Azure Cosmos DB
Top AWS Course for AWS Certified Cloud Practitioner (CLF-C01) Start Now!!
Expert-led Courses: Transform Your Career – Enroll Now
Hello Readers, if you are working with massive data and you want a decent database for storing the data, then Azure Cosmos DB is the solution. So, in today’s article, we will learn about Azure Cosmos DB. Let us begin.
What is Cosmos DB in Azure?
Microsoft’s Azure Cosmos DB is a multi-model database service that is globally distributed and horizontally partitioned. Customers can elastically (and independently) scale throughput and storage across any number of geographical locations using the service.
Guaranteed low latency at the 99th percentile, 99.99 percent high availability, predictable throughput, and several well-defined consistency models are all available with Azure Cosmos DB.
Azure Cosmos DB is the industry’s first and only worldwide distributed database service to provide complete Service Level Agreements (SLAs) that cover all four characteristics of global distributions that matter to our customers: throughput, 99th percentile latency, availability, and consistency.
We carefully developed and engineered Azure Cosmos DB as a cloud service with multi-tenancy and global distribution in mind.
In this article, we’ll go through some of Azure Cosmos DB’s key features and architectural choices.
Design Goals of Azure Cosmos DB
“Project Florence” was the name given to Azure Cosmos DB when it was first released in 2010.
The purpose was to address the basic issues that developers working on web-scale applications at Microsoft encountered.
For Azure Cosmos DB, we set the following design goals.
Allow consumers to flexibly expand throughput and storage based on demand anywhere in the world.
From the moment of the request to scale, the system should deliver the configured throughput in less than 5 seconds at the 99th percentile.
Allow customers to create highly responsive, mission-critical applications. At the 99th percentile, the system must have predictable and guaranteed end-to-end low read and write latencies.
Check to see if the system is “always on.” Regardless of the number of regions associated with their database, the system must ensure 99.99 percent availability.
Customers must be able to simulate regional failures or mark regions associated with their database offline in order to verify the applications’ end-to-end availability properties (in steady-state).
This aids in the validation of an application’s end-to-end availability attributes.
Provide developers with the tools they need to create correct globally distributed applications. The system must provide a programming model for data consistency that is both clear and predictable.
While strong consistency has a cost, creating big globally distributed systems against an “eventually consistent” database produces application code that is difficult to reason about, brittle, and full of correctness issues.
For items 1, 2, 3, and 4, provide detailed financial-backed SLAs.
Remove the burden of database schema/index management and versioning from the developers.
For globally distributed systems, keeping database schema and indexes in-sync with an application’s schema is very difficult.
Multiple data models and major APIs for data access are natively supported. The transition from externally exposed APIs to internal data representation had to be quick.
Operating at a low cost allows you to pass the savings on to your customers.
Aspects of Azure Cosmos DB’s Design Worth Noting
The design of Azure Cosmos DB allows you to dynamically vary the database engine’s proximity to the underlying storage, allowing you to provide numerous service tiers with different performance SLAs.
The system can be designed to enable computation and storage (a) co-located inside the same process space, (b) disaggregated across machines within the same cluster, or (c) disaggregated across various clusters/data centers within the same region, depending on the service tier.
The implementation of full SLAs for performance, latency, consistency, and availability in Azure Cosmos DB.
In a globally distributed configuration, these SLAs explicitly explain the tradeoffs between latency, consistency, availability, and throughput.
The unique resource governance concept at the heart of Azure Cosmos DB provides a consistent programming approach for provisioning throughput across a diverse collection of database activities.
The highly modular and resource-governed strategy used by Azure Cosmos DB to tackle a range of coordination difficulties, including cross-region replication and transparent partition management.
The design of Azure Cosmos DB allows for elastic scaling of throughput across many geographical regions while still preserving SLAs.
The system is built to scale throughput across regions while ensuring that changes in throughput are immediate.
The design and implementation of TLA+ in Azure Cosmos DB allows accurately describing a set of relaxed yet well-defined consistency models.
This allows developers to design accurate distributed applications using practical consistency models for real-world circumstances.
It also delivers verifiable consistency guarantees, is commercially viable in a multi-tenant and globally distributed environment, and has an understandable programming paradigm.
To our knowledge, Azure Cosmos DB is the first globally distributed database system that has operationalized the constrained staleness, session, and consistent prefix consistency models, exposing them to developers with clear semantics, performance/availability tradeoffs, and SLAs.
The write-optimized, resource-governed, and schema-agnostic database engine in Azure Cosmos DB is capable of ingesting a sustained volume of updates.
It automatically indexes everything it ingests and synchronously makes the index durable and highly available before acknowledging the client’s updates while maintaining low latency guarantees.
The fundamental data model and type system of Azure Cosmos DB, as well as its extensible database engine design, allows multiple data models, APIs, and programming language type systems to be easily added, translated, and projected onto its core data model.
Multi-Model and Multi-API Database Service
Azure Cosmos DB supports different data models out of the box, as shown in the diagram above. The database engine of Azure Cosmos DB is based on the atom-record-sequence (ARS) type system.
Atoms are made up of a small number of primitive types such as string, bool, and number, whereas records are structs and sequences are arrays made up of atoms, records, and sequences.
Azure Cosmos DB’s database engine is capable of quickly translating and projecting data models onto an ARS-based data model.
Azure Cosmos DB’s basic data model is natively accessible from dynamically typed programming languages and can be provided in JSON or other equivalent formats.
The design also makes it possible to use major database APIs for data access and querying natively. Documentdb SQL, MongoDB, Azure Table Storage, and the Gremlin graph query API are currently supported by Azure Cosmos DB’s database engine.
We plan to provide support for other major database APIs in the future.
The main advantage is that developers can continue to use popular OSS APIs while also benefiting from a battle-tested and fully managed worldwide distributed database system.
Resource Model and API Projections
Azure Cosmos DB can be used by developers by creating a database account with their Azure subscription.
One or more databases are managed by a database account. Users, permissions, and containers are all managed by an Azure Cosmos DB database.
A schema-agnostic Azure Cosmos DB container holds arbitrary user-generated entities, stored procedures, triggers, and user-defined functions (UDFs).
Databases, users, permissions, containers, and other entities under the customer’s database account are referred to as resources, as shown in Figure.
Each resource is represented as a JSON document and is uniquely recognised by a stable and logical URI.
An Azure Cosmos DB application’s overall resource model is a hierarchical overlay of resources rooted under the database account that can be browsed using hyperlinks.
All other resources have a system-defined schema, except for the item resource, which is used to represent any user-defined information.
The item resource’s content model is based on the atom-record-sequence (ARS) concept discussed earlier.
Both container and item resources are reified resource types for a certain sort of API interface.
Horizontal Partitioning
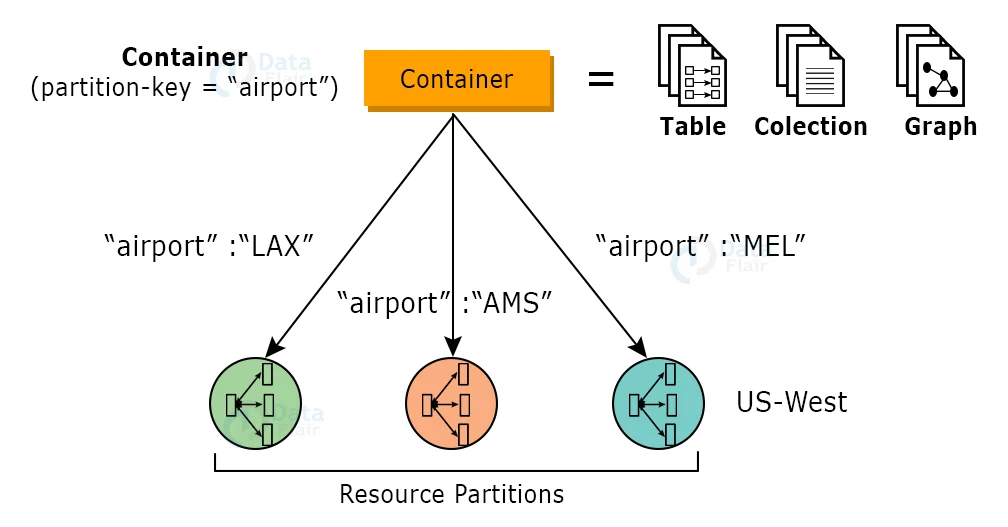
As shown below in Figure, all data within an Azure Cosmos DB container (such as a collection, table, graph, and so on) is horizontally partitioned and transparently controlled by resource partitions.
A resource partition is a consistent and highly available container of data partitioned by a partition key given by the client; it provides a single system image for the resources it manages and is a fundamental unit of scaling and distribution.
Customers may elastically increase throughput depending on application traffic patterns across different geographical regions with Azure Cosmos DB to manage fluctuating workloads that vary by location and time.
The solution invisibly manages the partitions without compromising the Azure Cosmos DB container’s availability, consistency, latency, or performance.
Global Distribution from Ground-Up
A customer’s resources are spread in two dimensions, as shown in the Figure below: within a given region, all resources are horizontally partitioned using resource partitions (local distribution).
Each resource split is also replicated in different geographical areas (global distribution).
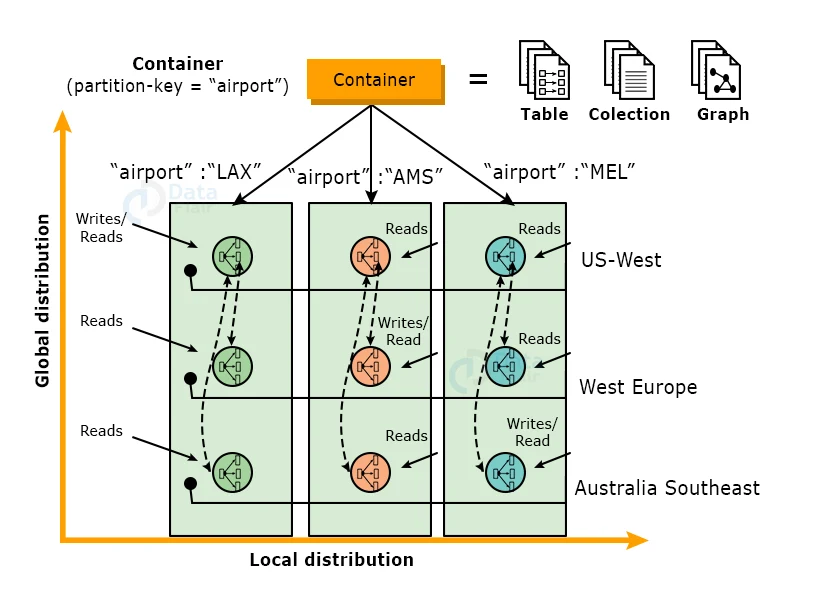
Azure Cosmos DB transparently provides partition management activities across all regions when clients elastically scale throughput or storage.
Azure Cosmos DB continues to deliver a single system picture of globally distributed resources, regardless of scale, dispersion, or failures.
Customers can associate any number of geographical areas with their database account at any moment with a few clicks (or programmatically with a single API call) in Azure Cosmos DB.
At the 99th percentile, Azure Cosmos DB assures that each newly joined region will begin processing client requests in under an hour, regardless of the volume of data or the number of regions.
This is accomplished by parallelizing the seeding process and copying data from all of the source resource partitions to the newly created area.
Customers can also take a region that was previously associated with their database account “offline” or remove an existing area.
Transparent Multi-Homing and 99.99% High Availability
Customers can also assign “priorities” to the regions linked with their database account on a per-region basis.
In the event of regional failures, priorities are employed to direct queries to specified regions. Azure Cosmos DB will automatically failover in the order of priority in the unlikely case of a regional disaster.
Customers can manually activate failover to test the application’s end-to-end availability (rate limited to two operations within an hour). In the event of a customer-triggered regional failover, Azure Cosmos DB guarantees zero data loss and an upper bound on data loss in the event of a system-triggered automatic failover during a regional disaster.
When a regional failover occurs, the application does not need to be re-deployed, and the availability of SLAs is maintained.
For this, Azure Cosmos DB gives developers the option of using logical (region-agnostic) or physical (region-specific) endpoints to communicate with their resources.
The former assures that the programme may be multi-homed invisibly in the event of a failover, while the latter gives the application fine-grained control over reads and writes to specified areas.
Every database account in Azure Cosmos DB comes with a 99.99 percent availability SLA. The availability assurances are independent of the database’s scalability (throughput and storage), several regions, or the geographical distance between regions.
Low Latency Guarantees 99th percentile
Azure Cosmos DB promises customers end-to-end low latency at the 99th percentile as part of its SLAs.
At the 99th percentile within the same Azure region, Azure Cosmos DB promises end-to-end latency of reads under 10ms and indexed writes under 15ms for a typical 1KB item.
The average latencies are much shorter (under 5ms).
Azure Cosmos DB helps clients to distinguish between transactions with significant latency and databases that are unavailable by imposing an upper bound on request processing on each database transaction.
Multiple and Well-Defined Consistency Models Backed By SLAs
Commercial distributed databases now available fall into one of two categories: (1) databases with no well-defined, verifiable consistency options, or (2) databases with two extreme consistency options: strong vs. eventual consistency.
The earlier solutions load application developers with replication protocol minutiae and demand them to make difficult compromises between consistency, availability, latency, and throughput.
Application developers are forced to pick between the two extremes by the latter systems.
Despite a slew of studies and recommendations for various consistency models, commercial distributed database services have yet to operationalize consistency levels beyond strong and eventual consistency.
Strong, constrained staleness, session, consistent prefix, and eventual are the five well-defined consistency models available in Azure Cosmos DB throughout the consistency spectrum.
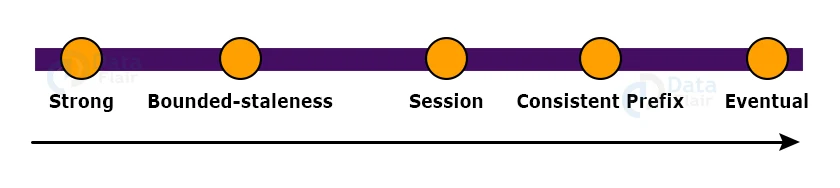
On their database account, developers using Azure Cosmos DB can set the default consistency level (and later override the consistency on a specific read request).
The default consistency level applies to data within partition sets that may traverse regions internally.
Session consistency is used by 73 percent of our customers, whereas constrained staleness is preferred by 20%.
We’ve noticed that about 3% of clients experiment with several consistency levels before settling on a single consistency level for their application.
Azure also discovered that only 2% of their clients, on average, override consistency standards on a per-request basis. It uses a linearizability checker that runs continually over our service data to flag any violations of the consistency SLAs to customers. Azure Monitor and notify any violations to the k and t boundaries for constrained staleness.
Complete Resource Governed Stack
Customers may elastically increase throughput depending on application traffic patterns across different regions with Azure Cosmos DB to manage fluctuating workloads that vary by location and time.
Fine-grained multi-tenancy, where hundreds of clients share the same machine and thousands share the same cluster, is required to run hundreds of thousands of internationally distributed and heterogeneous workloads cost-effectively.
Developers build the entire system from the bottom up with resource governance in mind to provide performance isolation to each customer while remaining cost-effective.
Azure Cosmos DB is a massively distributed queuing system with cascaded tiers of components, each carefully calibrated to offer predictable throughput while working within the system’s allowed budget of resources as a resource regulated system.
To make the most of the system resources (CPU, memory, disc, and network) available in a cluster, each machine must be capable of dynamically hosting tens to hundreds of clients.
From admission control to all I/O pathways, rate-limiting and back-pressure are implemented across the stack.
Azure’s database engine is built to take advantage of fine-grained parallelism and deliver fast throughput while using minimal system resources.
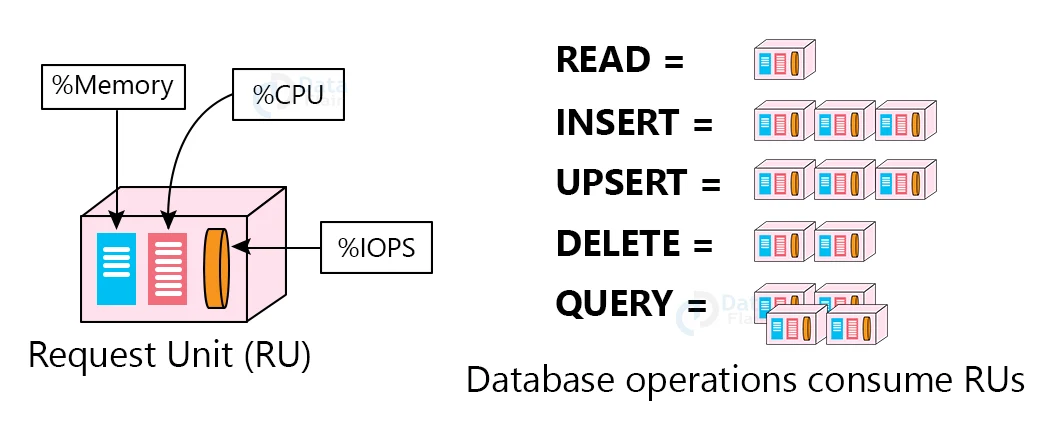
The primary unit of reservation and consumption of system resources is the number of database operations issued in a unit of time (i.e., throughput).
Customers can use their data to perform a wide range of database operations.
The operation may require varying amounts of system resources depending on the type of operation and the size of (the request and response) payload.
Budget system resources correspond to the throughput a given resource partition needs to deliver, and charge customers for throughput across various database operations consistently and in a hardware-agnostic manner to provide a normalised model for accounting for the resources consumed by a request.
Request Unit, or RU, is an abstract rate-based currency for throughput that comes in two denominations based on time granularity: request units per second (RU/s) and request units per minute (RU/m).
Customers can programmatically provide RU/s (and/or RU/m) on a container to elastically scale throughput.
To deliver the throughput on a given container, the system controls resource partitioning internally.
Each resource partition must be capable of delivering a share of the overall throughput for a certain budget of system resources when elastically scaling throughput utilising horizontal resource partitioning.
Each resource partition uses adaptive rate limitation as part of its admission control.
The client will receive a “request rate too large” with a back-off time after which the client can retry if the resource partition receives more requests within a second than it was calibrated against.
Within the spare capacity of RUs, a resource partition executes (rate limited) background activities (e.g., background GC of the log-structured database engine, periodic snapshot backups, eliminating expired items, etc). (if any).
We account for the RUs consumed by each micro-operation (e.g., analyzing an item, reading/writing a page, or running a query operator) once a request is accepted.
How to create Cosmos DB in Azure?
Below are the steps to create cosmos db in azure:
1: Open the Azure Portal and log in.
2: Click on create a Resource from the top left corner.

3: Search for Azure Cosmos DB and then select it from the list of results.
4: Now, hit the Create button.
5: Now select the API that best meets your needs. The Core SQL -Recommended option is selected here. The advantage of using Core SQL is that you can query the database using SQL syntax.
6: After you’ve decided on an API that meets your needs, click the Create button.
7: On the Basics tab of the Create Azure Cosmos DB Account – Core (SQL) page, fill in the following information.
- Subscription: To create the Azure Cosmos DB Account, select the Azure Subscription you want to utilize.
- Resource Group: Select an existing resource group, or select the Create new option to create a new resource group if you don’t have one yet.
- Account Name: Give the Azure Cosmos DB account a unique name.
- Location: Choose a region or a specific location.
- Capacity Mode: Select the capacity mode from the drop-down menu.
- Apply Free Tier Discount: Based on your requirements, select the Apply free tier discount option.
Move on to the Global Distribution tab, by clicking the Next: Global Distribution option.
8: Make the following modifications to the Global Distribution tab.
- Geo-Redundancy: Select Disable from the drop-down menu.
- Multi-region Writes: Select the Disable option for Multi-region Writes.
9: Keep the default values for the other tab choices and then click the Review + Create button.
10: The system will now validate all of the information you entered and indicate to you that the validation was successful.
11: Then you’ll see the Create button, which you should click to create an Azure Cosmos DB account.
12: Finally, the notification “Your deployment is complete” will appear. To get to the Azure Cosmos DB account that you just created, click the Go to resource option.
13: The Azure Cosmos DB account page is shown below.
Create a database and a Container
To construct a database and a container, follow the instructions below. To construct the container and database, you’ll need to use Data Explorer as below:
1: Select Data Explorer from the left navigation on the Azure Cosmos DB account page, and then New Container.
2: Apply the following settings to the New Container window.
Database id: Enter “ToDoTask” as the database id. Keep in mind that the database name you enter must be between 1 and 255 characters long. Special characters such as #,? and /, as well as trailing spaces, are not permitted.
Database throughput (auto scale): Depending on your requirements, you can choose between Autoscale and Manual scaling. If you pick Manual, the system will automatically scale the RU/s based on your usage. If you choose Autoscale, the system will automatically scale the RU/s based on your usage.
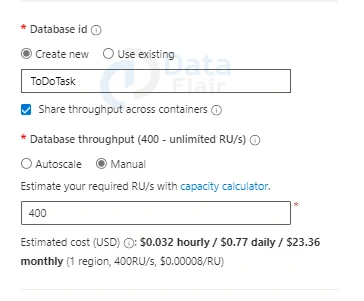
You can specify a throughput of 400 RU/s, with the option to alter it later based on demand.
Container id: As items, enter the Container name. Keep in mind that the Container name you enter must be between 1 and 255 characters long. Special characters such as #,? and /, as well as trailing spaces, are not permitted.
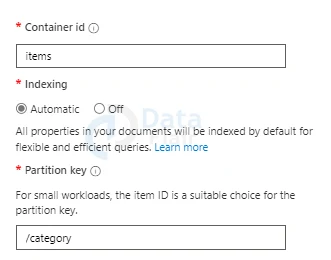
Finally, press the Ok key.
The database, as well as the container, will now be generated.
Adding data to the database
We’ve previously constructed the database and container; now it’s time to populate the database with data. The steps for adding data to the database are outlined below.
1: Select the Data Explorer –> Expand things –> Click on New Item on the Azure Cosmos DB account page.
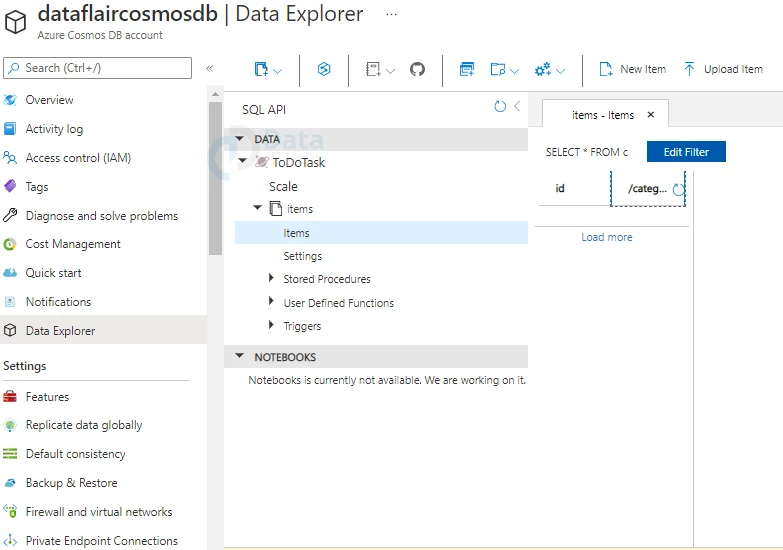
2: After that, paste the JSON script below into the right-hand empty section and hit the Save button.
{ "id": "1", "category": "IT", "name": "PC", "description": "This PC is for Ram.", "isComplete": false
}
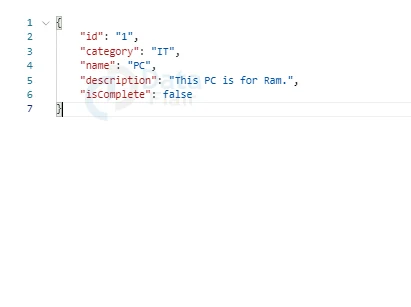
3: If you want to save another entry, pick a New Document and save it with a different unique id, as well as change the other properties.
Querying in Cosmos DB
In truth, querying your data in Azure Cosmos DB is quite simple. You can retrieve the result using any of the standard SQL queries. You can also use the Data Explorer to create stored procedures and triggers, and use the filter option to acquire a specific collection of records, among other things.
Step 1: You can get the default query (SELECT * FROM c) output, which will show you all of the documents on the container, as shown below.
{ "id": "1", "category": "IT", "name": "PC", "description": "This PC is for Ram.", "isComplete": false, "_rid": "FXI0AJaCxzMBAAAAAAAAAA==", "_self": "dbs/FXI0AA==/colls/FXI0AJaCxzM=/docs/FXI0AJaCxzMBAAAAAAAAAA==/", "_etag": "\"cb00d84c-0000-0700-0000-61360b8a0000\"", "_attachments": "attachments/", "_ts": 1630931850
}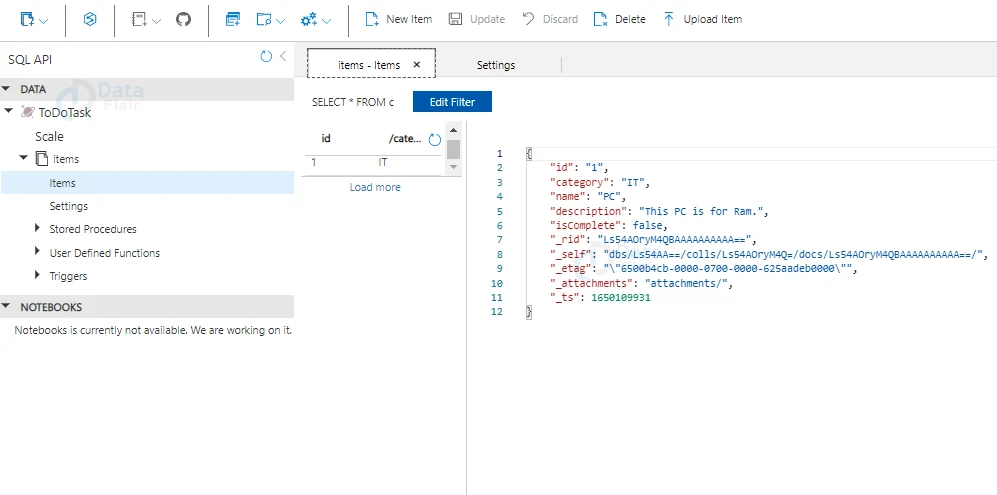
You may now apply the filter to acquire a specified set of records by clicking the Edit Filter button.
Conclusion
The design of Azure Cosmos DB revolves around global distribution, elastic horizontal scalability, and a multi-model and schema-agnostic database engine.
Azure Cosmos DB’s design integrates resource governance throughout its whole stack as a cloud-born multi-tenant database system. The system was built from the ground up to provide all of its customers with global data distribution, multiple well-defined consistency levels, the ability to elastically scale throughput across geographical regions, and comprehensive SLAs covering throughput, consistency, latency, and availability.
Your 15 seconds will encourage us to work even harder
Please share your happy experience on Google




