Automatic Music Generation Project using Deep Learning
Machine Learning courses with 100+ Real-time projects Start Now!!
Automatic Music Generation is a process where a system composes short pieces of music using different parameters like pitch interval, notes, chords, tempo, etc. In this Project we are going to use Piano Instrument with the following terms:
- Note: This is a sound produced by a single key.
- Chords: The combination of 2 or more notes is called a chord.
- Octave: The distance between two notes is stated as an octave in a piano. It is specifically the gap between the two notes that share the same letter name.
About this Project :
In this project, we will be creating an Automatic Music Generation model using LSTM. We will fetch notes from all music files which will then be fed into the model for prediction. Then finally we will create a MIDI file using these predicted notes.
LSTM for Automatic Music Generation :
Long Short Term Memory(LSTM) is a type of RNN (Recurrent Neural Network) that solves some scenarios where RNN failed. LSTM solves Long-Term dependency problem of RNN i.e. RNN networks store data of previous output in a memory for a very short period of time.
LSTM also solves the problem of Vanishing Gradient i.e. in order to get the best result, the model tries to minimize the loss after every time step by calculating loss with respect to some weights. After reaching a certain period, this weight becomes so less that it approximates to zero or vanishes and the model stops training.
Drawback of LSTM:
LSTM requires lots of resources and time to get trained for real world applications. Randomly initializing different weights makes LSTM networks behave similar to that of feed forward neural networks. Therefore they require small weight initialization instead.
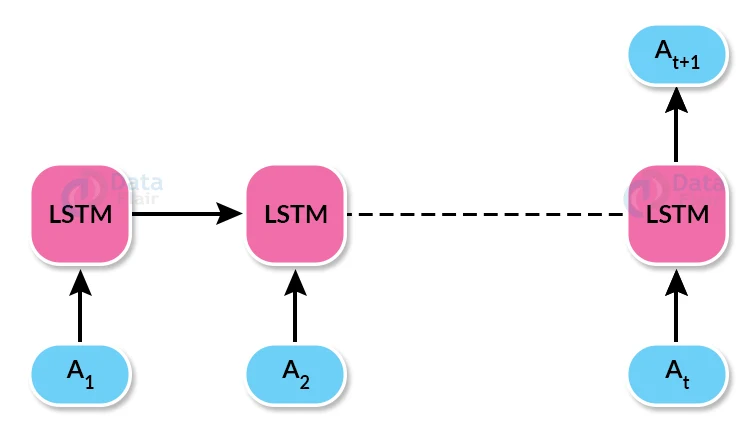
Our model will be a Many-to-one sequence model as there will be one output for every sequence of input notes after each timesteps.
Input to the LSTM model will be the amplitude(A) of these notes which are recorded at different intervals of time which computes hidden vectors and passes to the next layer for the next timestep(t).
Dataset for Automatic Music Generation Project:
Please download the dataset for the automatic music generation project from the following link Classical Music MIDI
This dataset consists of classical piano midi files containing compositions of 19 famous composers scraped from Official Classical Piano Midi
Download Automatic Music Generation Project Code
Please download the source code of automatic music generation with tensorflow: Automatic Music Generation Project Code
Automatic Music Generation Project Prerequisites
Install the following libraries using pip :
pip install numpy, music21, tensorflow, sklearn
The versions which are used in automatic music generation project for python and its corresponding modules are as follows:
- Python: 3.8.5
- TensorFlow: 2.3.1 Note: TensorFlow version should be 2.2 or higher in order to use Keras or else install keras directly
- music21: 5.5.0
- Numpy: 1.19.5
- sklearn: 0.24.2
Music21 is a python library that is used to parse and read various musical files. In this project we will be using the Musical Instrument Digital Interface (MIDI) file which is a small file size with ease of modification and manipulation and a wide choice of electronic instruments. It is a universally accepted file format, which means that music produced by one synthesiser in MIDI format can be modified by another synthesiser.
Project Structure
- All Midi Files/: This is the dataset folder containing various midi files of different composers.
- auto_music_gen.py: In this file, we will build, train and test our model.
- s2s/: This directory contains optimizer, metrics, and weights of our trained model.
- pred_music.mid: This is a music file of predicted notes.
Steps for Automatic Music Generation Project:
1. Import Libraries
Firstly we will import all the required libraries which have been shared in the prerequisites section.
Code:
#DataFlair Automatic Music Generation Project #load all the libraries from music21 import * import glob from tqdm import tqdm import numpy as np import random from tensorflow.keras.layers import LSTM,Dense,Input,Dropout from tensorflow.keras.models import Sequential,Model,load_model from sklearn.model_selection import train_test_split
2. Reading and Parsing the Midi File
We will now read the midi file dataset. We will be using “Schubert” composed files. You can use more or less depending on your system.
For this project, we will be only working on files that contain sequential streams of Piano data. We will separate all files by their instruments and use only Piano. Piano stream from the midi file contains many datas like Keys, Time Signature, Chord, Note etc. We don’t require all of this except Notes and Chords to generate music. Lastly, we will return arrays of notes and chords.
Code:
def read_files(file):
notes=[]
notes_to_parse=None
#parse the midi file
midi=converter.parse(file)
#seperate all instruments from the file
instrmt=instrument.partitionByInstrument(midi)
for part in instrmt.parts:
#fetch data only of Piano instrument
if 'Piano' in str(part):
notes_to_parse=part.recurse()
#iterate over all the parts of sub stream elements
#check if element's type is Note or chord
#if it is chord split them into notes
for element in notes_to_parse:
if type(element)==note.Note:
notes.append(str(element.pitch))
elif type(element)==chord.Chord:
notes.append('.'.join(str(n) for n in element.normalOrder))
#return the list of notes
return notes
#retrieve paths recursively from inside the directories/files
file_path=["schubert"]
all_files=glob.glob('All Midi Files/'+file_path[0]+'/*.mid',recursive=True)
#reading each midi file
notes_array = np.array([read_files(i) for i in tqdm(all_files,position=0,leave=True)])3. Exploring the dataset
Let’s check how many unique notes we have and what is the distribution of these notes.
Code:
#unique notes
notess = sum(notes_array,[])
unique_notes = list(set(notess))
print("Unique Notes:",len(unique_notes))
#notes with their frequency
freq=dict(map(lambda x: (x,notess.count(x)),unique_notes))
#get the threshold frequency
for i in range(30,100,20):
print(i,":",len(list(filter(lambda x:x[1]>=i,freq.items()))))
Output:
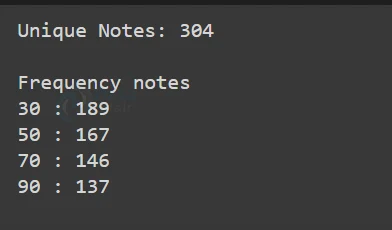
As you can see, we have 304 unique notes and most of our notes have frequencies greater than 30 or 50. It will become hard to train our model with all the notes therefore for this project we will be going to use 50 as a threshold frequency. So we will take only those notes which have frequencies more than 50. You can anytime change these parameters.
Also, we will change our ‘notes_array’ which will contain notes that are greater than threshold frequency.
Code:
#filter notes greater than threshold i.e. 50 freq_notes=dict(filter(lambda x:x[1]>=50,freq.items())) #create new notes using the frequent notes new_notes=[[i for i in j if i in freq_notes] for j in notes_array]
We are going to create two dictionaries where one will have notes index as a key and notes as value and other will be the reverse of the first i.e key will be notes and value will be its respective index. We will be going to see its use later.
Code:
#dictionary having key as note index and value as note ind2note=dict(enumerate(freq_notes)) #dictionary having key as note and value as note index note2ind=dict(map(reversed,ind2note.items()))
4. Input and Output Sequence for model
Now we will create input and output sequences for our model. We will be using a timestep of 50. So if we traverse 50 notes of our input sequence then the 51th note will be the output for that sequence. Let’s take an example to see how it works.
We will use ‘DataFlair is best for machine learning projects’ sentence and a timestep of 2. So we will provide 2 words at every input to get the output.
(x) (y)
DataFlair is, best
is best, for
for machine, learning
machine learning projects
And so on as you can see after feeding input(x) of 2 words(timesteps) our output(y) is the next word. As our model requires numeric data, we will convert all notes to its respective index value using the “note2ind” (note to index) dictionary which we have created earlier.
Code:
#timestep timesteps=50 #store values of input and output x=[] ; y=[] for i in new_notes: for j in range(0,len(i)-timesteps): #input will be the current index + timestep #output will be the next index after timestep inp=i[j:j+timesteps] ; out=i[j+timesteps] #append the index value of respective notes x.append(list(map(lambda x:note2ind[x],inp))) y.append(note2ind[out]) x_new=np.array(x) y_new=np.array(y)
5. Training and Testing sets
We will reshape our array for our model and split the data into 80:20 ratio. 80% for the training set and 20% for the testing set.
Code:
#reshape input and output for the model x_new = np.reshape(x_new,(len(x_new),timesteps,1)) y_new = np.reshape(y_new,(-1,1)) #split the input and value into training and testing sets #80% for training and 20% for testing sets x_train,x_test,y_train,y_test = train_test_split(x_new,y_new,test_size=0.2,random_state=42)
6. Building the model
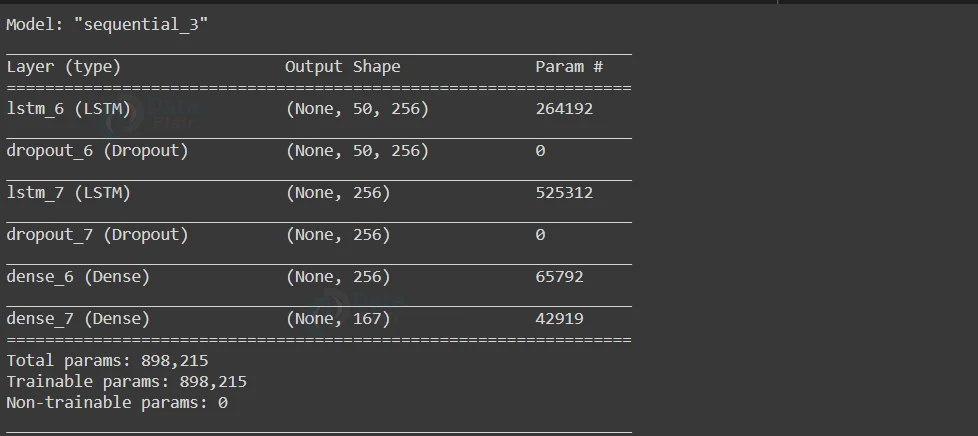
As we have discussed earlier we are going to use LSTM model architecture. We will use 2 stacked LSTM layers with a dropout rate of 0.2. Dropout basically prevents overfitting while training the model, while it does not affect the inference model. Finally we will be using a fully connected Dense layer for output.
Output dimension of the Dense Layer will be equal to the length of our unique notes along with the ‘softmax’ activation function which is used for multi-class classification problems.
Code:
#create the model model = Sequential() #create two stacked LSTM layer with the latent dimension of 256 model.add(LSTM(256,return_sequences=True,input_shape=(x_new.shape[1],x_new.shape[2]))) model.add(Dropout(0.2)) model.add(LSTM(256)) model.add(Dropout(0.2)) model.add(Dense(256,activation='relu')) #fully connected layer for the output with softmax activation model.add(Dense(len(note2ind),activation='softmax')) model.summary()
Output:
7) Train the Model
After building the model, we will now train it on the input and output data. For this will be using ‘Adam’ optimizer on batch size of 128 and for total 80 epochs.
Code:
#compile the model using Adam optimizer model.compile(loss='sparse_categorical_crossentropy', optimizer='adam',metrics=['accuracy']) #train the model on training sets and validate on testing sets model.fit( x_train,y_train, batch_size=128,epochs=80, validation_data=(x_test,y_test))
After we finish training let’s save the model for prediction.
Code:
#save the model for predictions
model.save("s2s")Output:
8) Inference (sampling) phase.
In this section we will finally compose our own music. Using the trained model we will predict the notes.
Firstly generate a random integer(index) for our testing input array which will be our testing input pattern. We will reshape our array and predict the output. Using the ‘np.argmax()’ function, we will get the data of the maximum probability value. Convert this predicted index to notes using ‘ind2note’(index to note) dictionary. Our next music pattern will be one step ahead of the previous pattern. Repeat this process till we generate 200 notes. Again you can change this parameter as per your requirements.
Code:
#load the model model = load_model(“s2s”) #generate random index index = np.random.randint(0,len(x_test)-1) #get the data of generated index from x_test music_pattern = x_test[index] out_pred=[] #it will store predicted notes #iterate till 200 note is generated for i in range(200): #reshape the music pattern music_pattern = music_pattern.reshape(1,len(music_pattern),1) #get the maximum probability value from the predicted output pred_index = np.argmax(model.predict(music_pattern)) #get the note using predicted index and #append to the output prediction list out_pred.append(ind2note[pred_index]) music_pattern = np.append(music_pattern,pred_index) #update the music pattern with one timestep ahead music_pattern = music_pattern[1:]
9) Saving the file
Finally, we are ready with the predicted output notes. Now we will save them into a MIDI file.
Code:
output_notes = []
for offset,pattern in enumerate(out_pred):
#if pattern is a chord instance
if ('.' in pattern) or pattern.isdigit():
#split notes from the chord
notes_in_chord = pattern.split('.')
notes = []
for current_note in notes_in_chord:
i_curr_note=int(current_note)
#cast the current note to Note object and
#append the current note
new_note = note.Note(i_curr_note)
new_note.storedInstrument = instrument.Piano()
notes.append(new_note)
#cast the current note to Chord object
#offset will be 1 step ahead from the previous note
#as it will prevent notes to stack up
new_chord = chord.Chord(notes)
new_chord.offset = offset
output_notes.append(new_chord)
else:
#cast the pattern to Note object apply the offset and
#append the note
new_note = note.Note(pattern)
new_note.offset = offset
new_note.storedInstrument = instrument.Piano()
output_notes.append(new_note)
#save the midi file
midi_stream = stream.Stream(output_notes)
midi_stream.write('midi', fp='pred_music.mid')You can listen the predicted music from the Shared Codes of this project.
Summary
We built a model for Automatic Music Generation. It predicted for every input note at different timesteps. The accuracy of the model is 80%, which is quite good as we have taken a midi file from only one composer. You can try with more composers which will increase the model accuracy.
Did we exceed your expectations?
If Yes, share your valuable feedback on Google




