Flume. The article first provides the introduction to Apache Flume.
Then it covers Flume architecture. It explains Flume events, Flume agents like source, channel, and sink. In this article, you will also see some additional components of Flume agent like Interceptors, Channel selectors, sink processors.
Let us now first see a short introduction to Apache Flume.
Introduction to Flume
Apache Flume is a distributed system for collecting, aggregating, and transferring log data from multiple sources to a centralized data store. It is not only limited to log data.
Apache Flume can be used to transport large amounts of social-media generated data, network traffic data, email messages, and many more to a centralized data store.
In simple words, Apache Flume is a tool in the Hadoop ecosystem for transferring data from one location to another efficiently and reliably. The main goal of Apache Flume is to transfer data from applications to Hadoop HDFS.
It is highly robust, reliable, and fault-tolerant. The main purpose of designing Apache Flume is to move streaming data generated by various applications to Hadoop Distributed FileSystem.
Why Flume?
We use Flume usually for log data (streaming data) transfer. Apache Flume uses a simple data model that allows for online analytic application.
We can use Apache Flume in a situation when we have to analyze logs of various web servers. Logs are stored on the server. For analyzing the logs using Hadoop, we need to transfer the log to Hadoop HDFS. Transferring such a huge file over the network may lead to data loss or data breach.
The alternative option is to transfer the logs as they are created and storing them in the file system. Apache Flume is the best tool for such transfer. It takes data from data sources and writes it to the destination.
Flume Architecture
Apache Flume is for feeding streaming data from various data sources to the Hadoop HDFS or Hive. Apache Flume has a simple architecture that is based on streaming data flows. The design goal of Flume Architecture is,
1. Reliability
2. Scalability
3. Manageability
4. Extensibility
Before learning Flume architecture first understand what a Flume event is.
Flume Event
Flume event is the basic unit of the data that is to be transported inside Flume. A Flume event has a payload of the byte array. This is to be transferred from the source to the destination followed by optional headers. The below figure depicts the structure of the Flume event.

The below image depicts the Apache Flume architecture.
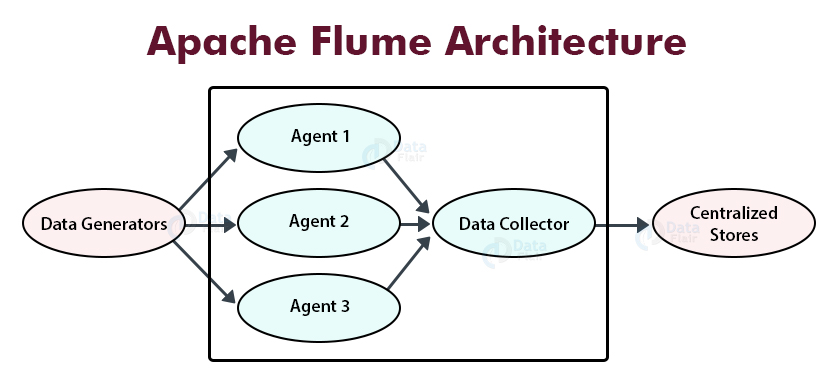
1. Data Generators
Data generators generate real-time streaming data. The data generated by data generators are collected by individual Flume agents that are running on them. The common data generators are Facebook, Twitter, etc.
2. Flume Agent
The agent is a JVM process in Flume. It receives events from the clients or other agents and transfers it to the destination or other agents. It is a JVM process that consists of three components that are a source, channel, and sink through which data flow occurs in Flume.

a. Source
A Flume source is the component of Flume Agent which consumes data (events) from data generators like a web server and delivers it to one or more channels.
The data generator sends data (events) to Flume in a format recognized by the target Flume source. Flume supports different types of sources. Each source receives events (data) from a specific data generator.
Example of Flume sources: Avro source, Exec source, Thrift source, NetCat source, HTTP source, Scribe source, twitter 1% source, etc.
b. Channel
When a Flume source receives an event from a data generator, it stores it on one or more channels. A Flume channel is a passive store that receives events from the Flume source and stores them till Flume sinks consume them.
Channel acts as a bridge between Flume sources and Flume sinks. Flume channels are fully transactional and can work with any number of Flume sources and sinks.
Example of Flume Channel− Custom Channel, File system channel, JDBC channel, Memory channel, etc.
c. Sink
The Flume sink retrieves the events from the Flume channel and pushes them on the centralized store like HDFS, HDFS, or passes them to the next agent.
Example of Flume Sink− HDFS sink, AvHBase sink, Elasticsearch sink, etc.
3. Data collector
The data collector collects the data from individual agents and aggregates them. It pushes the collected data to a centralized store.
4. Centralized store
Centralized stores are Hadoop HDFS, HBase, etc.
Additional Components of Flume Agent
Some more components play a significant role in transporting data from data generators to centralized stores.

1. Interceptors
Interceptors are for altering or inspecting Flume events transferred between Flume source and channel.
2. Channel Selectors
Channel Selectors are for determining which channel is to be chosen for transferring data in case of multiple channels.
They are of two types:
a. Default channel selectors
Default channel selectors are also called as replicating channel selectors. They are responsible for replicating all the events in each Flume channel.
b. Multiplexing channel selectors
Multiplexing channel selectors decide the channel to which an event is to be sent based on the address provided in the event header.
3. Sink Processors
Sink Processors are responsible for invoking a particular sink from a chosen group of sinks. They create failover paths for our sinks. These are for load balance events across multiple sinks.
Features of Apache Flume
- Apache Flume is an open-source tool.
- It has a simple and reliable architecture that is based on streaming data flows.
- Flume is highly robust and fault-tolerant with inbuilt features like reliability, failover, and recovery mechanism.
- It is mainly for copying streaming data (log data) from other sources to HDFS.
- It has different levels of reliability such as best-effort delivery and end-to-end delivery. Best-effort delivery doesn’t tolerate any node
- failure. On the other hand ‘end-to-end delivery’ mode guarantees delivery of data even in the case of multiple node failures.
- Flume offers high throughput and low latency.
- It is highly extensible, available, and horizontally scalable.
- Flume is customizable for different sources and sinks.
Summary
I hope after reading this article you understood the Flume architecture. The Flume architecture consists of data generators, Flume Agent, Data collector, and central repository. The Flume Agent consists of three components that are a source, channel, and sink.
There are other additional Flume components such as Interceptors, Channel selectors, and Sink Processors. The main goal of Apache Flume is to transfer data from applications to Hadoop HDFS
If you are Happy with DataFlair, do not forget to make us happy with your positive feedback on Google





can we use latest Elasticsearch with flume?