Machine Learning Project – SMS Spam Detection
Machine Learning courses with 100+ Real-time projects Start Now!!
In the era of digital communication, text messages have become a fundamental part of our lives, offering various opportunities for interaction. To address the disruptive and security risks of spam messages, our “SMS Spam Detection using Machine Learning” project leverages the power of machine learning.
By employing the Naive Bayes classifier and TF-IDF vectorization, we create a robust spam detection model that accurately distinguishes between genuine messages (ham) and harmful messages (spam). Our project involves visualizing label distribution, analyzing word statistics, and evaluating the model’s performance using various metrics.
Through this effort, we aim to provide a valuable tool to combat unwanted messages and enhance the efficiency and security of digital conversations, shielding users from SMS spam intrusion.
About SMS Spam Dataset
The SMS Spam Collection comprises a dataset of 5,574 English SMS messages classified as either “ham” (legitimate) or “spam,” gathered for SMS Spam research. Each file contains one message per line, with two columns: “v1” indicating the label (ham or spam) and “v2” containing the raw text.
The corpus was sourced from multiple sources on the Internet, including 425 SMS spam messages extracted from the Grumbletext website, which involved the challenging task of identifying spam claims from web pages. Additionally, a subset of 3,375 randomly selected ham messages from the NUS SMS Corpus and 450 SMS ham messages from Caroline Tag’s PhD Thesis were incorporated.
Furthermore, the corpus includes the SMS Spam Corpus v.0.1 Big, comprising 1,002 ham messages and 322 spam messages, utilized in academic research on SMS spam detection. This comprehensive dataset is valuable for studying and developing effective SMS spam detection models.
Tools and libraries used
1. NumPy (import numpy as np): NumPy is a powerful library for numerical computing in Python. It supports large, multi-dimensional arrays and matrices and a wide range of mathematical functions to efficiently operate on them.
2. pandas (import pandas as pd): pandas is a popular library for data manipulation and analysis in Python. It provides data structures like DataFrame, making it easy to handle and analyze structured data.
3. Matplotlib (import matplotlib.pyplot as plt): Matplotlib is a widely-used library for creating visualizations and plots in Python. It offers a variety of plotting functions and customization options to visualize data effectively.
4. seaborn (import seaborn as sns): seaborn is a data visualization library built on Matplotlib. It provides a high-level interface for creating attractive and informative statistical graphics.
5. scikit-learn (from sklearn…): scikit-learn is a comprehensive machine learning library in Python. It offers various algorithms and tools for model selection, data preprocessing, and evaluation.
Download Machine Learning SMS Spam Detection Project
Please download the Machine Learning SMS Spam Detection Project source code from the following link: Machine Learning SMS Spam Detection Project Code.
Steps to Detect Spams in SMS Using Machine Learning
Step 1: Reading and Preprocessing the Data
We start by reading the SMS Spam data from a CSV file using pandas’ `read_csv` function. Then, we drop unnecessary columns (‘Unnamed: 2’, ‘Unnamed: 3’, ‘Unnamed: 4’) using the `drop` method. The ‘v1’ and ‘v2’ columns are renamed to ‘label’ and ‘text’, respectively, for better understanding. We create a new column ‘label_enc’ to map the ‘ham’ and ‘spam’ labels to numerical values (0 and 1).
import numpy as np
import pandas as pd
# Reading the data
data = pd.read_csv(r"C:\Users\vaish\Downloads\SMS Spam Detection\spam.csv", encoding='latin-1')
data = data.drop(['Unnamed: 2', 'Unnamed: 3', 'Unnamed: 4'], axis=1)
data = data.rename(columns={'v1': 'label', 'v2': 'text'})
data['label_enc'] = data['label'].map({'ham': 0, 'spam': 1})Step 2: Visualizing Label Distribution
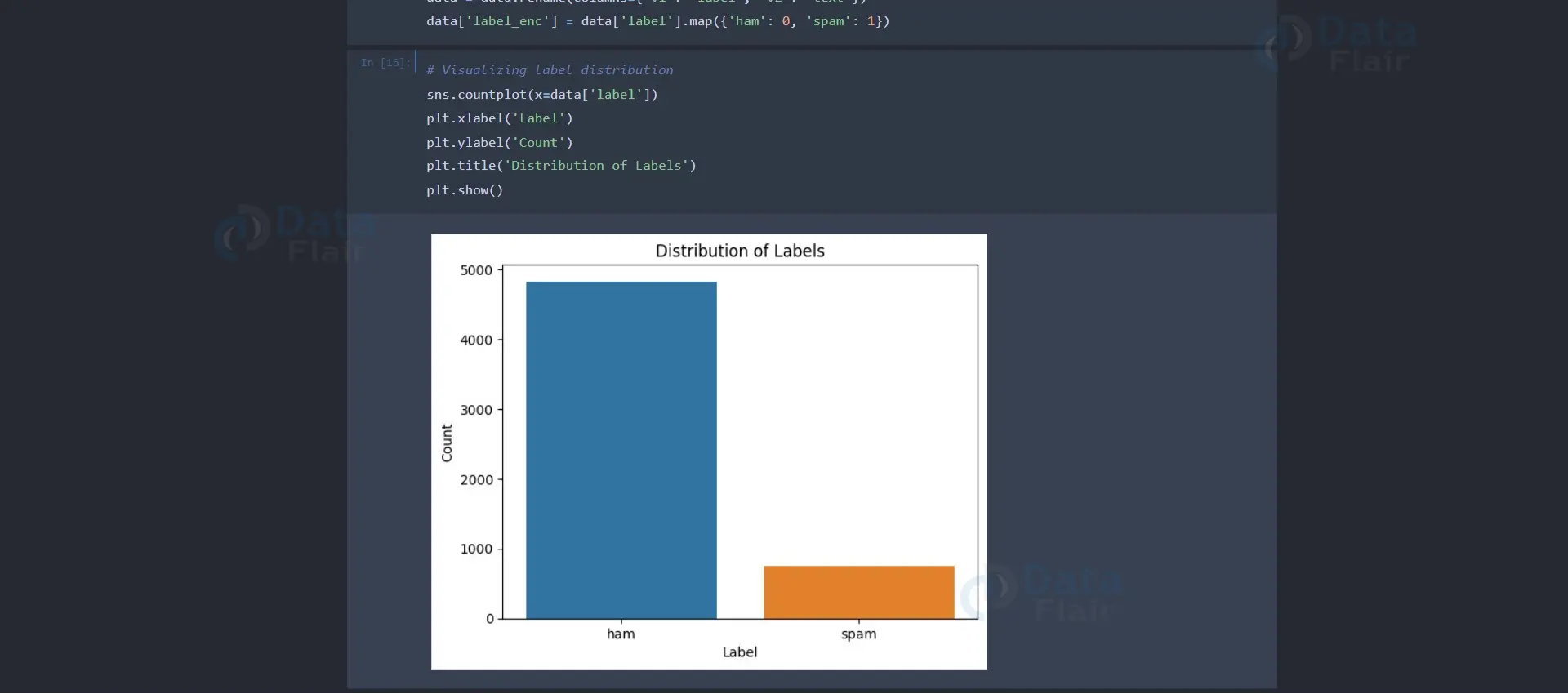
To gain insights into the balance of ham and spam messages in the dataset, we visualize the distribution using seaborn’s `countplot` and matplotlib.
import matplotlib.pyplot as plt
import seaborn as sns
# Visualizing label distribution
sns.countplot(x=data['label'])
plt.xlabel('Label')
plt.ylabel('Count')
plt.title('Distribution of Labels')
plt.show()Output
Step 3: Calculating Average Number of Tokens and Total Unique Words
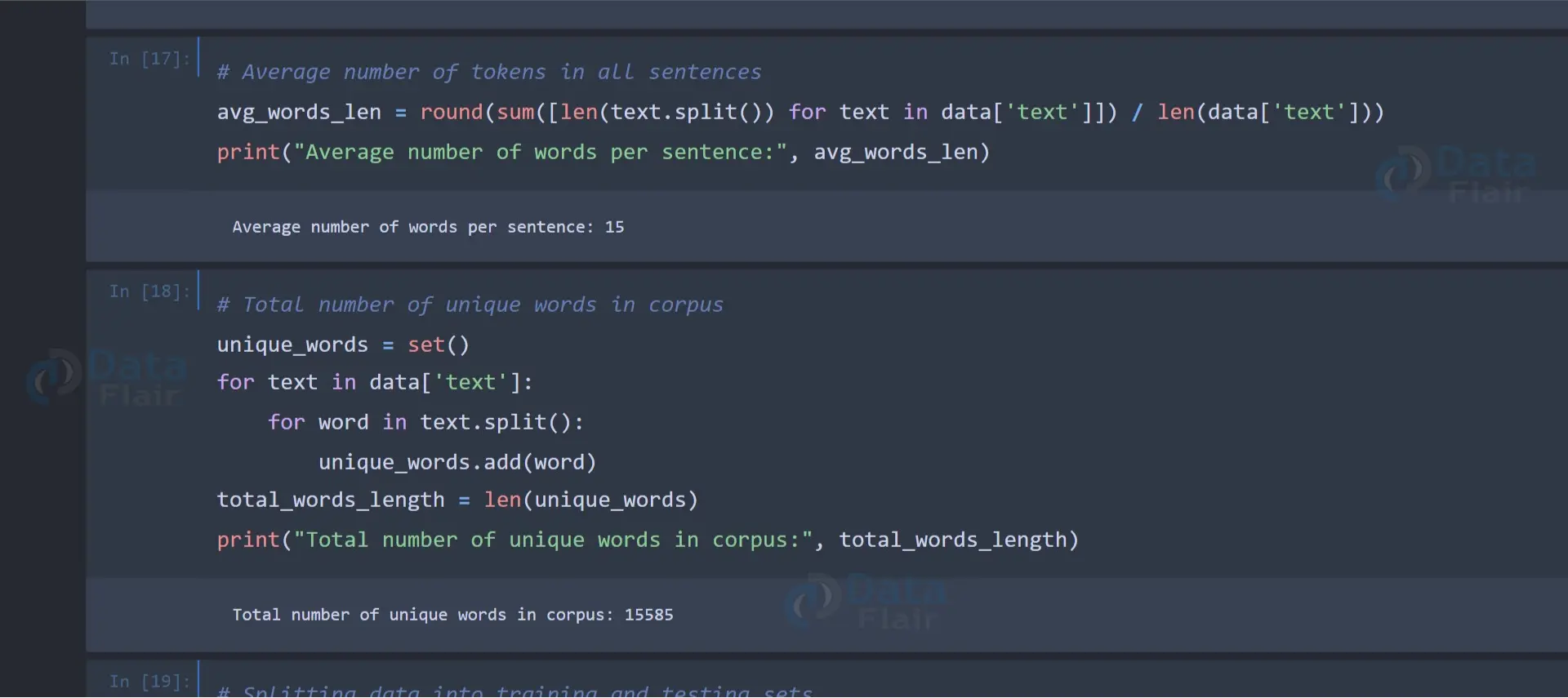
We calculate the average number of tokens (words) in all sentences and the total number of unique words in the corpus.
# Average number of tokens in all sentences
avg_words_len = round(sum([len(text.split()) for text in data['text']]) / len(data['text']))
print("Average number of words per sentence:", avg_words_len)
# Total number of unique words in corpus
unique_words = set()
for text in data['text']:
for word in text.split():
unique_words.add(word)
total_words_length = len(unique_words)
print("Total number of unique words in corpus:", total_words_length)Output:
Step 4: Splitting Data into Training and Testing Sets
We split the data into training and testing sets using scikit-learn’s `train_test_split` function. The data is divided into an 80-20 ratio, with 80% for training and 20% for testing.
from sklearn.model_selection import train_test_split
# Splitting data into training and testing sets
X, y = np.asarray(data['text']), np.asarray(data['label_enc'])
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42)
print("Training set shape:", X_train.shape, y_train.shape)
print("Testing set shape:", X_test.shape, y_test.shape)Step 5: Creating TF-IDF Vectors
We create TF-IDF vectors for the training and testing text data using scikit-learn’s `TfidfVectorizer`. TF-IDF (Term Frequency-Inverse Document Frequency) is a numerical representation of text data, capturing the importance of words within the documents.
from sklearn.feature_extraction.text import TfidfVectorizer # Creating TF-IDF vectors tv = TfidfVectorizer().fit(X_train) X_train_tv, X_test_tv = tv.transform(X_train), tv.transform(X_test)
Step 6: Training a Baseline Model (Naive Bayes)
We train a baseline model using the Naive Bayes classifier, implemented by scikit-learn’s `MultinomialNB`.
from sklearn.naive_bayes import MultinomialNB # Training a baseline model (Naive Bayes) model = MultinomialNB() model.fit(X_train_tv, y_train)
Step 7: Evaluating the Baseline Model
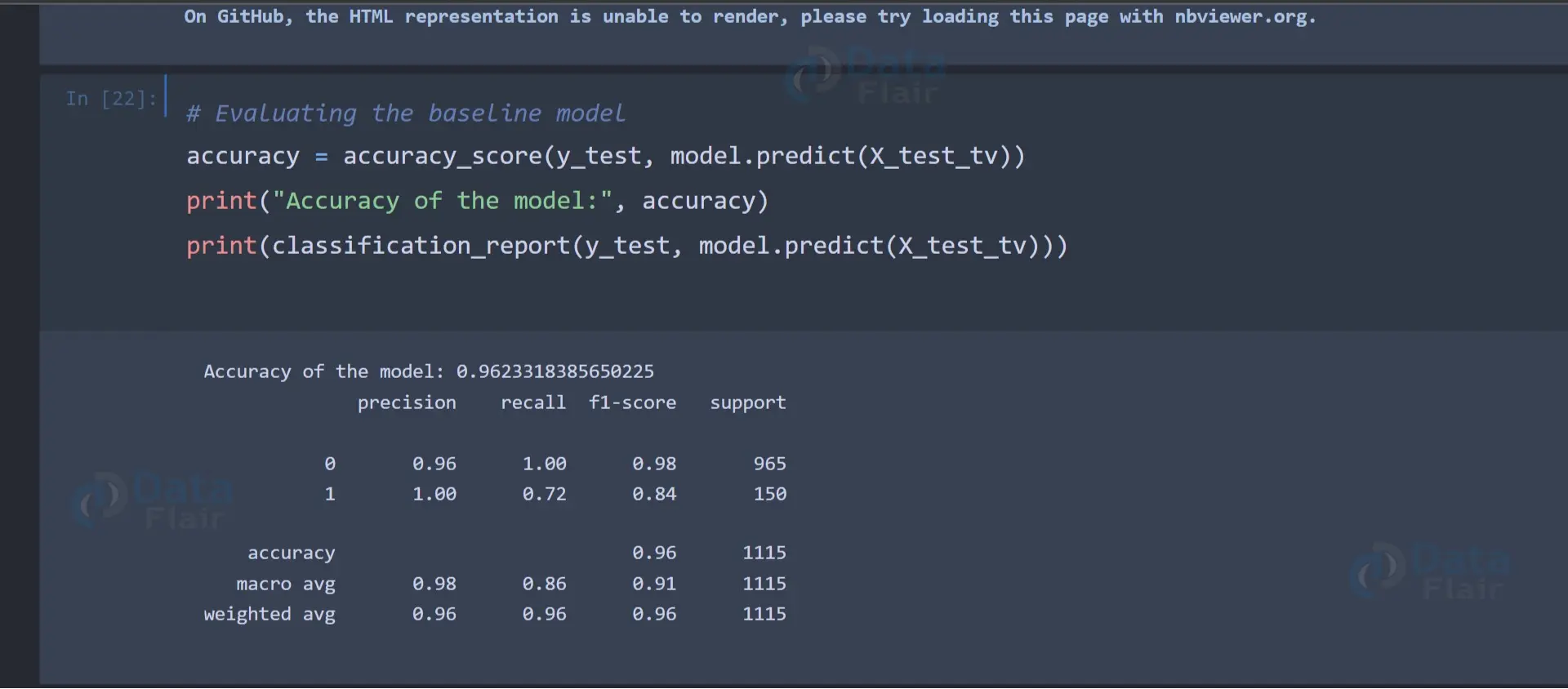
We evaluate the performance of the trained model using various metrics, including accuracy, precision, recall, and F1-score, provided by scikit-learn’s `classification_report` and `accuracy_score`.
Accuracy is 96%
from sklearn.metrics import classification_report, accuracy_score
# Evaluating the baseline model
accuracy = accuracy_score(y_test, model.predict(X_test_tv))
print("Accuracy of the model:", accuracy)
print(classification_report(y_test, model.predict(X_test_tv)))Output:
Step 8: Plotting the Confusion Matrix
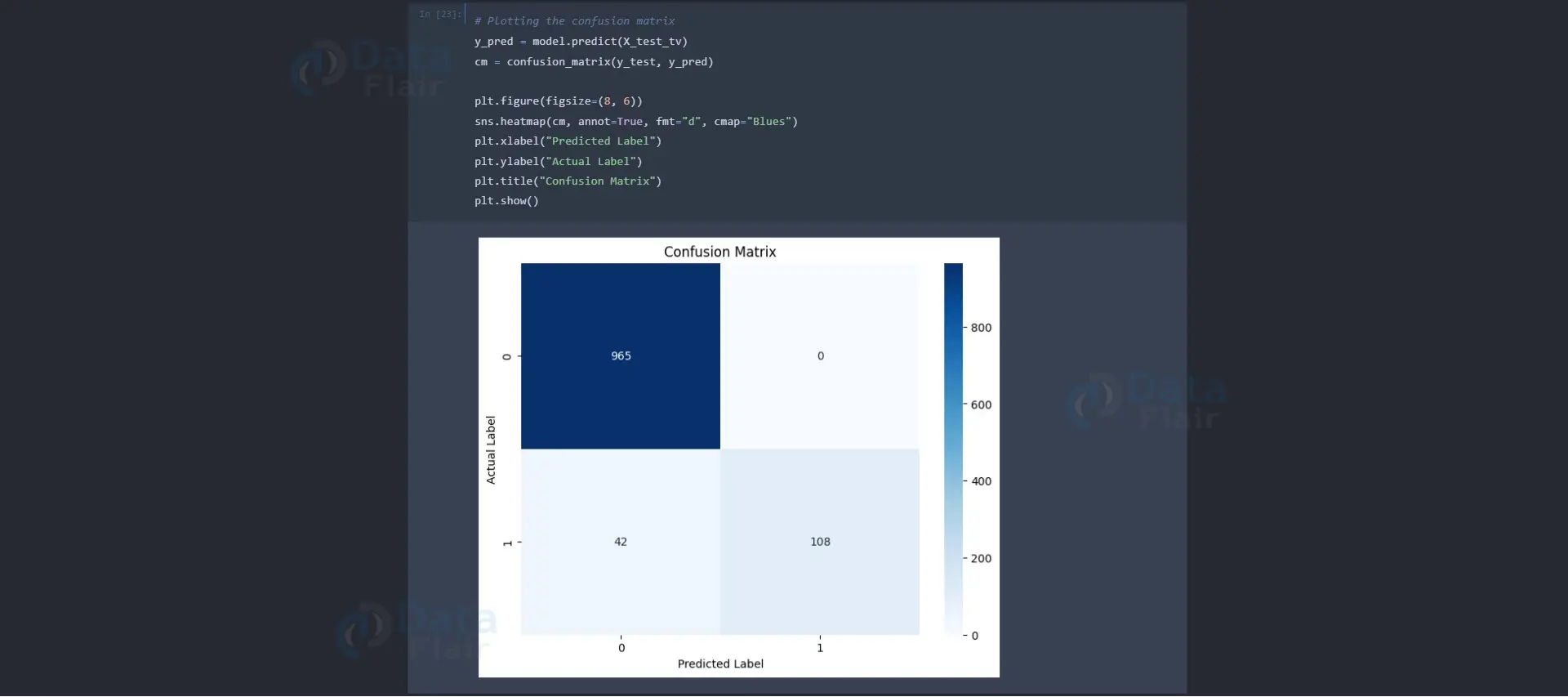
To visually analyze the model’s performance, we construct a confusion matrix heatmap using Seaborn’s heatmap.
from sklearn.metrics import confusion_matrix
# Plotting the confusion matrix
y_pred = model.predict(X_test_tv)
cm = confusion_matrix(y_test, y_pred)
plt.figure(figsize=(8, 6))
sns.heatmap(cm, annot=True, fmt="d", cmap="Blues")
plt.xlabel("Predicted Label")
plt.ylabel("Actual Label")
plt.title("Confusion Matrix")
plt.show()Output:
Summary
In conclusion, our “SMS Spam Detection Using Machine Learning” project successfully implements an efficient spam detection model, leveraging the Naive Bayes classifier and TF-IDF vectorization for high accuracy. We preprocess the data, visualize label distribution, and calculate word statistics for valuable insights. The model achieves commendable accuracy, precision, recall, and F1-score results. Using a confusion matrix heatmap, we visually represent the model’s performance in classifying ham and spam messages accurately.
This project eliminates unwanted spam messages, ensuring enhanced efficiency and security in digital communications. By employing machine learning techniques, we contribute to a safer SMS experience, shielding users from spam intrusion and fostering a trustworthy messaging environment as communication evolves.
You can check out more such machine learning projects on DataFlair.
We work very hard to provide you quality material
Could you take 15 seconds and share your happy experience on Google




