Avro Serialization | Serialization In Java & Hadoop
Placement-ready Online Courses: Your Passport to Excellence - Start Now
Today, we will learn Avro Serialization in detail. It includes Serialization Encodings in Avro, brief knowledge on Avro Serialization in Java and also we will cover Avro Serialization in Hadoop in detail.
Also, we will see the advantages and disadvantages of Hadoop over Java Avro Serialization. However, there is much more to learn about Avro Serialization in detail.
So, let’s begin with the introduction to Avro Serialization.

Avro Serialization | Serialization In Java & Hadoop
What is Avro Serialization?
In order to transport the data over the network or to store on some persistent storage, we use the process of translating data structures or objects state into binary or textual form, that process is what we call Serialization in Avro.
However, we need to deserialize the Data again, once the data transport over the network or retrieved from the persistent storage. In other words, Avro Serialization is known as marshaling and deserialization in Avro is known as unmarshalling.
Moreover, we can say, with its schema only Avro data serializes. Although, the Files which store Avro data must also involve the schema for that data in the same file.
However, there is a Remote Procedure Call (RPC) systems which is based on Avro, that must guarantee when the remote recipients of data have a copy of the schema which is used to write that data.
However, when the data is read, the schema which is used to write data is always available, that means Avro data is not tagged with type information, itself. We need a schema to parse data.
Generally, the way in which both the Avro serialization as well as deserialization proceed is, depth-first, left-to-right traversal of the schema. Especially, by serializing primitive types since they encounter.
Encodings in Avro Serialization
There are two serialization encodings available in Avro. One of them is binary encoding and the other one is JSON encoding. Since Binary coding is smaller and faster, most applications use the binary encoding.
Although, sometimes the JSON encoding is appropriate for debugging as well as web-based applications. So, let’s learn both the encodings in detail:

Encodings in Avro Serialization
a. Binary Encoding in Avro
Primitive Types
In binary, Primitive types are encoded as:
- As zero bytes, null is written.
- And, as a single byte, boolean is written whose value is either 0 (false) or 1 (true).
- Further, by using variable-length zig-zag coding, int and long values are written.
Example of Binary Encoding in Avro Serialization:
| value | hax |
| 0 | 00 |
| -1 | 01 |
| 1 | 02 |
| -2 | 03 |
| 2 | 04 |
| -64 | 7f |
| 64 | 80 01 |
- Make sure, as 4 bytes, we write a float. Further, by using a method equivalent to Java’s floatToIntBits, the float converts into a 32-bit integer and then encode it in little-endian format.
- Further, as 8 bytes, we write a double. Here also, using a method equivalent to Java’s doubleToLongBits, the double converts into a 64-bit integer and then encoded in little-endian format.
- However, as a long followed by that many bytes of data, bytes encode.
- And, as a long followed by that many bytes of UTF-8 encoded character data, a string is encoded.
b. JSON Encoding in Avro
Basically, the JSON encoding in Avro Serialization is the same as we use to encode field default values, except for unions.
In JSON, the value of a union is encoded as:
- It is encoded as a JSON null if its type is null.
- Else, with one name/value pair, it is encoded as a JSON object where the name is the type’s name and the value is the recursively encoded value. Make sure, the user-specified name is used, for Avro’s named types (record, fixed or enum), and, the type name is used, for other types.
Now, let’s understand it with an example, here the union schema [“null”,”string”,”Foo”], where Foo is a record name, and that would encode as:
- Null as null;
- The string “a” as {“string”: “a”}; and
- A Foo instance as {“Foo”: {…}}. Here {…} refer to JSON encoding of a Foo instance.
Although make sure, to correctly process JSON-encoded data, we need a schema. As an example, the JSON encoding does not consider any difference between records and maps, int and long or float and double and many more.
i. Single-object encoding
As there is the time when we need to store a single Avro serialized object for a longer period of time. However, a very common example for this is to store Avro records for various weeks in an Apache Kafka topic.
ii. Single object encoding specification
We encode this as –
- To show that the message is Avro, a two-byte marker, C3 01, and also it uses this single-record format (version 1).
- The 8-byte little-endian CRC-64-AVRO fingerprint of the object’s schema.
- By using Avro’s binary encoding, the Avro object encoded.
In addition, to determine whether a payload is Avro, Implementations use the 2-byte marker. However, when the message doesn’t encod Avro payload, this check helps avoid expensive lookups which resolve the schema from a fingerprint.
Avro Serialization in Java
There is a mechanism in Java which is known as object serialization. We can represent an object as a byte sequence that includes the object’s data as well as information about the object’s type and the types of data stored in the object.
It is possible to deserialize after serialization, once a serialized object is written into a file, we can read it and read it from the file and deserialized. In addition, to serialize and deserialize an object, ObjectInputStream and ObjectOutputStream class uses respectively in Java.
Avro Serialization in Hadoop
Especially for Interprocess Communication and Persistent Storage, in distributed systems like Hadoop, the concept of serialization is used.
Avro Serialization in Hadoop
a. Interprocess Communication
- Basically, RPC technique was used, to establish the interprocess communication between the nodes connected in a network.
- In order to convert the message into the binary format before sending it to the remote node via the network, RPC uses internal serialization. Further, the remote system deserializes the binary stream into the original message, at the other end.
- We need to follow the RPC serialization format −
- Compact
In order to use network bandwidth efficiently, which is the most scarce resource in a data center.
- Fast
The serialization and deserialization process should be quick with less overhead since the communication between the nodes is crucial in distributed systems.
- Extensible
It should be straightforward to evolve the protocol in a controlled manner for clients and servers because Protocols change over time to meet new requirements.
- Interoperable
The nodes that we write in different languages, must support by the message format.
b. Persistent Storage
Whereas, a digital storage which does not lose its data if any loss of power supply happens, that storage system is we call Persistent Storage. Its examples could be Magnetic disks and Hard Disk Drives.
The Writable Interface
Basically, the Writable Interface in Avro Serialization in Hadoop offers two methods for serialization as well as deserialization in Hadoop. The methods are:
- void readFields(DataInput in)
To deserialize the fields of the given object, we use this method.
- void write(DataOutput out)
Whereas, to serialize the fields of the given object we use this method.
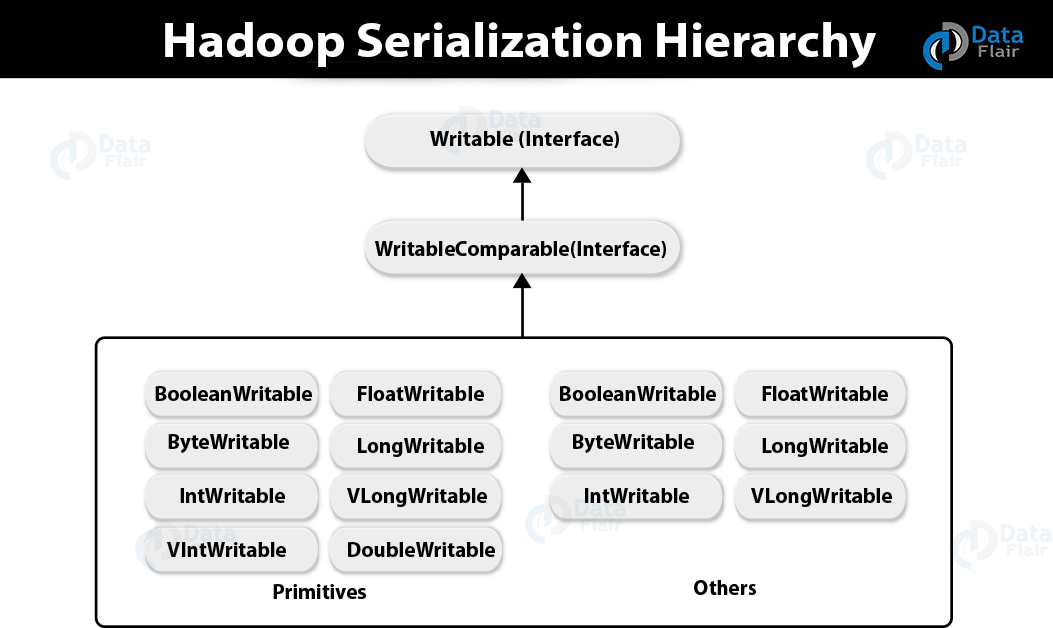
WritableComparable Interface
The WritableComparable Interface in Avro Serialization is the combination of two interfaces, one is Writable and the other one is Comparable Interfaces.
Basically, this interface inherits the Comparable interface of Java and Writable interface of Hadoop. Hence it offers methods for data serialization, deserialization, and comparison as well.
So, the method is:
- int compareTo(class obj)
The int compareTo(class obj) method, compares the current object with the given object obj.
Also, there is the number of wrapper classes which implement the WritableComparable interface in Hadoop.
Here each class wraps a Java primitive type. Now, we can see the Hadoop serialization class hierarchy in the following figure −
Avro Serialization – WritableComparable Interface
Hence, to serialize various types of data in Hadoop, these classes are useful.
IntWritable Class
The IntWritable Class in Avro serialization implements Writable, Comparable, as well as WritableComparable interfaces. Basically, it wraps an integer data type in it. Also, to serialize and deserialize integer type of data, this class offers some methods:
a. Constructors
IntWritable()
- IntWritable( int value)
b. Methods
- int get()
We can get the integer value present in the current object, by using this class.
- void readFields(DataInput in)
In order to deserialize the data in the given DataInput object, we use this method.
- void set(int value)
Moreover, to set the value of the current IntWritable object, we use this method.
- void write(DataOutput out)
Whereas, to serialize the data in the current object to the given DataOutput object, we use this method.
Serializing the Data in Hadoop
Now to serialize the integer type of data in Hadoop, the procedure is:
- At very first, Instantiate the IntWritable class by wrapping an integer value in it.
- After that, instantiate ByteArrayOutputStream class.
- Further, do instantiate DataOutputStream class and then pass the object of ByteArrayOutputStream class to it.
- Further, Serialize the integer value in the IntWritable object, by using the write() method. Also, make sure we need an object of DataOutputStream class while using this method.
- Ultimately, the data which we call serialize will store in the byte array object and further that data will pass as a parameter to the DataOutputStream class, at the time of instantiation.
Deserializing the Data in Hadoop
After serialization, the process to deserialize the integer type of data is :
- For deserialization, Instantiate IntWritable class by wrapping an integer value in it, at first.
- Then do instantiate ByteArrayOutputStream class.
- Furthermore, do Instantiate DataOutputStream class and also pass the object of ByteArrayOutputStream class to it.
- Afterward, by using readFields() method of IntWritable class, Deserialize the data in the object of DataInputStream.
- In this way, the deserialized data will store in the object of IntWritable class. And, using get() method of this class, we can retrieve this data.
Advantage of Hadoop Over Java Serialization
Basically, by reusing the Writable objects, Hadoop’s Writable-based serialization is capable of reducing the object-creation overhead. And, the Java’s native serialization framework cannot do this.
Disadvantages of Hadoop Serialization
There are two ways to serialize Hadoop data:
- One is provided by Hadoop’s native library, that is the Writable classes, we can use it.
- And, the other one is Sequence Files which store the data in binary format, we can also use this one.
However, one main disadvantage of using these two mechanisms,i.e. both Writables and SequenceFiles have only a Java API, that says we can not write or read it in any other language.
Hence that makes Hadoop a limited box. Hence, we can say Doug Cutting created Avro which is a language-independent data structure just to address this drawback.
So, this was all in Apache Avro Serialization. Hope you like our explanation.
Conclusion: Avro Serialization
Hence, we have seen the concept of Avro Serialization in detail. In this Avro Serialization Tutorial, we look at serialization in Java, Serialization in Hadoop, encoding in Avro Serialization. Moreover, we discussed the advantages and disadvantages of Hadoop Serialization.
Also, we saw Writable interface and inwritable class in Avro Serialization. Furthermore, if any doubt occurs regarding Serialization In Apache Avro, feel free to ask in the comment section. We are happy to help.
Your 15 seconds will encourage us to work even harder
Please share your happy experience on Google




