Apache Flink Ecosystem Components Tutorial | Learn Flink
Free Flink course with real-time projects Start Now!!
This Apache Flink tutorial will help you in understanding what is Apache Flink along with Flink definition. Also, it explains the introduction to Apache Flink Ecosystem Components.
Moreover, we will see various Flink APIs and libraries like Flink DataSet API, DataStream API of Flink, Flink Gelly API, CEP and Table API.
Apache Flink is an open source data processing framework. At its core, it is a Stream Processing engine which gives fast, robust, efficient, and consistent handling of real-time data. It converts the near real-time processing of Streaming data in Spark to live data processing.
So, let’s start the Apache Flink Ecosystem tutorial.
Apache Flink Ecosystem – Introduction
Apache Flink is an open source distributed data stream processor. Flink provides fast, efficient, consistent and robust handling of massive streams of events that can handle both batch processing and stream processing.
Flink is the first and only open source framework that delivers-
- The throughput of millions of events per second in moderate clusters.
- The sub-second latency of milliseconds.
- Exactly once semantics for application state and delivery with supported sources and sinks.
- An accurate result through its support for event time.
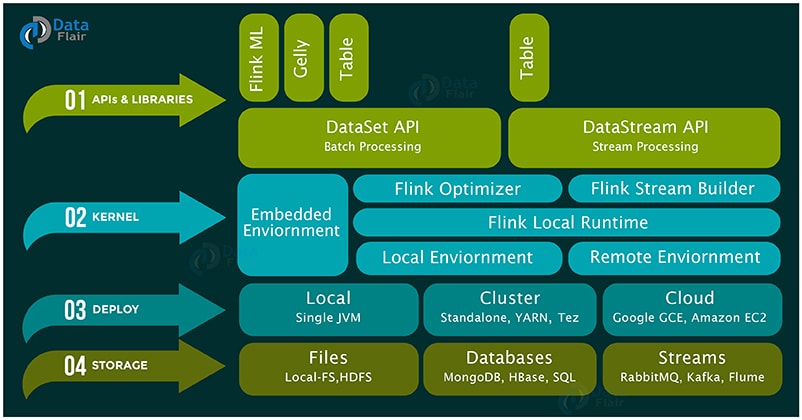
Apache Flink Ecosystem Components
Refer this guide to learn about the Major differences between Flink vs Spark vs Hadoop.
There are different layers in the Apache Flink Ecosystem diagram, let’s discuss these layers in detail-
i. Storage / Streaming
Flink is only a computation engine that does not have any storage system. It reads and writes data from different storage systems as well as can consume data from streaming systems. Below are some of the storage/streaming systems from which Flink can read write data:
- HDFS – Hadoop Distributed File System
- Local-FS – Local File System
- HBase – NoSQL Database in the Hadoop ecosystem
- MongoDB – NoSQL Database
- RDBMS – Any relational database
- S3 – Simple Storage Service from Amazon
- Kafka – Distributed Messaging Queue
- Flume – Data Collection and Aggregation Tool
- RabbitMQ – Messaging Queue
ii. Deployment
Deployment/resource management is the second layer in Flink ecosystem. One can deploy Flink in the following modes:
- Local mode – On a single node, in single JVM
- Cluster – On a multi-node cluster, with following resource manager
- Standalone – This is the default resource manager of Flink.
- YARN – This is a very popular resource manager, it is part of Hadoop, introduced in Hadoop 2.x
- Mesos – This is a generalized resource manager.
- Cloud – on Amazon or Google cloud.
iii. Flink Kernel
The third layer is Runtime – the Distributed Streaming Dataflow, which is also called as the kernel of Apache Flink. This layer provides distributed processing, fault tolerance, reliability, native iterative processing capability, etc.
iv. APIs and Library
These Flink APIs and Libraries provide a diverse capability to Flink as listed below:
a. DataSet API
This API handles the data at the rest that is generated from various sources, for example by reading text or CSV files or from local collections and allows user to implement transformations like mapping, filtering, joining, grouping, etc.
Post which output is returned via sinks to write data to text or CSV files or to return the output to the client. It is mainly for distributed processing. It also executes the batch application at streaming runtime.
Some best practices to follow while working in DataSet API are:
- print() – Use it for fast printing a dataset
- collect() – Use for fast retrieval of dataset
- name() – Use it on an operator for easy searching in logs
b. DataStream API
It handles transformations on a continuous stream of the data. To process live data stream it provides various operations like filtering, updating states, defining windows, aggregating, etc.
It can consume the data from a various streaming source like message queues, socket streams, files etc and can return the data via Sinks for writing data to files or standard output like command line terminal. It supports both Java and Scala.
Some best practices to follow while working in DataStream API are as follows:
- Use print() to print fastly a data stream.
- Use env.fromelements(..) or env.fromCollection(..) for getting data stream to start working with.
Now let’s discuss some DSL (Domain Specific Library) Tools
c. Table API
Table API enables users to perform ad-hoc analysis through languages like SQL for relational stream and batch processing. It can be embedded in DataSet and DataStream APIs of Flink in both Java and Scala.
Actually, it allows users to run SQL queries on the top of Flink that saves them from writing complex code for data processing.
The key concept of the Table API is a Table that represents a table with relational schema. Using DataSet or DataStream one can create Tables. It converts into a DataSet or DataStream or registers in a table catalog using a TableEnvironment. Registered tables can be queried with regular SQL queries.
A Table is always bound to a specific TableEnvironment. It is not possible to combine Tables of different TableEnvironments.
Different Table API operators are select, filter/where, groupBy, join, LeftOuterJoin, RightOuterJoin, Union, Intersect, etc.
d. Gelly
It is the graph processing engine which allows users to run operations for creating, transforming and processing the graph. It also provides the library of the algorithm to simplify the development of graph applications.
Gelly can transform and modify graph using high-level functions that are similar to those provided by batch processing APIs. Its APIs are available in both Java and Scala. Scala methods are implemented as wrappers on top of Java operations.
A dataset of vertices and edges represents a graph in Gelly. The unique ID of DataSet defines a vertex and a value while source ID defines an edge, target ID, and value.
Transformations and Utilities are the methods of Graph class that include transformations, graph metrics, mutations and neighborhood aggregations.
It is possible to perform end to end data analysis through Gelly on a single system. Gelly API can be seamlessly mixed with DataSet Flink API for implementing applications that use both record based and graph based analysis.
e. FlinkML – Machine Learning for Flink
It is the machine learning library in Scala, which provides intuitive APIs and efficient algorithm to handle machine learning applications in Apache Flink.
So, as we know machine learning algorithms are iterative in nature, Flink provides native support for iterative algorithm to handle the same quite effectively and efficiently.
FlinkML supports Supervised learning (Optimization framework, Multiple linear regression and SVM algorithms) and Unsupervised learning (k-Nearest Neighbors join) along with Data Preprocessing.
One of the key concepts of FlinkML is its scikit-learn inspired pipelining mechanism that allows building complex data analysis pipelines.
f. FlinkCEP – Complex event processing for Flink
FlinkCEP allows easy detection of complex event patterns in streams of data that is useful in finding matching sequences to get insights of data. For comparing and finding matching events, it is necessary for the data stream to implement equals() and hashcode() methods.
The pattern API easily define the complex event patterns. So, the patterns have different states in which the user can define conditions for events. Various pattern operations include begin, next, followed by, within etc. that can be in both Java and Scala.
Nowadays, financial applications such as stock market trend and credit card fraud detection make use of CEP. It is also useful in RFID-based tracking and monitoring.
Now, for example, It detects thefts in a warehouse where items are not properly checked out. It can also find its usage in detecting network intrusion by specifying patterns of suspicious user behavior.
To learn about more Flink use cases, refer Flink use case tutorial to get real-time use cases of Apache Flink and how industries are using Flink for their various purposes.
So, this was all in Apache Flink Ecosystem. Hope you like our explanation.
Conclusion – Flink Ecosystem
Did you like our efforts? If Yes, please give DataFlair 5 Stars on Google




