Book Recommendation System Machine Learning Project
Machine Learning courses with 100+ Real-time projects Start Now!!
With this Machine Learning Project, we build a book recommendation system. For this project, we will be using the KNearst Neighbor algorithm.
So, let’s build this system.
Book Recommendation System
When selling goods online, most businesses have their own recommendation system. However, almost all websites are not created with the customer in mind; businesses use them to force customers to purchase additional, irrelevant things. An individual user can select fascinating and practical things from a vast selection of products with the aid of a personalized recommendation system (PRS).
Customers now have a wide range of possibilities for products from eCommerce sites because of the expansion of the internet. It can be difficult for customers to locate the ideal products at the ideal moment. Users can find books, news, movies, music, online courses, and research articles using a personalized recommendation system.
Technological advances in areas like the internet of things (IoT), artificial intelligence (AI), quantum computing, etc., ushered in the fourth industrial revolution. The economic boom raises peoples’ purchasing power and their level of living. Due to their busy schedules and the COVID-19 pandemic, physical trips to stores and libraries have significantly decreased in recent years. Instead, e-marketplaces and e-libraries grew to be well-liked gathering spaces.
Users could find their favorite books from a wide selection thanks to e-book reading platforms and online shopping habits. Expert systems enable consumers to quickly and wisely choose among an unparalleled number of options. As a result, recommendation systems emerged to personalize users’ searches and provide the most advantageous outcomes from various possibilities. Amazon first suggested a personalized suggestion system, which helped to increase sales from $9.9 billion to $12.83 billion in 2019 (the second fiscal quarter), which was 29% more than the previous year.
A university library has thousands or millions of books. If readers only have a basic understanding of books, it is difficult to locate the books they require. It is also challenging for the library to utilize these books in paper form to their full potential. How can we make it easier for readers to find the books they want? And how can I use a library’s books to their fullest potential? These are formidable obstacles for a library.
Some academics have implemented recommender systems for the library. Recommender systems offer users individualized suggestions for goods or services. Collaborative filtering is a method that is frequently employed (CF). CF is a method of forecasting a user’s preferences based on the preferences of several users. It solely relies on the user’s prior behavior data, and it has been very successful in a variety of fields, including many large and prosperous websites like Amazon and others.
In order to create a book recommendation system, CF can be employed. In CF, the neighbor-based methods and latent factor models(LFM) are the two primary types. The LFM is a model-based CF approach that builds the data model using knowledge about the observed preferences. In order to deal with sparsity and forecast preferences that are not observed, it is built on the matrix factorization technique. LFM has more extensibility and forecast accuracy. By including biases and implicit feedback, SVD++ improves upon LFM’s accuracy. It benefits from both explicit and implicit input.
K-Nearest Neighbor
The K-Nearest Neighbor classifier compares a given test tuple with a group of training tuples that are comparable to it in order to recognize and classify patterns. One of the easiest techniques for resolving classification issues is the KNearest Neighbor (K-NN) algorithm, which frequently produces results that are competitive with other data mining techniques.
(1) Using similarity or distance to classify recommendations more quickly and accurately for the client.
(2) In order to produce a set of recommendations to the client more quickly, our recommendation engine gathers the clickstream data from the active users and matches it to a specific user’s group. Typically, the Euclidean distance between the training and test tuples is used by the K-Nearest Neighbor classifier.
A user and book pair (UI, bj) is inputted into the k Nearest Neighbors algorithm, which produces a forecast of the unknown rating for book bj from user UI. There are two distinct approaches to applying the k Nearest Neighbors algorithm to the goal of predicting book ratings. One is based on users, and the other is based on items. Users who have rated book bj are all examined by user-based kNN, and it identifies the k co-rated users who are most similar to UI. The ratings of these k users, known as the k nearest neighbors of ui, are used to forecast UI’s rating of book bj on the basis that similar users tend to rate books similarly.
In contrast, the item-based kNN first identifies the set of all the books that user UI has rated and then selects k books from this set that are most comparable to book bj (the k nearest neighbors, in this case, are these k most similar books). The ratings given by the user to these k closest neighbors are then utilized to forecast the user’s rating of the book bj. The item-based KNN’s underlying premise is that users have a tendency to evaluate comparable books similarly. Since the relationships between books are more static than the relationships between users, we chose to employ the item-based kNN.
Project Prerequisites
The requirement for this project is Python 3.6 on your computer. I have used Jupyter notebook for this project. You can use whatever you want.
The required modules for this project are –
- Numpy(1.22.4) – pip install numpy
- Sklearn(1.1.1) – pip install sklearn
- Pandas(1.5.0) – pip install pandas
That’s all we need for our project.
Book Recommendation System
We provide the dataset and source for the book recommendation system project. The csv file contains the name of different books and the rating of every book. Please download book recommendation system project and data from the following link: Book Recommendation Project
Steps to Implement
1. Import the modules and all the libraries we would require in this project. We will use Numpy, Pandas, and Seaborn in this project. We are also going to use sklearn in this project. So we have imported all the modules for that. We then read our dataset file and store it in a variable. We also imported sklearn because it contains the model we will use in the book recommendation system project.
import numpy as np#importing the numpy library
import pandas as pd#importing the pandas library
import seaborn as sns#importing the seaborn library
import matplotlib.pyplot as plt#importing the matplot library
dataframe=pd.read_csv('dataset.csv', error_bad_lines=False)#reading the dataset
df=df.drop(['Unnamed: 12'], axis=1)#dropping the unnamed column
df.head()#printing the dataframe
from sklearn.ensemble import RandomForestClassifier#importing the Random Forest classifier
from sklearn.model_selection import train_test_split#importing the Random Forest classifier
from sklearn.preprocessing import StandardScaler#importing the Standard Scalar
from sklearn.metrics import accuracy_score, f1_score,confusion_matrix,classification_report#importing the confusion matrix and classification report
2. Here, we are doing some pre-processing of the data. We are taking the top ten books according to ratings and then we are sorting it in descending order. We are also sorting our dataset according to the authors’ count and the average rating and we are storing it in the dataset.
top_ten_ratings=dataframe[dataframe['ratings_count']>1000000]#getting the rows with most ratings
top_ten_ratings=top_ten_ratings.sort_values(by='ratings_count', ascending=False).head(10)#priting the sorted data
dataframe=dataframe.sort_values('average_rating').reset_index()#sorting the dataframe according to average rating
dataframe=dataframe.iloc[4:]
dataframe.average_rating=dataframe.average_rating.astype(float)#changing the type to float
dataframe=dataframe.iloc[4:]
dataframe.num_pages=dataframe.num_pages.astype(float)#changing the type to float
3. Here we are copying our dataset into another variable we are extracting just the important features of the dataset. We take the rating and the languages and then we are concatenating both of these features and then we are storing it in another variable. At the end, we plot a bar chart of top 10 authors with most selling books.
dataframe2=dataframe.copy()
dataframe2.loc[(dataframe2['average_rating']>=0)&(dataframe2['average_rating']<=1),'rating between']="between 0 and 1"#getting the rows with average rating between 0 and 1
dataframe2.loc[(dataframe2['average_rating']>1)&(dataframe2['average_rating']<=2),'rating between']="between 1 and 2"#getting the rows with average rating between 1 and 2
dataframe2.loc[(dataframe2['average_rating']>2)&(dataframe2['average_rating']<=3),'rating between']="between 2 and 3"#getting the rows with average rating between 2 and 3
dataframe2.loc[(dataframe2['average_rating']>3)&(dataframe2['average_rating']<=4),'rating between']="between 3 and 4"#getting the rows with average rating between 3 and 4
dataframe2.loc[(dataframe2['average_rating']>4)&(dataframe2['average_rating']<=5),'rating between']="between 4 and 5"#getting the rows with average rating between 4 and 5
dataframe2.sort_values('average_rating')#sorting the dataframe
dataframe_rating=pd.get_dummies(dataframe2['rating between'])
dataframe_language=pd.get_dummies(dataframe2['language_code'])
feature_dataframe=pd.concat([dataframe_rating, dataframe_language, dataframe2['average_rating'], dataframe2['ratings_count']], axis=1)
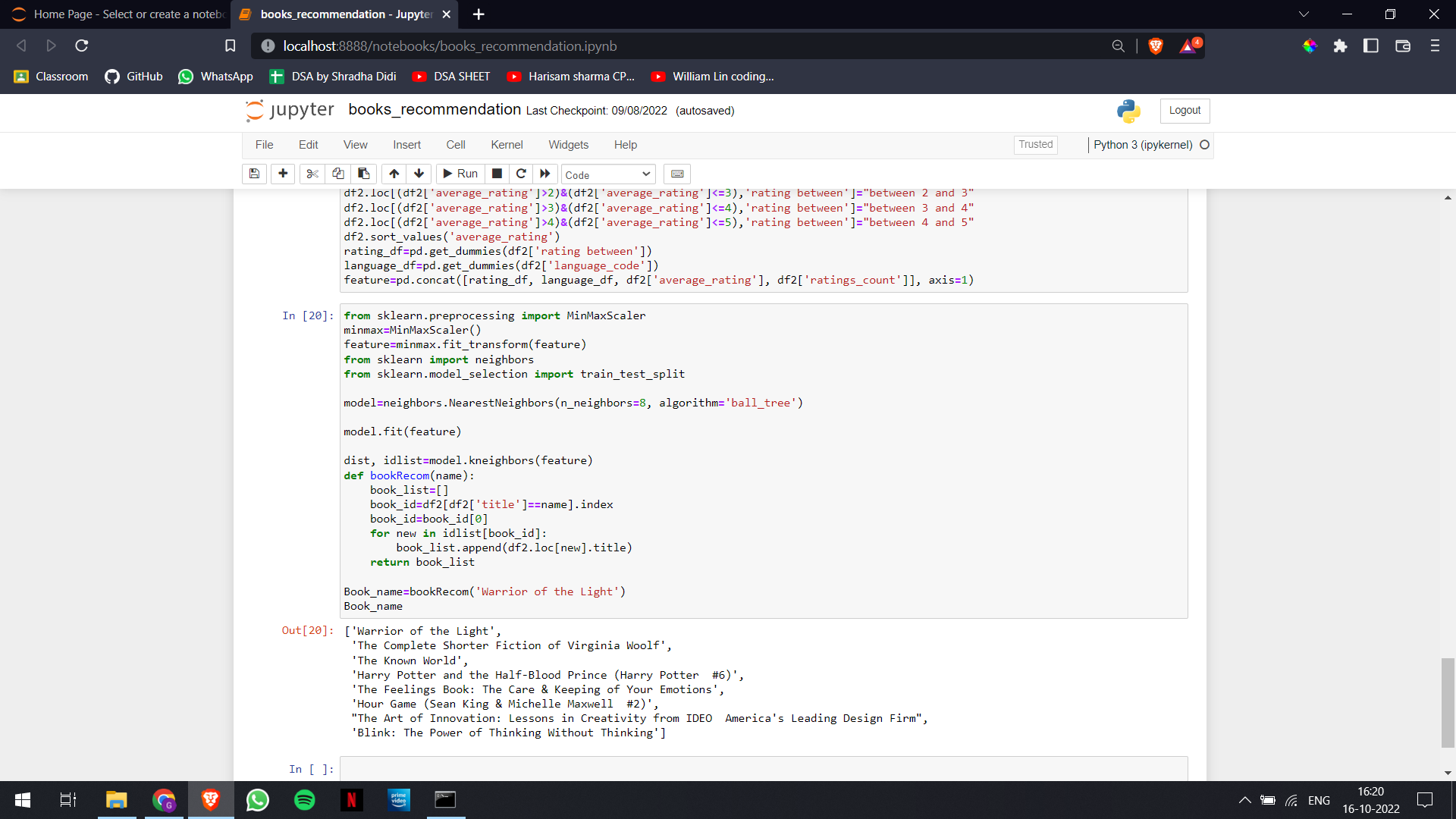
4. Here we are creating our Random Forest Classifier. First, we are creating our testing and training dataset. For this, we are using the train_test_split function of the sklearn. Then we import our NearestNeighbors model, and then we pass our testing dataset into it. We are using the ‘ball_tree’ algorithm in our model. Then we are creating a function for bookRecom which will take the name of the book and then it will give us the suggestion for that book.
from sklearn.preprocessing import MinMaxScaler#importing the min max scalar
minmax=MinMaxScaler()#creating instance of min max scalar
feature=minmax.fit_transform(feature) #fitting the feature to instance
from sklearn.model_selection import train_test_split#importing the library for splitting the dataset
model=neighbors.NearestNeighbors(n_neighbors=8, algorithm='ball_tree')#creating the model
model.fit(feature) #fitting the model
dist, book_id=model.kneighbors(feature)#getting the id of the book
def recommend_book(name):#defining function for book recom
list=[]#creating a book list
id=dataframe2[dataframe2['title']==name].index
id=id[0]
for books in book_id[id]:
list.append(dataframe2.loc[books].title)
return list
result=recommend_book('Warrior of the Light')#finding a book suggestion
result#printing the result
Summary
A book recommendation system suggests books to users based on their interests, past reads, and ratings. It works just like the Amazon or Goodreads suggestion engine. This project helps users find new books to read and improves their experience on book websites or apps. It uses machine learning techniques like collaborative filtering, content-based filtering, or hybrid models.
In this Machine Learning project, we built a book recommendation system. For this project, we used the KNearest Neighbor algorithm. We hope you have learned something new in this project.
Your opinion matters
Please write your valuable feedback about DataFlair on Google





Hi there, the link to the dataset is not working. Could you please provide me with an updated link so that I can start working on the project? Thank you
data base file not downloading error showing
please send data base file
could you please share your colab notebook
Your link for Book Recommendation Project is not working. Please make it active or provide another source of data!
The download link is now working, you can download the project code.