



Wondering how Hadoop HDFS manages file read operation over it when requested by the client?
In this article, we will study how HDFS data read operation is performed in Hadoop, how the client interacts with master and slave nodes in HDFS for data read. The article also describes the internals of Hadoop HDFS data read operations.
A brief introduction to HDFS
HDFS follows Write Once Read Many philosophies. So we cannot edit files already stored in HDFS, but we can append new data to these files by re-opening them.
To read the files stored in HDFS, the HDFS client interacts with the NameNode and DataNode.
Before beginning with the HDFS read operation, let’s have a short introduction to the following components:
- HDFS Client: On user behalf, HDFS client interacts with NameNode and Datanode to fulfill user requests.
- NameNode: NameNode is the master node that stores metadata about block locations, blocks of a file, etc. This metadata is used for file read and write operation.
- DataNode: DataNodes are the slave nodes in HDFS. They store actual data (data blocks).
Refer to HDFS architecture article to study HDFS, DataNodes, and NameNodes in detail.
Let us now see how the HDFS client interacts with the NameNode and DataNode with the help of an example.
HDFS read operation
Suppose the HDFS client wants to read a file “File.txt”. Let the file be divided into two blocks say, A and B. The following steps will take place during the file read:
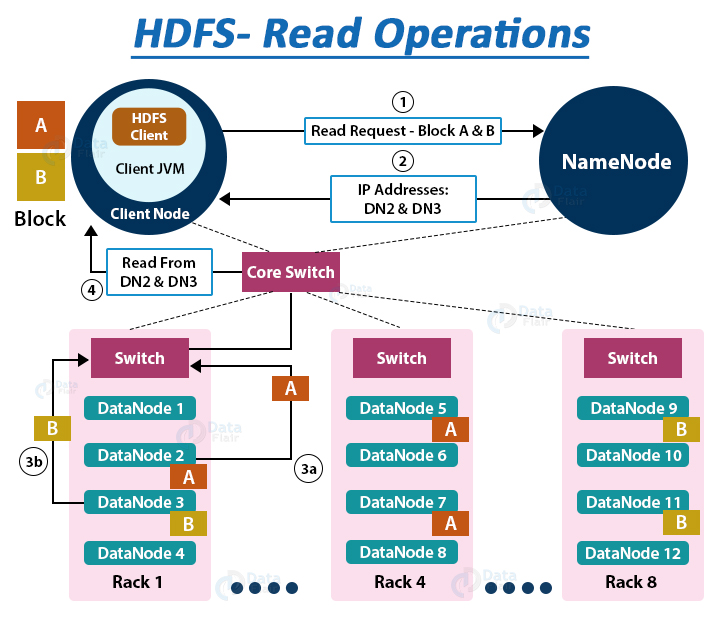
1. The Client interacts with HDFS NameNode
- As the NameNode stores the block’s metadata for the file “File.txt’, the client will reach out to NameNode asking locations of DataNodes containing data blocks.
- The NameNode first checks for required privileges, and if the client has sufficient privileges, the NameNode sends the locations of DataNodes containing blocks (A and B). NameNode also gives a security token to the client, which they need to show to the DataNodes for authentication. Let the NameNode provide the following list of IPs for block A and B – for block A, location of DataNodes D2, D5, D7, and for block B, location of DataNodes D3, D9, D11.
To perform various HDFS operations (read, write, copy, move, change permission, etc.) follow HDFS command list.
2. The client interacts with HDFS DataNode
- After receiving the addresses of the DataNodes, the client directly interacts with the DataNodes. The client will send a request to the closest DataNodes (D2 for block A and D3 for block B) through the FSDataInputstream object. The DFSInputstream manages the interaction between client and DataNode.
- The client will show the security tokens provided by NameNode to the DataNodes and start reading data from the DataNode. The data will flow directly from the DataNode to the client.
- After reading all the required file blocks, the client calls close() method on the FSDataInputStream object.
Now let us see how internally read operation is carried out in Hadoop HDFS, how data flows between the client, the NameNode, and DataNodes during file read.
Internals of file read in HDFS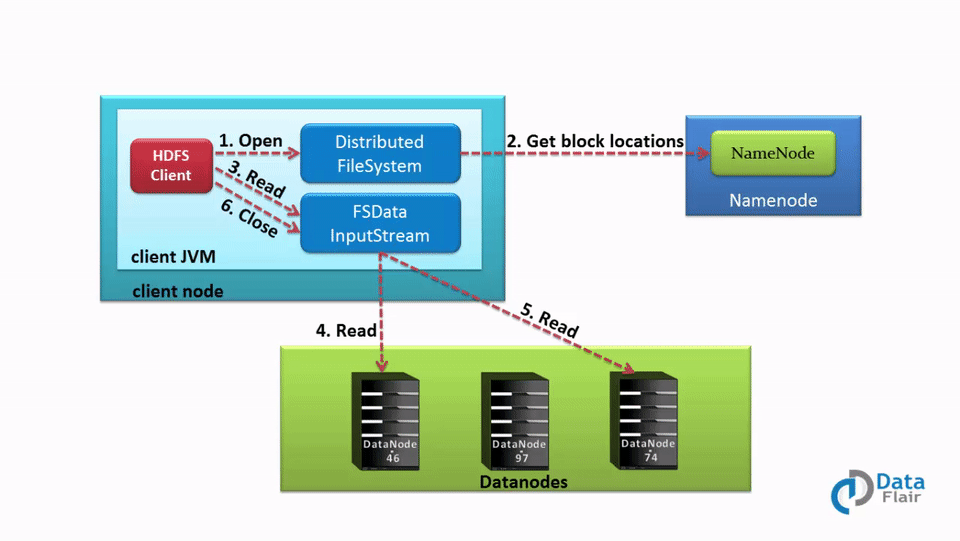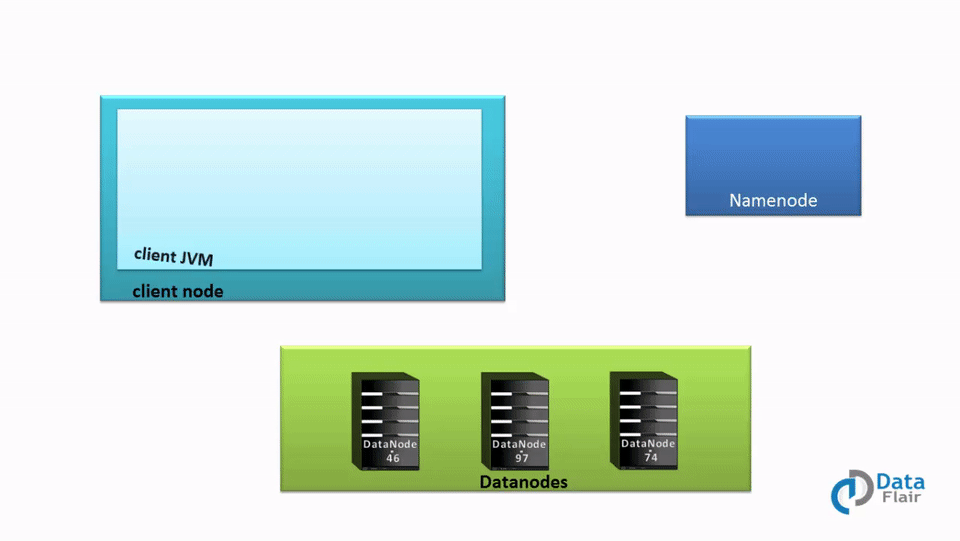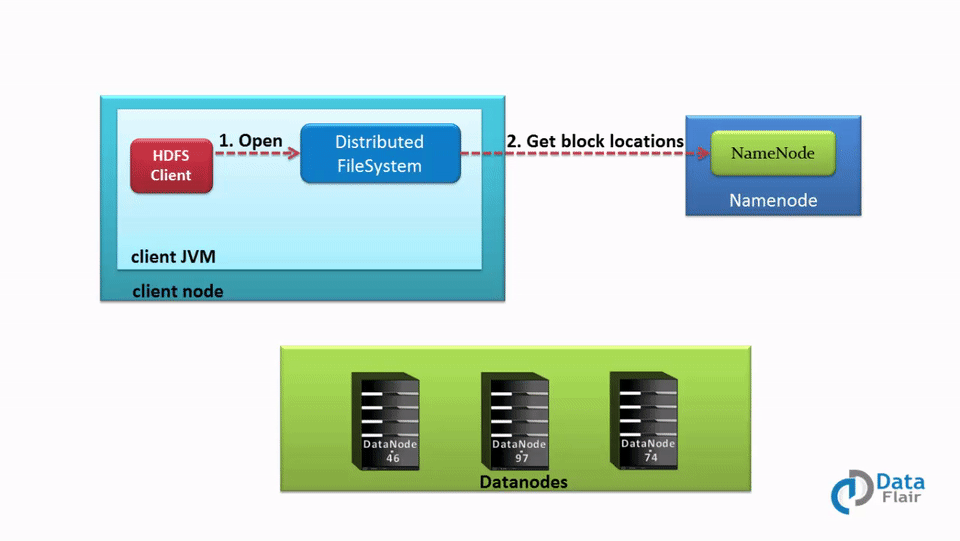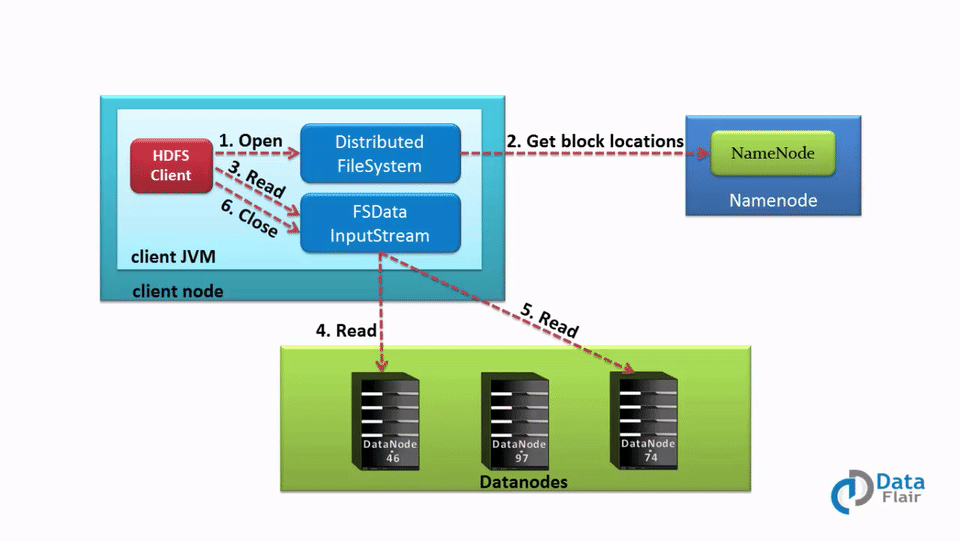
- In order to open the required file, the client calls the open() method on the FileSystem object, which for HDFS is an instance of DistributedFilesystem.
- DistributedFileSystem then calls the NameNode using RPC to get the locations of the first few blocks of a file. For each data block, NameNode returns the addresses of Datanodes that contain a copy of that block. Furthermore, the DataNodes are sorted based on their proximity to the client.
- The DistributedFileSystem returns an FSDataInputStream to the client from where the client can read the data. FSDataInputStream in succession wraps a DFSInputStream. DFSInputStream manages the I/O of DataNode and NameNode.
- Then the client calls the read() method on the FSDataInputStream object.
- The DFSInputStream, which contains the addresses for the first few blocks in the file, connects to the closest DataNode to read the first block in the file. Then, the data flows from DataNode to the client, which calls read() repeatedly on the FSDataInputStream.
- Upon reaching the end of the file, DFSInputStream closes the connection with that DataNode and finds the best suited DataNode for the next block.
- If the DFSInputStream during reading, faces an error while communicating with a DataNode, it will try the other closest DataNode for that block. DFSInputStream will also remember DataNodes that have failed so that it doesn’t needlessly retry them for later blocks. Also, the DFSInputStream verifies checksums for the data transferred to it from the DataNode. If it finds any corrupt block, it reports this to the NameNode and reads a copy of the block from another DataNode.
- When the client has finished reading the data, it calls close() on the FSDataInputStream.
How to Read a file from HDFS – Java Program
A sample code to read a file from HDFS is as follows (To perform HDFS read and write operations:
FileSystem fileSystem = FileSystem.get(conf);
Path path = new Path("/path/to/file.ext");
if (!fileSystem.exists(path)) {
System.out.println("File does not exists");
return;
}
FSDataInputStream in = fileSystem.open(path);
int numBytes = 0;
while ((numBytes = in.read(b))> 0) {
System.out.prinln((char)numBytes));// code to manipulate the data which is read
}
in.close();
out.close();
fileSystem.close();
Summary
So in this article, we have studied the data flow between client, DataNode, and NameNode during a client read request.
Now you have a pretty good idea about the HDFS file read operation and how the client interacts with DataNode and NameNode.
Also, refer to the HDFS write operation article to study the internals of HDFS data write operations.
Doubts? Ask us below.
Keep Practicing!!