PyTorch RNN
Machine Learning courses with 100+ Real-time projects Start Now!!
We have all wondered how Google knows what you want to search for even before you complete the sentence. Or how the big companies know the people’s opinions about something only with some reviews and social media posts. Or how do the translators work? The answer is Recurrent Neural Networks. Recurrent Neural Network, often abbreviated as RNN, is widely used in sentence completion, sentiment analysis and translation tasks. It is the go-to algorithm for problems involving sequences. Let’s learn more about PyTorch RNN.
What is a Recurrent Neural Network?
The recurrent neural networks take in an input and train themselves in such a way that they can predict the next state of the network. As we know, a neural network has three layers – the input, output and hidden layer. The hidden layers take in the previous state along with the current state as its input. So, the present state depends on the current and previous input.
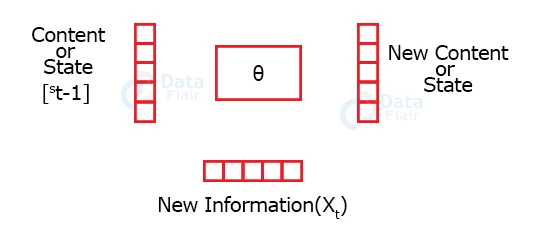
Why not Feed Forward neural Network?
Feed Forward networks cannot relate two subsequent outputs. For example, suppose we have a classification task of differentiating cats from dogs. In that case, the Feed Forward network simply learns to understand the information about the present data and has nothing to do with the previous predictions. However, when we write a sentence, it has a structure that makes sense. This structure depends on the last word we wrote; this is where the Feed Forward network fails.
Working of a Recurrent Neural Network:
We aim to map a sequence to a vector called encoding, and then decode it. To understand the working of an RNN, let’s take an example. Suppose we have a set of sentences.
<start> I have a blue car </end>
<start> We live in a blue house </end>
<start> I have a car battery. </end>
To make things simple, let’s assume the current word depends only on the previous word and not on the words before that.
When we pass the above sentences as input, the recurrent neural network computes the probability of a word appearing when given the previous word.
All the words in the above example are: {I, have, a, blue, car, we, live, in, house, and battery.}
The probability of a word appearing when given the previous word is represented in the table below.
Probability of appearing next when the last word is known.
| Last word | I | have | a | blue | car | we | live | in | house | battery | <end> |
| <start> | 2/3 | 0 | 0 | 0 | 0 | 1/3 | 0 | 0 | 0 | 0 | 0 |
| I | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| have | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| a | 0 | 0 | 0 | 2/3 | 1/3 | 0 | 0 | 0 | 0 | 0 | 0 |
| blue | 0 | 0 | 0 | 0 | 1/2 | 0 | 0 | 0 | 1/2 | 0 | 0 |
| car | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1/2 | 1/2 |
| we | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
| live | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| in | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| house | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| battery | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
This was a simple example; therefore, most blocks have 0. However, in practical applications, most blocks are filled with some number representing the probability of a word appearing next. Also, in practical applications, these probabilities depend on the previous word and the words before it. Therefore, instead of words, we use the term state.
Types of Recurrent Neural Networks (RNN):
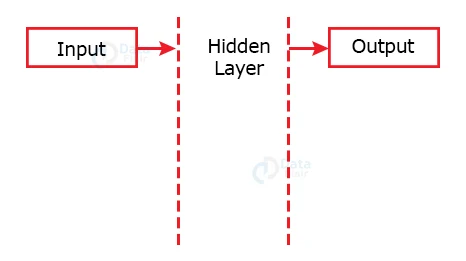
a. One to One
The Recurrent Neural Networks having only one input and one output are called One to One neural networks.
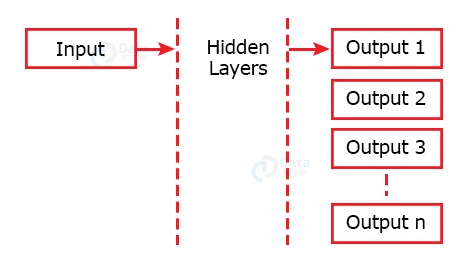
b. One to Many
Recurrent Neural Networks having one input and multiple outputs are said to be One to Many recurrent neural networks. These kinds of networks are used for applications requiring different aspects of a single input, such as image captioning.
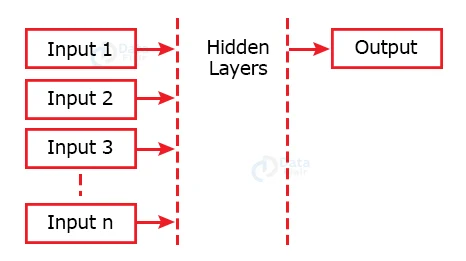
c. Many to One
When there are many inputs and one output is to be obtained, the recurrent network is called Many to One. In use cases such as sentiment analysis, several input parameters are given, and only one output is desired, which learns the characteristics of the input given and produces a single output.
d. Many to Many
A Many to Many Recurrent Neural Networks may have any number of inputs and outputs. These inputs and outputs can be equal in number (Equal Unit Size), and they may also be unequal (Unequal Unit Size).
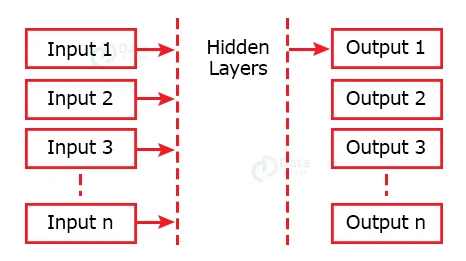
Problems with RNN and their solution:
RNN depends on previous states; therefore, adjusting to extremely new information may become difficult. For example, in the above example, when the word ‘battery’ appears, the sentence ends, i.e. the probability of <end> appearing after battery is 1. Now, if some new sentence has any other word after battery, it would be challenging for our model to acknowledge it.
Basically, two types of problems can happen in such cases. The error either explodes or diminishes, with the new sentence having very little effect on our model.
When the error explodes, we can rectify it by clipping the gradient after it crosses a certain threshold. For diminishing gradients, we can use LSTM.
LSTMs are a special kind of neural network with a forget gate, input gate, output gate, memory cell etc. These gates are responsible for understanding the relevant information of the previous states and treating the new input accordingly.
Implementing RNN using PyTorch:
import torch
import torch.nn as nn
class RRNet(nn.Module):
def __init__(self,input_dim,hidden_dim):
super(RRNet,self).__init__()
self.rnn_model=nn.RNN(input_dim,hidden_dim,1)
def forward(self,data):
return self.rnn_model(data)
rrnet=RRNet(5,1)
#We have passed the feature size and dimension of the hidden layer respectively
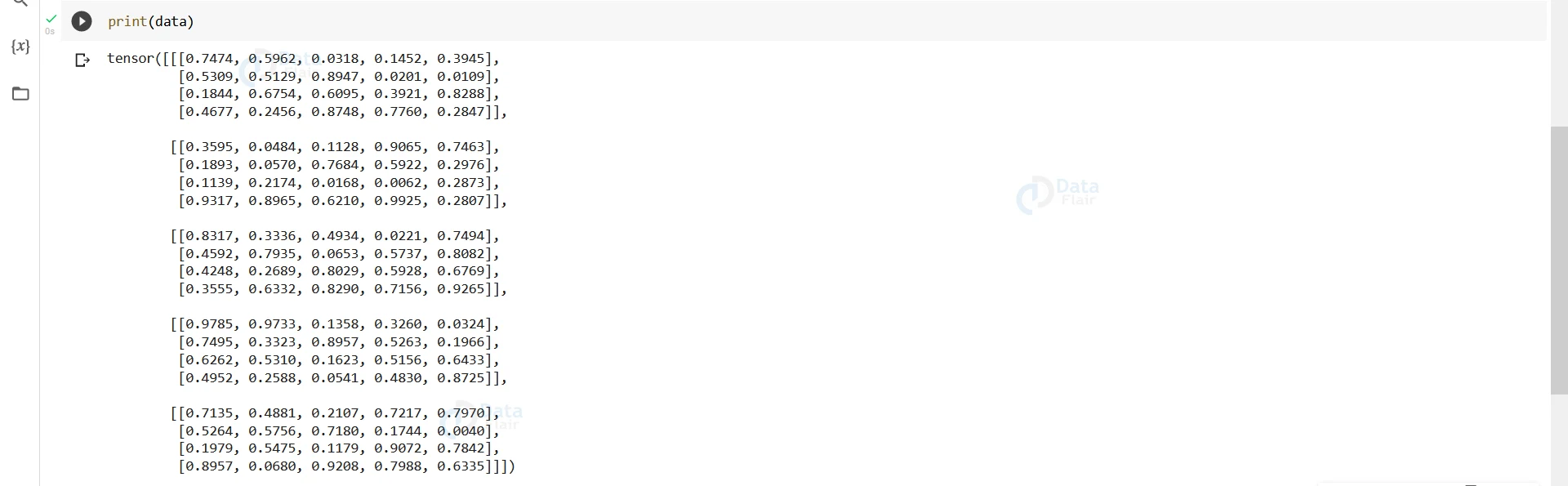
data=torch.rand(5,4,5)
#For the sake of demonstration we have cerated a random tensor
print(data)
Output:
result,h_s=rrnet.forward(data) result
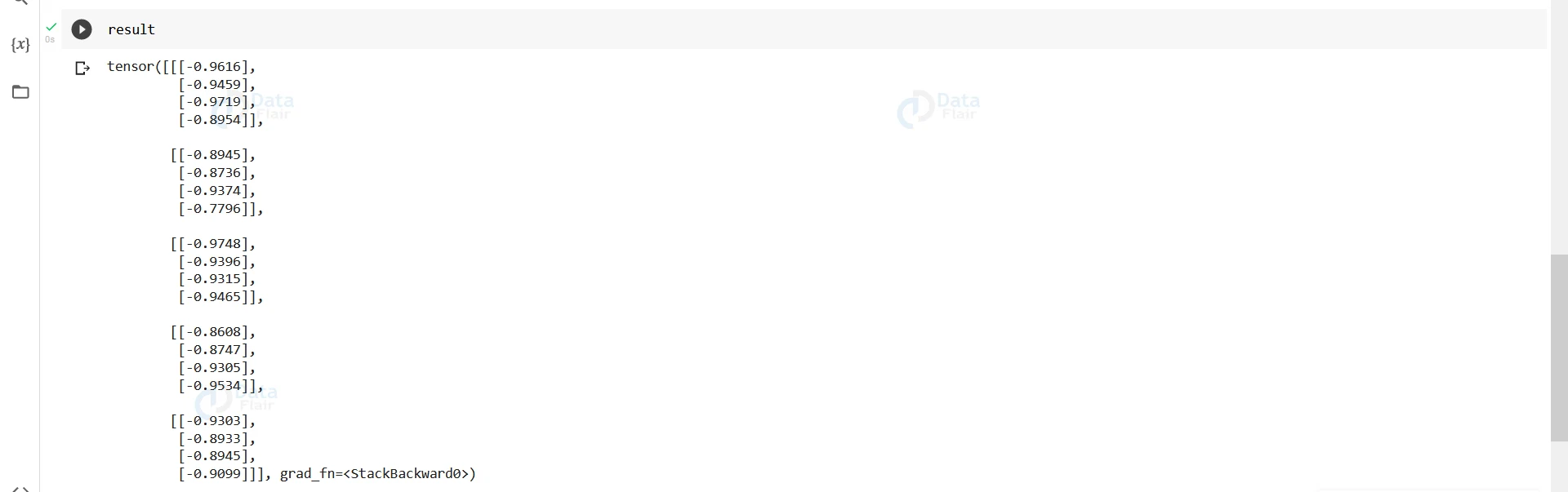
h_s

Summary
Recurrent Neural Networks can be used in every case where the previous state of the data plays a significant role in predicting the next word or state. PyTorch has an RNN module that helps us design such models conveniently. However, in some cases, the error may either vanish or explode. It can be resolved using several methods, such as gradient clipping, error truncating and LSTM.
Did you know we work 24x7 to provide you best tutorials
Please encourage us - write a review on Google




