Apache Flink Use Case Tutorial – Crime Data Analysis Part I
Free Flink course with real-time projects Start Now!!
This Apache Flink use case tutorial will help you to understand the use of DataSet APIs provided by Apache Flink. In this blog, we will use various Apache Flink APIs like readCsvFile, include fields, groupBy, reduced group, etc. to analyze the crime report use-case.
In our previous blog, we discussed how to set up Apache Flink environment in eclipse IDE and run wordcount program.
Platform
- Operating system: Windows / Linux / Mac
- Apache Flink
- Java 7.x or higher
- IDE: Eclipse
Steps to make project and Add dependencies
1. Create a new java project
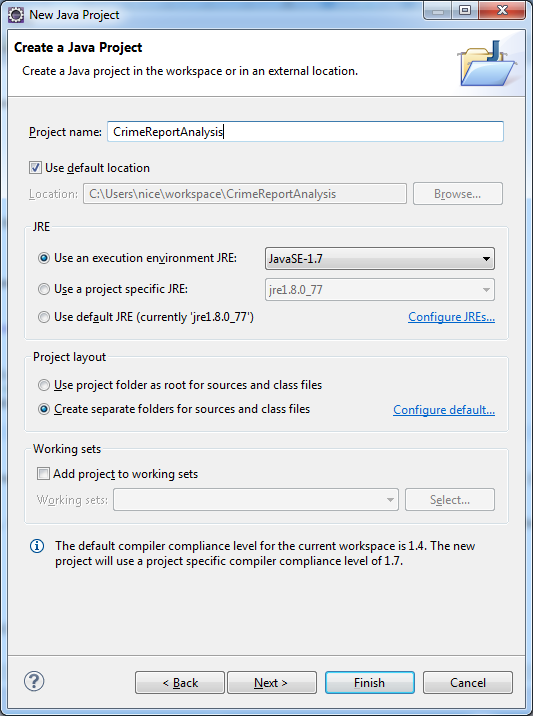
Apache Flink Use Case Tutorial- Make project
Add the following Jars in the build path. You can find the jar files in the lib directory of Flink home:
flink-dist_2.11-1.0.3.jar
flink-python_2.11-1.0.3.jar
log4j-1.2.17.jar
slf4j-log4j12-1.7.7.jar
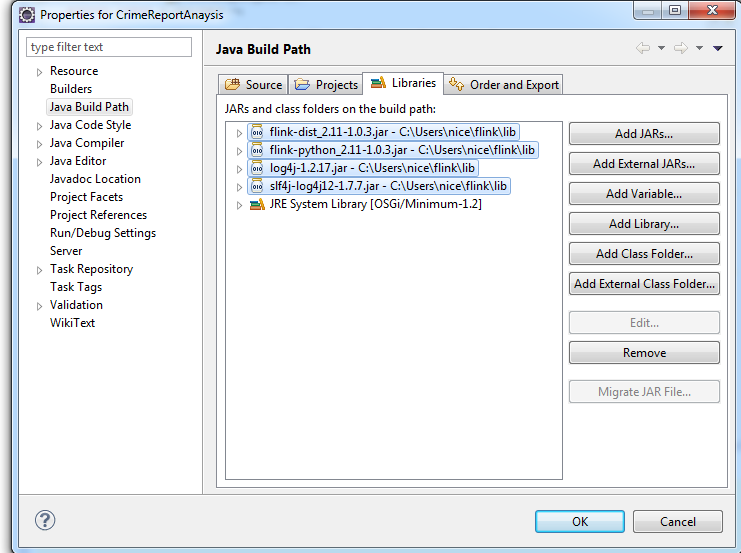
Apache Flink Use Case Tutorial- dependency jar
Sample Data
Following is the sample dataset for the Apache Flink use case:
[php]
cdatetime,address,district,beat,grid,crimedescr,ucr_ncic_code,latitude,longitude
1/1/2006 0:00,3108 OCCIDENTAL DR,3,3C,1115,484 PC PETTY THEFT/INSIDE,2404,38.47350069,-121.4901858
1/1/2006 0:00,4 PALEN CT,2,2A,212,459 PC BURGLARY BUSINESS,2299,38.47350069,-121.4901858
1/1/2006 0:00,3547 P ST,3,3C,853,484 PC PETTY THEFT/INSIDE,2404,38.47350069,-121.4901858
1/1/2006 0:00,3421,AUBURN BLVD,2,2A,508 459 PC BURGLARY BUSINESS,2299,38.47350069,-121.4901858
1/1/2006 0:00,6351 DRIFTWOOD ST,4,4C,1261,SUSP PERS-NO CRIME – I RPT,7000,38.47350069,-121.4901858
1/1/2006 0:01,7001 EAST PKWY,6,6C ,1427,503 PC EMBEZZLEMENT,2799,38.51436734,-121.3854286
1/1/2006 0:01,918 LAKE FRONT DR,4,4C,1294,TELEPEST -I RPT,7000,38.47948616,-121.5215057
1/1/2006 0:01,4851 KOKOMO DR,1,1A ,123,487(A) GRAND THEFT-INSIDE,2308,38.65994218,-121.5259008
1/1/2006 0:01,2377 OAK HARBOUR DR,1,1B ,440,653M(A) PC OBSCENE/THREAT CALL,5309,38.60893745,-121.5187927
1/1/2006 0:01,1823 P ST,3,3B ,766,484 PETTY THEFT/LICENSE PLATE,2399,38.57084621,-121.484429
1/1/2006 0:01,1100 14TH ST,3,3M,745,FOUND PROPERTY – I RPT,7000,38.57815667,-121.4876958
1/1/2006 0:01,3301 ARENA BLVD,1,1A,303,530.5 PC USE PERSONAL ID INFO,2604,38.64378844,-121.5341593
1/1/2006 0:01,1088 PREGO WAY,1,1B,404,530.5 PC USE PERSONAL ID INFO,2604,38.62798948,-121.4857344
1/1/2006 0:01,3259 SPINNING ROD WAY,1,1B,475,484J PC PUBLISH CARD INFO,2605,38.61153542,-121.5370613
1/1/2006 0:01,1010 J ST,3,3M,744,THREATS – I RPT,7000,38.57999251,-121.4930384
1/1/2006 0:01,400 BANNON ST,3,3A,704,530 PC FALSE PERS. REC PROP,2604,38.59540732,-121.4978798
[/php]
The above data is the crime record which has nine fields. The problem will be solved using following two fields- crimedescr and ucr_ncic_code. We will count the occurrences of a particular crime. To analyze the data we will include these two fields. You can download the data file from this link.
Apache Flink Use Case Tutorial – Crime Data Analysis
In this section on Apache Spark Use case tutorial, we will discuss two different problem statement with their solution through Flink program and output.
5.1. Problem Statement – 1
We will Analyze the Crime Record data by using Apache Flink. We will count the occurrence of a particular crime. For this KPI we will use crimedescr and ucr_ncic_code fields available in the dataset.
We will count the occurrence of the group(crimedescr, ucr_ncic_code) as same code is assigned to more than one crime.
a. Apache-Flink program
[php]
import org.apache.flink.api.common.functions.GroupReduceFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.util.Collector;
public class CrimeReport{
public static void main(String[] args) throws Exception {
// obtain an execution environment
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
DataSet<Tuple2<String, String>> rawdata =
env.readCsvFile(“E:\\CrimeReport.csv”).includeFields(“0000011”).ignoreFirstLine()
.types(String.class, String.class);
// group by crimerecord and ucr_code and count number of records per group
rawdata.groupBy(0,1).reduceGroup(new CrimeCounter())
// print the result
.print();
}
public static class CrimeCounter implements GroupReduceFunction<Tuple2<String ,String>, Tuple3<String ,String, Integer>> {
@Override
public void reduce(Iterable<Tuple2<String, String>> records, Collector<Tuple3<String, String, Integer>> out) throws Exception {
String crimerecord = null;
String ucr_code = null;
int cnt = 0;
// count number of tuples
for(Tuple2<String, String> m : records) {
crimerecord = m.f0;
ucr_code = m.f1;
// increase count
cnt++;
}
// emit crimerecord, ucr_code, and count
out.collect(new Tuple3<>(crimerecord, ucr_code, cnt));
}
}
}
[/php]
In above program, data is read using readCsvFile() method, which is used to read CSV files in flink. As we want just specific fields of CSV file we are including them using includeFields() method. ignoreFirstLine() method will ignore the first line as it is the name of columns.
Now in this Apache Flink use case, there is no need to call map operation rather we are using groupBy() operation to group both the fields for further operation. Now reduceGroup() will simply count the occurrences of each group (each crime). It is emitting the result as crime record,ucr_id, Count.
b. Output
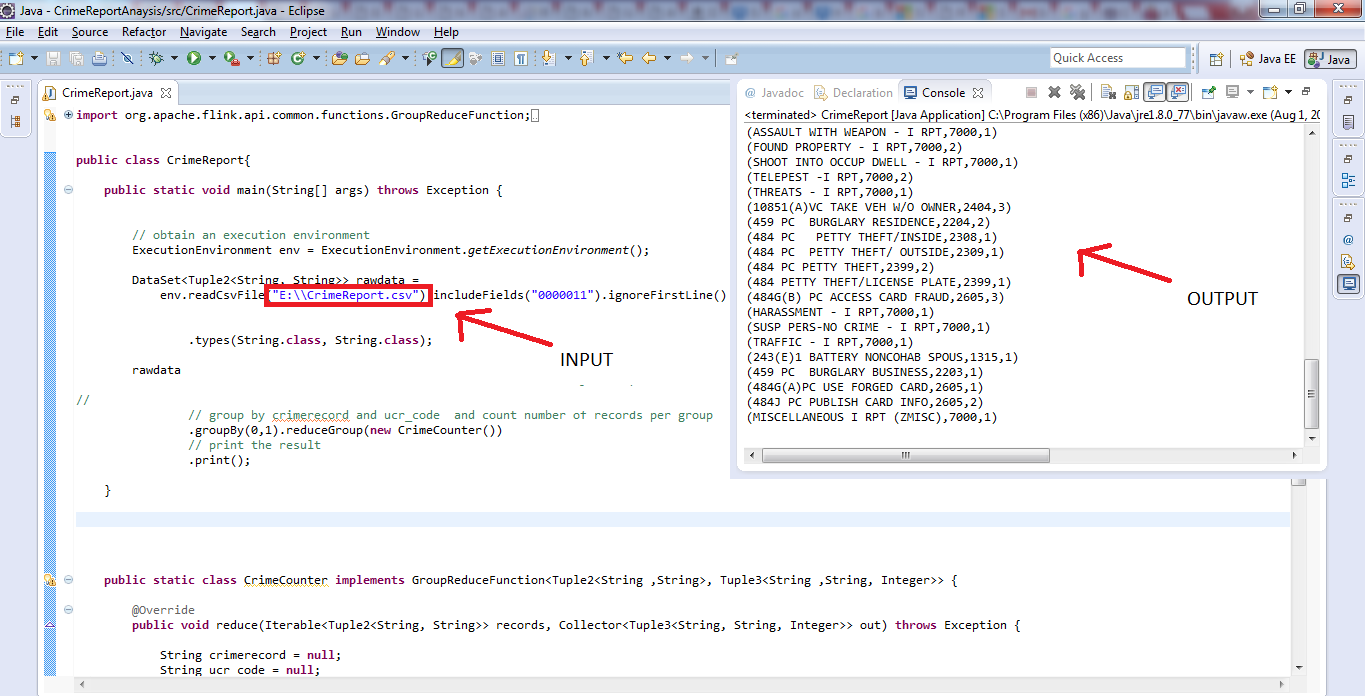
Apache Flink Use Case Tutorial- output
484 PC PETTY THEFT/INSIDE,2404,2
459 PC BURGLARY BUSINESS,2299,2
SUSP PERS-NO CRIME – I RPT,7000,1
5.2. Problem Statement – 2
In this problem, we will analyze the data and find out Distribution of the number of crimes happened per day and sort them in descending order for each month.
a. Apache Flink Program
[php]
import java.text.SimpleDateFormat;
import java.util.Calendar;
import java.util.Date;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.operators.Order;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.tuple.Tuple1;
import org.apache.flink.api.java.tuple.Tuple3;
public class DailyCrimeAnalysis {
public static void main(String[] args) throws Exception {
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
DataSet < Tuple1 < String >> rawdata = env.readCsvFile(“E:\\SacramentocrimeJanuary2006.csv”).includeFields(“1000000”).ignoreFirstLine()
.types(String.class);
rawdata.map(new DateExtractor()) //map data according to MM/dd/YYYY
.groupBy(0) //group according to date
.sum(2) //sum the count on the field 2
.groupBy(1)// group the data according to field 1 that is month/year
.sortGroup(2, Order.DESCENDING).first(50) // arrange the data in decreasing order
.writeAsCsv(“E://Output5569”);
env.execute();
}
public static class DateExtractor implements MapFunction < Tuple1 < String > , Tuple3 < String, String, Integer >> {
SimpleDateFormat formatter = new SimpleDateFormat(“MM/dd/yyyy”);
SimpleDateFormat formatter2 = new SimpleDateFormat(“MM/dd/yyyy HH:mm”);
@Override
public Tuple3 < String, String, Integer > map(Tuple1 < String > time) throws Exception {
Date date = formatter2.parse(time.f0);
Calendar cal = Calendar.getInstance();
cal.setTime(date);
int month = cal.get(Calendar.MONTH) + 1;
int year = cal.get(Calendar.YEAR);
return new Tuple3 < > (formatter.format(date), “” + month + “/” + year, 1);
}
}
}
[/php]
b. Output

Apache Flink Use Case Tutorial- output v2
Did we exceed your expectations?
If Yes, share your valuable feedback on Google





Great post to understand Flink APIs with Flink project.
Nice article to help in understanding Flink implementation and API usage.
Very well explained apache flink use case in real time. Could you please share more blogs on flink to learn with?
Nice blog on flink. Please share more usecase with stream processing.