Apache HCatalog Tutorial For Beginners
Today, we are introducing a new journey towards Apache HCatalog. In this HCatalog tutorial, we are providing a guide of the ever-useful HCatalog storage management layer for Hadoop.
Also, we will explain what it does as well as how it works. Moreover, in this HCatalog Tutorial, we will also discuss HCatalog architecture along with its benefits to get it well. So, get ready to dive into the HCatalog Tutorial.
So, let’s start the Apache HCatalog.
What is HCatalog?
Basically, a table as well as a storage management layer for Hadoop is what we call HCatalog. Its main function is that it enables users with different data processing tools, for example, Pig, MapReduce to make the read and write data easily on the grid.
In addition, its abstraction presents users with a relational view of data in the Hadoop distributed file system (HDFS). Also, it makes sure that where or in what format their data is stored like the RCFile format, text files, SequenceFiles, or ORC files, users need not worry about.
Hence we can say in any format for which a SerDe (serializer-deserializer) can be written, HCatalog supports reading and writing files.
Moreover, it supports RCFile, CSV, JSON, and SequenceFile, and ORC file formats, by default. Although, make sure to provide the InputFormat, OutputFormat, and SerDe, to use a custom format.
Intended Audience for HCatalog Tutorial
- For the professionals who want to make a career in Big Data Analytics using Hadoop Framework, HCatalog tutorial is specially designed for them.
- Also, ETL developers, as well as analytics professionals, may go through this tutorial for good effect.
Prerequisites to HCatalog
The Apache Hadoop ecosystem includes HCatalog, which offers a table and storage management layer for information stored in the Hadoop Distributed File System (HDFS). You require a functional Hadoop cluster with HDFS installed, Hive installed as the metadata store, Java Development Kit (JDK), access to HDFS, HCatalog server and client libraries, and Apache Thrift for serialisation in order to use HCatalog.
For the Hadoop ecosystem to function smoothly, HCatalog, Hive, Hadoop, and other components must be compatible with one another and configured correctly.
Why HCatalog?
1. Enabling right tool for right job
As we know for data processing such as Hive, Pig, and MapReduce, Hadoop ecosystem contains different tools. However, they do not need metadata, so, they can benefit from it when it is present only. Hence, no loading or transfer steps are required.
2. Capture processing states to enable sharing
We can publish our analytics results by HCatalog. Hence via “REST” the other programmer can access our analytics platform also.
3. Integrate Hadoop with everything
In the form of processing as well as storage environment, Hadoop opens up a lot of opportunities for the enterprise. So, with a familiar API and SQL-like language, REST services open up the platform to the enterprise.
As a result, to more deeply integrate with the Hadoop platform, Enterprise data management systems use HCatalog.
HCatalog Architecture
The Hadoop Distributed File System (HDFS) uses the HCatalog component of the Apache Hadoop ecosystem as a metadata repository and storage management layer. For the purpose of managing metadata on tables, partitions, and schemas, it interfaces with the Hive Metastore.
Through its central HCatalog server, HCatalog offers REST APIs and web interfaces for users and applications to interact with the metadata and conduct actions on data while abstracting the HDFS underpinnings. In order to handle Hadoop data operations consistently and effectively, it’s design offers smooth data access, modification, and sharing between multiple Hadoop components and external applications.
Basically, on top of the Hive metastore, HCatalog is built and it incorporates Hive’s DDL. Also, it offers read and writes interfaces for Pig as well as MapReduce and also for issuing data definition and metadata exploration commands, it uses Hive’s command line interface.
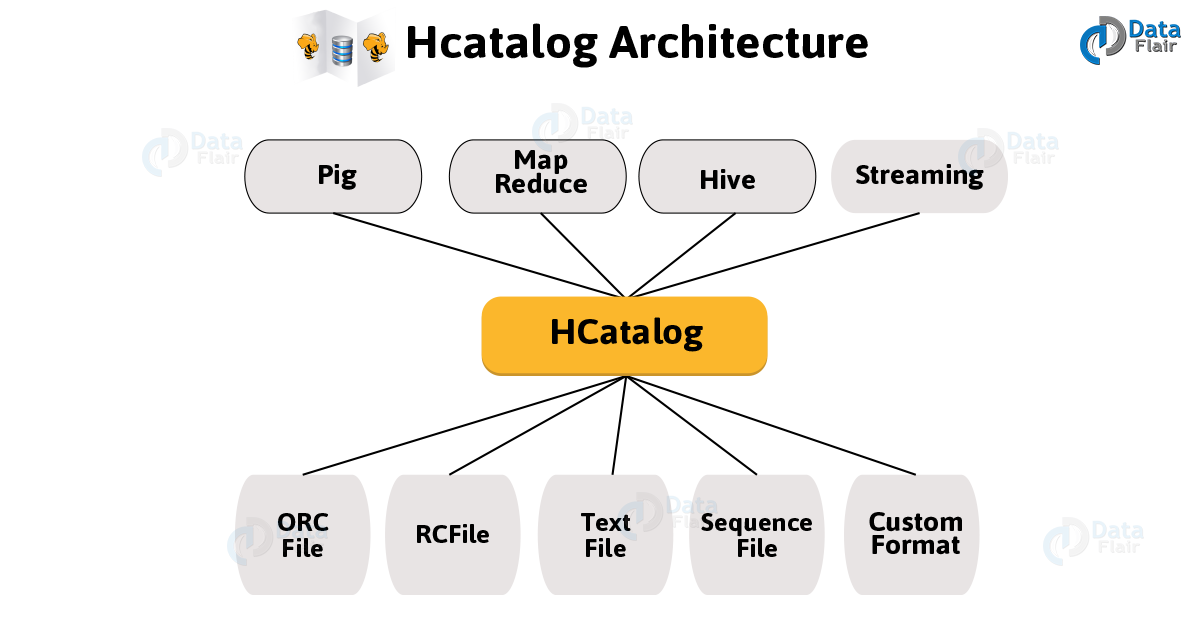
HCatalog Architecture
HCatalog Tutorial – Data Flow Example
Here, is a simple data flow example which explains how HCatalog can help grid users to share as well as to access data:
- First: Copy Data to the Grid
At very first, to get data onto the grid, John uses distcp in data acquisition.
hadoop distcp file:///file.dat hdfs://data/rawevents/20100819/data hcat "alter table rawevents add partition (ds='20100819') location 'hdfs://data/rawevents/20100819/data'"
- Second: Prepare the Data
Then to cleanse and prepare the data, Samuel uses Pig, in data processing.
However, Samuel must be manually informed by John when data is available, or poll on HDFS, without HCatalog.
A = load ‘/data/rawevents/20100819/data’ as (alpha:int, beta:chararray, …);
B = filter A by bot_finder(zeta) = 0;
…
store Z into ‘data/processedevents/20100819/data’;
Further, HCatalog will send a JMS message that data is available, with HCatalog. Afterward, Pig job starts:
A = load ‘rawevents’ using org.apache.hive.hcatalog.pig.HCatLoader();
B = filter A by date = ‘20100819’ and by bot_finder(zeta) = 0;
…
store Z into ‘processedevents’ using org.apache.hive.hcatalog.pig.HCatStorer(“date=20100819”);
- Third: Analyze the Data
Further, to analyze his clients’ results, Ross uses Hive in client management.
So, Ross must alter the table to add the required partition, without the HCatalog.
alter table processedevents add partition 20100819 hdfs://data/processedevents/20100819/data
select advertiser_id, count(clicks)
from processedevents
where date = ‘20100819’
group by advertiser_id;
Although, Ross does not need to modify the table structure, with HCatalog.
select advertiser_id, count(clicks)
from processedevents
where date = ‘20100819’
group by advertiser_id;
How HCatalog Works?
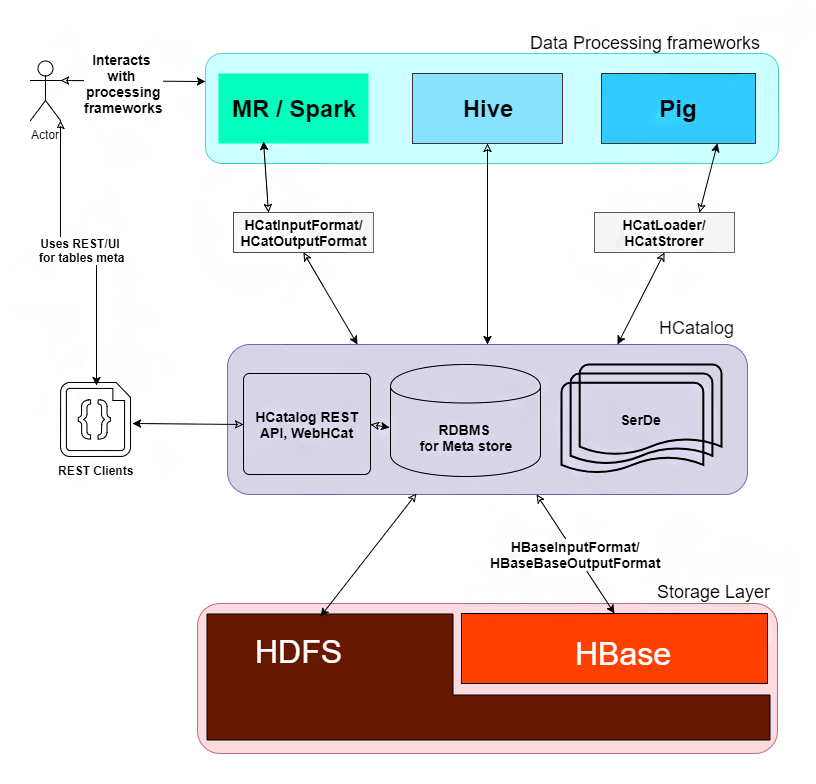
Working of HCatalog
On top of the Hive metastore, HCatalog is built. Basically, it incorporates components from the Hive DDL. So, for Pig and MapReduce, the HCatalog provides read and write interfaces.
Also, for issuing data definition and metadata exploration commands, it uses the Hive’s command line interface. In addition, to permit external tools access to Hive DDL operations, it also presents a REST interface, such as “create table” and “describe table.”
Further, it presents a relational view of data. Here, data save in table format and further these tables go into databases. However, we can partition the table on one or more keys. So, there will be one partition that contains all rows with that value (or set of values), for a given value of a key (or set of keys).
HCatalog Web API
Basically, for HCatalog, WebHCat is a REST API. Where REST refers to “representational state transfer”. It is a style of API, which relies on HTTP verbs. However, Templeton was the name of WebHCat, originally.
Benefits of HCatalog
There are several benefits that Apache HCatalog offers:
- With the table abstraction, it frees the user from having to know the location of stored data.
- Moreover, it enables notifications of data availability.
- Also, it offers visibility for data cleaning and archiving tools.
So, this was all about HCatalog Tutorial. Hope you like our explanation
Summary
Hence, in this HCatalog tutorial, we have learned the whole about HCatalog in detail. Moreover, we discussed the meaning and need of HCatalog. Also, we discussed HCatalog Architecture and examples.
Along with this, we discussed the working of HCatalog, HCatalog Web API, and the benefits ofHCatalog. However, if any doubt in the HCatalog tutorial, feel free to ask in the comment tab.
We work very hard to provide you quality material
Could you take 15 seconds and share your happy experience on Google




