



Fault tolerance refers to the ability of the system to work or operate even in case of unfavorable conditions (like components failure).
In this DataFlair article, we will learn the fault tolerance feature of Hadoop in detail. The article describes how HDFS in Hadoop achieves fault tolerance.
Let us first see what the problems in the legacy system are.
What were the issues in legacy systems?
In legacy systems like Relational Database, all the read and write operations performed by the user, were done on a single machine.
If any of the unfavorable conditions like machine failure, RAM Crash, power down, Hard-disk failure, etc. occurs, the users have to wait until the issue gets manually corrected.
So during machine crash or failure, the user will not be able to access their data until the issues in the machine get recovered.
Also, in the legacy systems, we can store data in the range of GBs only. So to increase the data storage capacity, one has to buy a new server machine. Hence to store a vast amount of data, one has to add several numbers of server machines, which increases the cost. Hadoop Distributed File System overcomes these issues.
Let us now first see a short introduction to HDFS Fault Tolerance.
Fault Tolerance in HDFS
Fault tolerance in Hadoop HDFS refers to the working strength of a system in unfavorable conditions and how that system can handle such a situation.
HDFS is highly fault-tolerant. Before Hadoop 3, it handles faults by the process of replica creation. It creates a replica of users’ data on different machines in the HDFS cluster. So whenever if any machine in the cluster goes down, then data is accessible from other machines in which the same copy of data was created.
HDFS also maintains the replication factor by creating a replica of data on other available machines in the cluster if suddenly one machine fails.
Hadoop 3 introduced Erasure Coding to provide Fault Tolerance. Erasure Coding in HDFS improves storage efficiency while providing the same level of fault tolerance and data durability as traditional replication-based HDFS deployment.
To learn more about the world’s most reliable storage layer, follow this HDFS introductory guide.
How HDFS Fault Tolerance achieved?
Prior to Hadoop 3, the Hadoop Distributed File system achieves Fault Tolerance through the replication mechanism. Hadoop 3 came up with Erasure Coding to achieve Fault tolerance with less storage overhead.
Let us see both ways for achieving Fault-Tolerance in Hadoop HDFS.
1. Replication Mechanism
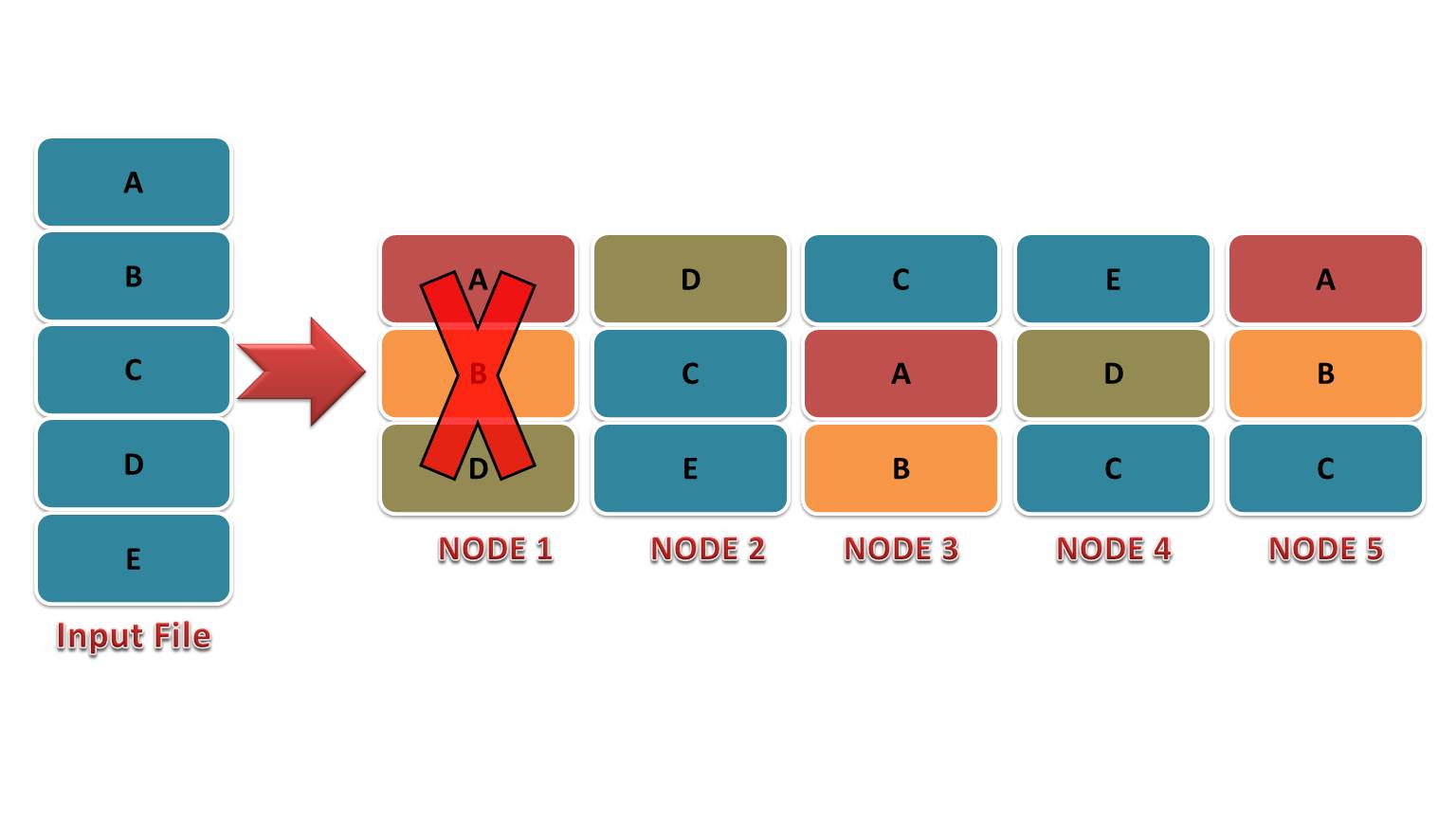
Before Hadoop 3, fault tolerance in Hadoop HDFS was achieved by creating replicas. HDFS creates a replica of the data block and stores them on multiple machines (DataNode).
The number of replicas created depends on the replication factor (by default 3).
If any of the machines fails, the data block is accessible from the other machine containing the same copy of data. Hence there is no data loss due to replicas stored on different machines.
2. Erasure Coding
Erasure coding is a method used for fault tolerance that durably stores data with significant space savings compared to replication.
RAID (Redundant Array of Independent Disks) uses Erasure Coding. Erasure coding works by striping the file into small units and storing them on various disks.
For each strip of the original dataset, a certain number of parity cells are calculated and stored. If any of the machines fails, the block can be recovered from the parity cell. Erasure coding reduces the storage overhead to 50%.
To learn in detail about Erasure coding, go through the erasure coding article.
Example of HDFS Fault Tolerance
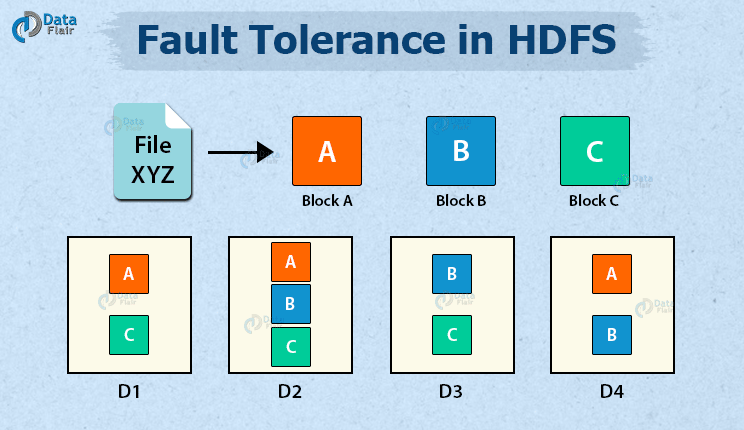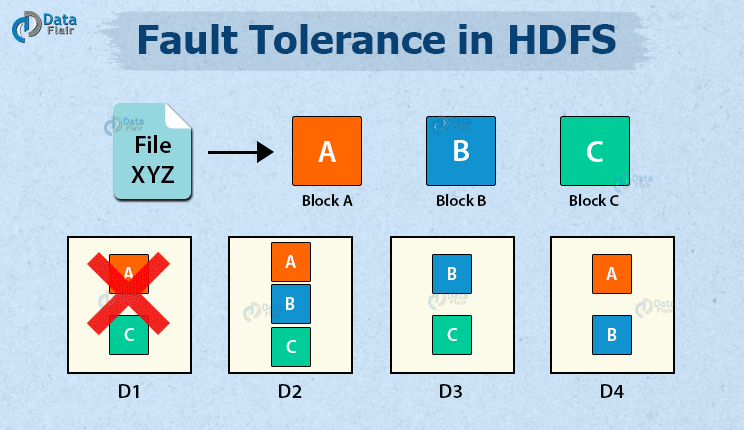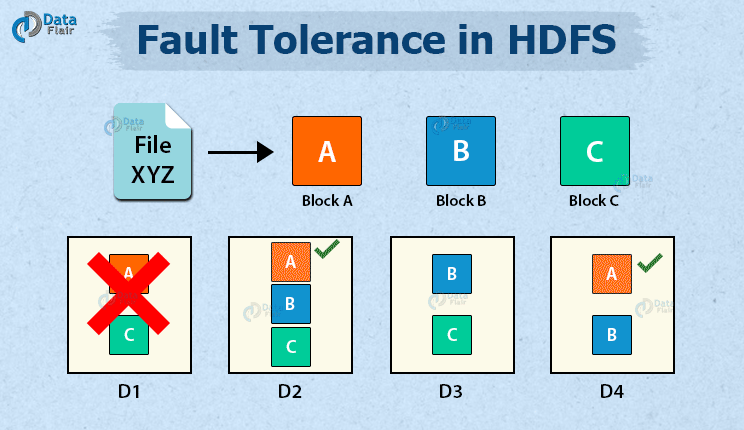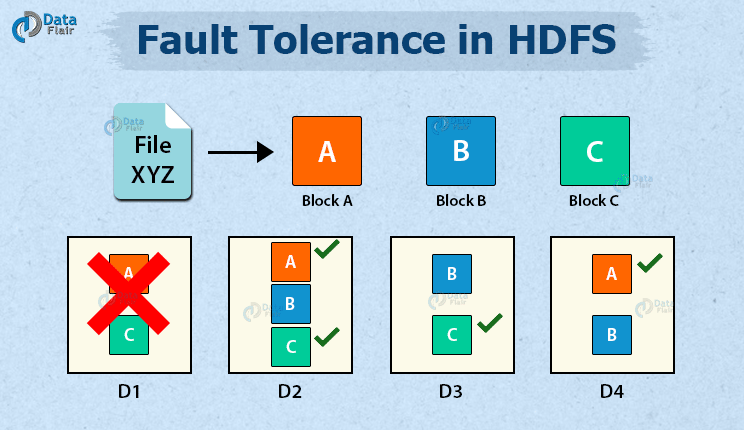
Suppose the user stores a file XYZ. HDFS breaks this file into blocks, say A, B, and C. Let’s assume there are four DataNodes, say D1, D2, D3, and D4. HDFS creates replicas of each block and stores them on different nodes to achieve fault tolerance. For each original block, there will be two replicas stored on different nodes (replication factor 3).
Let the block A be stored on DataNodes D1, D2, and D4, block B stored on DataNodes D2, D3, and D4, and block C stored on DataNodes D1, D2, and D3.
If DataNode D1 fails, the blocks A and C present in D1 are still available to the user from DataNodes (D2, D4 for A) and (D2, D3 for C).
Hence even in unfavorable conditions, there is no data loss.
Summary
The article explains the fault tolerance feature of Hadoop with an example. In this article, we have also enlisted the mechanism to achieve fault tolerance in Hadoop.
Hope you understand the concept of fault tolerance in HDFS.
Looking for HDFS Hands-on, follow top 10 Useful Hdfs Commands to perform different file operations.
Any query? Comment down below.
Happy Learning!!