Azure Data Factory
Free AWS Course for AWS Certified Cloud Practitioner (CLF-C01) Start Now!!
FREE Online Courses: Click for Success, Learn for Free - Start Now!
What better opportunity to take a beginner-friendly deep dive into Azure Data Factory than during Microsoft Build 2021? We’ll go through what Azure Data Factory is, how to get started with it, and what you might use it for in this post.
What is Azure Data Factory?
Azure’s Data Factory (ADF) is a serverless, fully managed data integration solution for ingesting, preparing, and converting all of your data at scale.
It allows the company in any industry to use it for a wide range of tasks, including data engineering, transferring on-premises SSIS packages to Azure, operational data integration, analytics, and ingesting data into data warehouses.
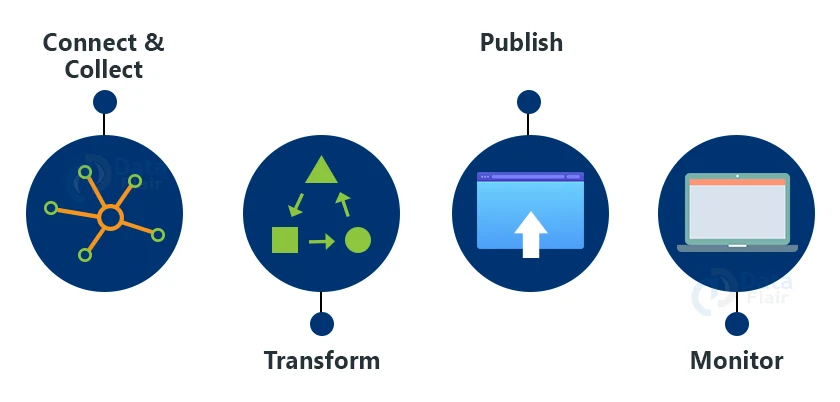
1. Connect & Collect
In a data pipeline, we can utilize the copy action to transport data between on-premises and cloud source data storage.
2. Transform
Process or transform the acquired data using computing services like HDInsight Hadoop, Spark, Data Lake Analytics, and Machine Learning after the data is in a consolidated data repository in the cloud.
3. Publish
It loads the data into Azure Data Warehouse, Azure SQL Database, and Azure Cosmos DB, among other places, after the raw data has been processed into a business-ready consumable form.
4. Monitor
Azure Data Factory includes built-in support for pipeline monitoring through Azure Monitor, API, PowerShell, Log Analytics, and Azure portal health panels.
We may utilize the Data Factory to analyze and store all of this information.
Azure Data Lake Storage is used to store data.
Pipelines are used to transform the data (a logical grouping of activities that together perform a task) and publish the data that has been organized.
Third-party applications such as Apache Spark or Hadoop are used to visualize the data.
Components of Azure Data Factory
Data Factory is made up of four main components. All of these elements work together to create a foundation for creating a data-driven workflow with the structure to transfer and transform data.
1. Pipeline
One or more pipelines can be found in a data factory. It’s a logical collection of actions that work together to complete a task. The activities in a pipeline work together to complete the task.
For example, a pipeline can have a set of activities that ingest data from an Azure blob and then split the data using a Hive query on an HDInsight cluster.
2. Activity
It indicates a pipeline processing step. A copy action, for example, could be used to copy data from one datastore to another.
3. Datasets
It denotes data structures within data stores that point to or refer to the data we want to use in our I/O actions.
4. Linked Services
It’s similar to connection strings, which specify the information Data Factory needs to connect to other resources. A linked service can be used as a data store as well as a computation resource.
A linked service can also be a computer resource or a link to data storage.
5. Triggers
It’s the processing unit that determines when a pipeline’s execution has to be stopped.
We can also utilize the trigger to disable an action, and we may schedule these activities to be done at a specific time.
6. Control Flow
It is a pipeline orchestration that includes chaining operations in a sequence, branching, specifying pipeline parameters, and passing arguments while invoking the pipeline on-demand or via a trigger.
Control flow can be used to sequence particular operations and define which parameters must be passed for each activity.
Flow Process of Data Factory
Now, in this Azure Data Factory article, we’ll go over how Azure Data Factory works. The Data Factory service allows us to design pipelines that help us transfer and transform data, and then schedule them to run on a daily, hourly, or monthly basis.
Workflows consume and create data that is time-sliced, and the pipeline mode can be set to scheduled or one-time.
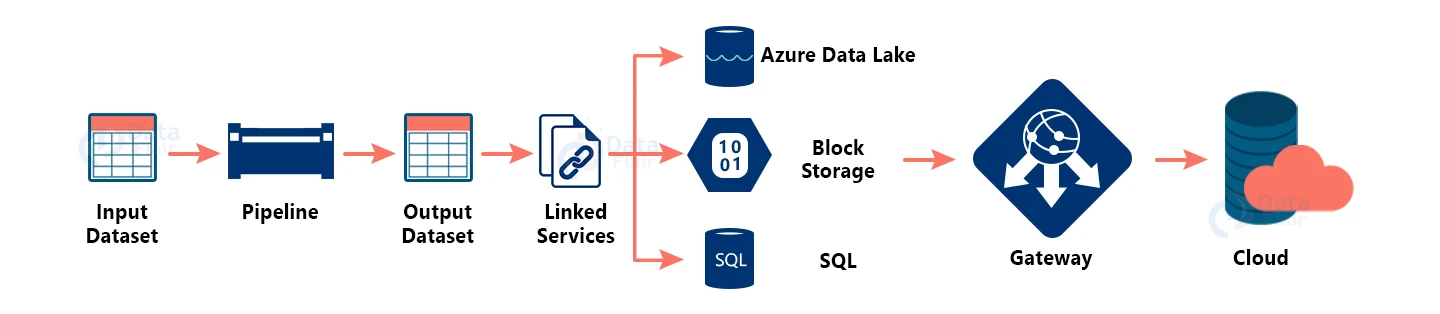
- Input Dataset: The data we have in our data store that needs to be processed and then transmitted via a pipeline is referred to as the input dataset.
- Pipeline: A pipeline is a system that transforms data. Data transformation can be anything from data transportation to data transformation.
- Output Dataset: Because the data has already been processed and structured in the pipeline storage, the output dataset will contain structured data. The information is then passed on to associated services such as Azure Data Lake, blob storage, and SQL.
- Linked services: These keep track of information that is crucial when connecting to an external source.
- Gateway: Our on-premises data is connected to the cloud through the Gateway. To connect to the Azure cloud, we need to install a client on our on-premises system.
- Cloud: We can analyze and visualize our data using a variety of analytical applications such as Apache Spark, R, Hadoop, and others.
Enterprise Connectors on Data Stores
Azure Data Factory allows businesses to ingest data from a wide range of sources.
Azure Data Factory links to all data sources, whether on-premises, multi-cloud or offered by Software-as-a-Service (SaaS) providers, for no additional licensing fee.
You can copy data between different data storage with the Copy Activity.
By making it simple to connect to a variety of business data sources, transform them at scale, and write the processed data to a data store of your choosing, Azure Data Factory helps you shorten the time to insight.
On-premises Data Access
There will be on-premises enterprise data sources for many enterprises.
Using a Self-Hosted Integration Runtime, Azure Data Factory allows enterprises to connect to these on-premises data sources.
Organizations can use the Self-hosted integration runtime to transport data between on-premises and cloud data sources without having to open any incoming network ports.
This makes it simple for anyone to install the runtime and start integrating hybrid cloud data.
Code-free Data Flow
Any developer may use Azure Data Factory to create code-free data flows to speed up the creation of data transformations.
Any developer can use the ADF Studio to design data transformations without having to write any code.
In Azure Data Factory, you construct a data flow by first specifying the data sources from which you wish to acquire data, and then applying a rich set of transformations to the data before writing it to a data store.
Under the hood, Azure Data Factory uses a Spark cluster to scale these data flows for you. It doesn’t matter if you’re working with megabytes (MB) or terabytes (TB) of data (TB).
Azure Data Factory performs data transformations at Spark scale without requiring you to set up or tune a Spark cluster. The data transformation just works in numerous ways!
Secured Data Integration
By connecting to private endpoints supported by various Azure data storage, Azure Data Factory enables secure data integration.
Azure Data Factory controls the virtual network beneath the hood to relieve you of the burden of operating your virtual network.
This makes it simple to set up a Data Factory and ensure that all data integration takes place on a secure virtual network.
CI/CD Support
Any developer can utilize Azure Data Factory as part of a continuous integration and delivery (CI/CD) strategy.
A developer can use CI/CD with Azure Data Factory to move Data Factory assets (pipelines, data flows, linked services, and more) from one environment (development, test, and production) to another.
Azure Data Factory comes with integrated integrations for Azure DevOps and GitHub out of the box.
Integrated Runtime
An integration runtime serves as a connection point between ADF and the data or computation resources you require.
If you’re using ADF to manage native Azure resources like an Azure Data Lake or Databricks, ADF understands how to communicate with them.
There’s no need to set up or configure anything if you use the built-in integration runtime.
However, let’s say you want ADF to interact with data on an Oracle Database server under your desk, or machines and data on your company’s private network.
In these circumstances, you’ll need to use a self-hosted integration runtime to set up the gateway.
Linked Service
A linked service instructs ADF on how to access the data or systems you want to work with.
You establish a linked service for a specific Azure storage account and include access credentials in it to gain access to it.
You must build another associated service to read/write another storage account.
Your linked service will specify the Azure subscription, server name, database name, and credentials to allow ADF to run on an Azure SQL database.
Data Set
A data set identifies the folder you’re utilizing within a storage container, or the table within a database, for example, and makes a linked service more precise.
The data in this snapshot refers to a single directory in a single Azure storage account.
It’s worth noting how the data set refers to a linked service.
It’s also worth noting that this data set states that the data is zipped, allowing ADF to unzip the data as you read it.
Source and Sink
A source and a sink are, as their names suggest, locations where data originates and ends. Data sets are used to create sources and sinks. ADF is primarily concerned with moving data from one location to another, generally with some kind of transformation along the way, therefore it must be aware of where the data should be moved.
It’s crucial to realize that there’s a blurry line between data sets and sources/sinks.
A data set defines a specific collection of data, although the collection can be redefined by a source or sink.
Activity
Activities are Data Factory GUI widgets that perform various types of data transportation or processing.
A Copy Data activity is used to move data, a For Each activity is used to cycle through a file list, a Filter activity is used to choose a subset of files, and so on.
There is a source and a drain for almost every activity.
Pipeline
An ADF pipeline is the top-level concept with which you interact the most. Activities and data flow arrows make up pipelines.
ADF is programmed using pipelines. Running pipelines, either manually or through automatic triggers, allows you to get work done.
Monitoring pipeline execution allows you to examine the outcomes of your efforts.
Data Integration and Governance in Azure Data Factory
Organizations may gain amazing insights into the lineage, policy management, and more by combining Data Integration and Data Governance.
Azure Data Factory has a natural integration with Azure Purview, which provides significant insights into ETL lineage, a holistic view of how data is moved across the enterprise from various data stores, and more.
A data engineer, for example, could wish to look into a data issue where inaccurate data has been inserted as a result of upstream difficulties. The data engineer can now quickly identify the problem thanks to the Azure Data Factory interaction with Azure Purview.
Working on Azure Data Factory
Data Factory is a collection of interconnected platforms that give data engineers a complete and amazing end-to-end platform.
Ingest
- Multi-cloud and on-premise hybrid copy of data.
- It can have 100+native connectors
- Data Factory is serverless and can perform auto-scaling
- Developers can use wizard for easy and quick copy jobs.
Control Flow
- Azure’s Data factory consists of designing code-free data pipelines
- It can generate pipelines with the help of SDKs
- Developers can use the workflow for constructing loops, branches conditional executions, variable parameters etc.
Data Flow
- Azure’s Data Factory is a code-free data transformation which executes Spark.
- Developers can easily scale out the application with Azure integration runtimes which can generate data flows with SDK.
- It is a good solution for data engineers and data analysts
Schedule
- Users can build and maintain operational schedules according to their data pipeline.
- Wall clock event-based and tumbling windows can be combined.
Monitor
- Developers can see their active execution and old pipeline history.
- Users can get information about their detailed activity and data flow executions.
- Admins can enable alerts and notifications
Mapping the Data Flows
Create and manage data transformation logic graphs that may be used to transform any type of data.
One can develop a reusable library of data transformation procedures and execute it from your ADF pipelines in a scaled-out manner.
Data Factory will run your logic on a Spark cluster that will scale up and down as needed. Clusters will never need to be managed or maintained.
Pipeline Runs
The pipeline execution is represented by a pipeline run. In most cases, pipeline runs are started by giving arguments to the parameters set in the pipeline. The arguments can be manually entered or passed through the trigger definition.
Parameters
Parameters are read-only configuration key-value pairs. In the pipeline, parameters are defined. The arguments for the defined parameters are passed from the run context produced by a trigger or a pipeline that was manually triggered during execution.
The parameter values are consumed by activities within the pipeline. A dataset is a reusable/referenceable item with a highly typed parameter.
A dataset can be referenced by an activity, and the characteristics defined in the dataset specification can be consumed by the activity.
A linked service is a highly typed parameter that has information on how to connect to a data storage or a computing environment. It’s also a referenceable/reusable entity.
Variables
Variables can be used to hold temporary values inside pipelines, and they can also be used in conjunction with parameters to pass values across pipelines, data flows, and other operations.
What does Azure Data Factory do?
Azure Data Factory allows users to:
- Data can be copied from a variety of on-premise and cloud-based sources.
- Transform the information (cf. below paragraphs)
- Publish the data that has been copied and changed, and send it to a data storage or analytics engine.
- A rich graphical interface is used to monitor the data flows.
What doesn’t Azure Data Factory do?
In the cloud, Data Factory isn’t SSIS (SQL Server Integration Services). It focuses on supporting broader data transformations and motions and has less database-specific functionality (incl. big datasets, incl. data lake operations).
However, Data Factory can run your SSIS packages in the cloud (once built in SSIS). This enables Data Factory’s scalability to be combined with SSIS’ powerful ETL capabilities.
Why do we need Azure Data Factory?
Any Cloud project can benefit from Data Factory.
Data transportation operations between several networks (on-premise network and Cloud) and across numerous services are required in practically every Cloud project (i.e., from and to close different Azure storages).
Data Factory is a critical facilitator for enterprises taking their initial steps into the Cloud and attempting to connect on-premise data with cloud data.
Azure Data Factory offers an Integration Runtime engine and a Gateway service that can be implemented on-premises to provide fast and safe data movement from and to the cloud.
How does Azure Data Factory Vary from other ETL Tools?
One alternative for a cloud ETL (or ELT) tool is Data Factory. Azure Data Factory has a few characteristics that set it apart from other solutions.
- It’s also capable of running SSIS packages.
- It scales automatically (fully managed PaaS solution) in response to the workload.
- It allows you to run at a rate of up to once every minute.
- Through a gateway, it easily connects on-premises and Azure Cloud.
- It has the capability of handling large amounts of data.
- It may connect to and collaborate with other compute services (Azure Batch, HDInsight) to perform large-scale data processing during ETL.
- According to our knowledge, the greatest alternative to Azure Data Factory is Apache Airflow, which has both benefits and drawbacks. For further information, please contact us.
How to work with Azure Data Factory?
Azure Data Factory is a graphical user interface tool that allows you to develop and manage activities and pipelines. Although no coding skills are required, complicated transformations will necessitate Azure Data Factory familiarity.
All on-premise data sources, including MySQL, SQL Server, and Oracle DBs, are supported via default connections in Azure Data Factory.
The outcome of one activity can be used as a trigger for the initiation of another activity in the Azure Data Factory.
For example, copy data from on-premise to Blob before merging all blobs.
Tumbling window and event triggers are supported by Azure Data Factory. The first is very important for partitioning data in a Data Lake setup (for example, automatically saving your data in daily partitioned blobs: e.g., YYYY/MM/DD/Blob.csv).
When an event, like a new Blob on Blob Storage, should automatically trigger a transformation, an event trigger is used.
Working with parameters in Azure Data Factory allows you to dynamically pass parameters between datasets, pipelines, and triggers. For example, the filename of the destination file could be the pipeline’s name or the data slice’s date.
Pipelines can be run at a rate of up to one per minute using Azure Data Factory. As a result, it does not allow for real-time, but it does allow for near real-time.
Monitoring and alerting are provided via Azure Data Factory. The different pipelines’ operations can be readily watched via the UI, and you can set up alarms (connected to Azure Monitor) if something goes wrong.
To schedule ML algorithms, Azure Data Factory can function nicely with Azure Databricks.
Should we use Azure Data Factory or SSIS?
Use the appropriate tool for the job. You can see how complementary they are in the diagram below.
They’re also constructed that way: for example, Azure Data Factory allows you to deploy, manage, and run SSIS packages in Azure SSIS Integration Runtimes that are managed.
Based on the platform/solution
| Hybrid On-Prem and Azure Solution | Azure Solution | On-Prem Only Solution | |
| Azure Data Factory (ADF V2) | Yes | Yes | No |
| Integration Services (SSIS) | Yes | Yes | Yes |
Based on the data type
| Small Data | Close to real-time data (in every minute) | Big Data | |
| Azure Data Factory (ADF V2) | Yes | Yes | Yes |
| Integration Services (SSIS) | Yes | No | No |
Creating Azure Data-Factory in Azure Portal
Below are the steps to create data factory in azure:
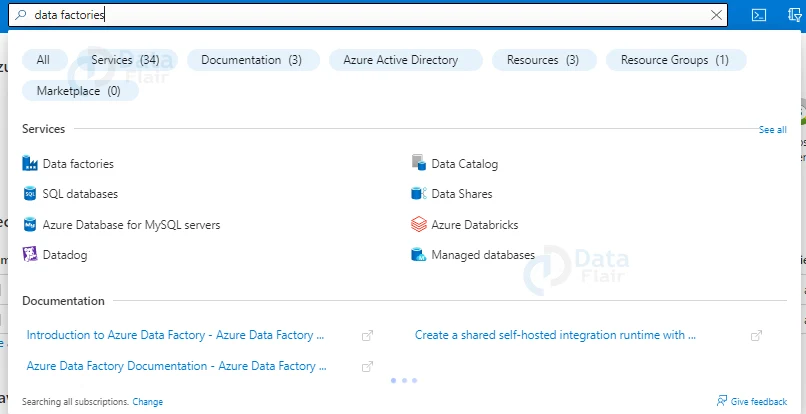
1: Firstly, click on create a resource and search for Data Factory then click on create button.
2: Click on the Create Data Factory Button.
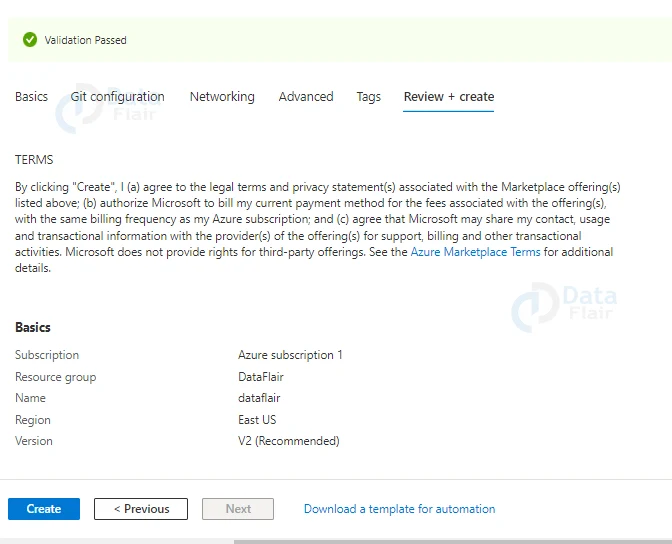
3: Choose a name for your data factory, a resource group, and the location and version where you wish to deploy your data factory.
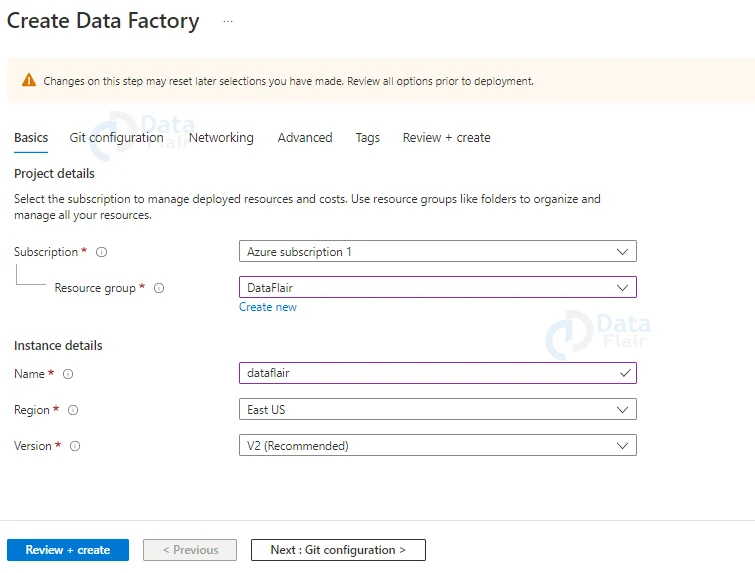
4: If you have any repositories from the Azure DevOps account or GitHub. You can configure it here.
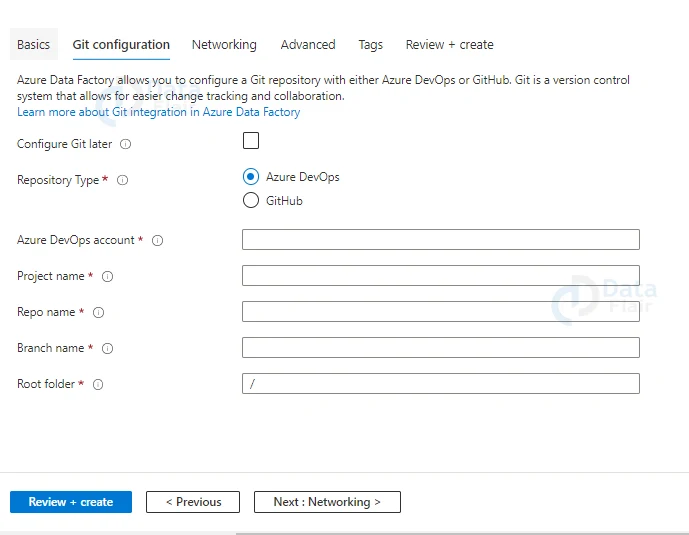
5: Now configure the networking endpoints.
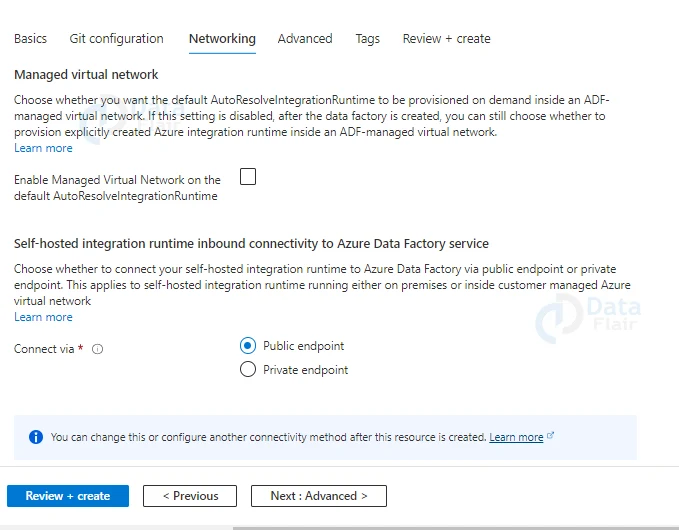
6: In the advanced settings choose the encryption technique.
7: Provide appropriate tags.
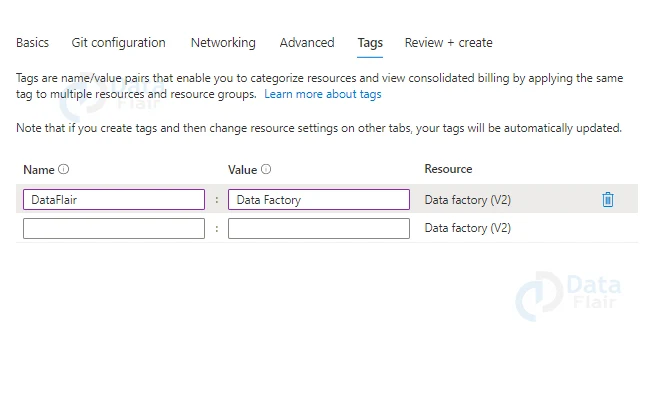
8: Review all the details and click on the create button.
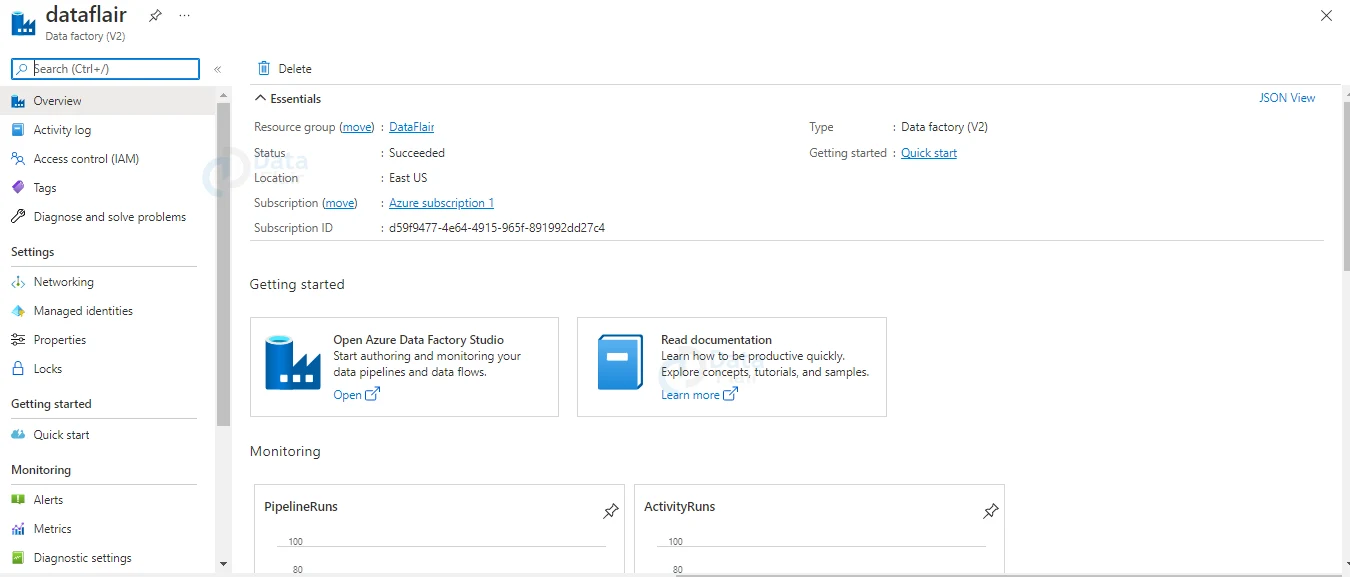
Once the deployment is successful you will be on your data factory page.
Usage Scenarios
Consider a gaming corporation that accumulates petabytes of game logs generated by cloud-based games.
The corporation intends to examine these records to learn more about client preferences, demographics, and usage patterns.
It also aims to find up-sell and cross-sell opportunities, create appealing new products, expand its business, and give its clients a better experience.
To evaluate these logs, the organization will need to employ reference data from an on-premises data store, such as customer information, game information, and marketing campaign information.
The corporation wishes to combine this data from the on-premises data store with additional log data from a cloud data store to make use of it.
It plans to analyze the linked data using a cloud Spark cluster (Azure HDInsight) and publish the processed data into a cloud data warehouse like Azure Synapse Analytics so that it can simply develop a report on top of it.
They wish to automate this process while also monitoring and managing it daily. They also want it to run when files are dropped into a blob storage container. Such data issues can be solved with the Azure Data Factory platform.
It’s a cloud-based ETL and data integration solution that allows you to create data-driven processes for large-scale data transportation and transformation.
Azure Data Factory can be used to create and plan data-driven workflows (also known as pipelines) that consume data from a variety of sources.
With data flows or compute services like Azure HDInsight Hadoop, Azure Databricks, and Azure SQL Database, you can create complicated ETL processes that change data visually.
Such data issues can be solved with the Azure Data Factory platform. It’s a cloud-based ETL and data integration solution that allows you to create data-driven processes for large-scale data transportation and transformation.
Azure Data Factory can be used to create and plan data-driven workflows (also known as pipelines) that consume data from a variety of sources.
With data flows or compute services like Azure HDInsight Hadoop, Azure Databricks, and Azure SQL Database, you can create complicated ETL processes that change data visually.
You can also upload your converted data to data stores like Azure Synapse Analytics for consumption by business intelligence (BI) applications.
Finally, raw data can be structured into useful data stores and data lakes for better business decisions with Azure Data Factory.
Features of Azure Data Factory
1. Easy to Use
With built-in Git and CI/CD support, rehost SQL Server Integration Services (SSIS) in a few clicks and develop code-free ETL and ELT pipelines.
2. Cost-effective
Enjoy a fully managed, pay-as-you-go serverless cloud solution that scales on-demand.
3. Powerful
With more than 90 built-in connectors, you can ingest all of your on-premises and software as a service (SaaS) data. At a large scale, orchestrate and monitor.
5. Intelligent
To unleash operational efficiencies and empower citizen integrators, use autonomous ETL.
Conclusion
Azure Data Factory is a fully managed, serverless data integration service that can integrate all of your data. At no additional cost, visually connect data sources with more than 90 built-in, maintenance-free connectors.
Create ETL and ELT procedures in an intuitive environment without writing code, or building your own. Then, to gain business insights, send the combined data to Azure Synapse Analytics.
You give me 15 seconds I promise you best tutorials
Please share your happy experience on Google

