


High Availability was a new feature added to Hadoop 2.x to solve the Single point of failure problem in the older versions of Hadoop.
As the Hadoop HDFS follows the master-slave architecture where the NameNode is the master node and maintains the filesystem tree. So HDFS cannot be used without NameNode. This NameNode becomes a bottleneck. HDFS high availability feature addresses this issue.
In this article, we will discuss the following points of Hadoop High Availability feature in detail:
- What is high availability?
- Introduction to High availability in Hadoop
- How Hadoop achieves High Availability?
- Reason for introducing High Availability Architecture
- NameNode High Availability Architecture
- Implementation of NameNode High Availability Architecture
- Fencing of NameNode
[ps2id id=’high-availability’ target=”/]What is high availability?
High availability refers to the availability of system or data in the wake of component failure in the system.
[ps2id id=’High-availability-in-Hadoop’ target=”/]High availability in Hadoop
The high availability feature in Hadoop ensures the availability of the Hadoop cluster without any downtime, even in unfavorable conditions like NameNode failure, DataNode failure, machine crash, etc.
It means if the machine crashes, data will be accessible from another path.
[ps2id id=’How-Hadoop-achieves’ target=”/]How Hadoop HDFS achieves High Availability?
As we know, HDFS (Hadoop distributed file system) is a distributed file system in Hadoop. HDFS stores users’ data in files and internally, the files are split into fixed-size blocks. These blocks are stored on DataNodes. NameNode is the master node that stores the metadata about file system i.e. block location, different blocks for each file, etc.
1. Availability if DataNode fails
- In HDFS, replicas of files are stored on different nodes.
- DataNodes in HDFS continuously sends heartbeat messages to NameNode every 3 seconds by default.
- If NameNode does not receive a heartbeat from DataNode within a specified time (10 minutes by default), the NameNode considers the DataNode to be dead.
- NameNode then checks for the data in DataNode and initiates data replication. NameNode instructs the DataNodes containing a copy of that data to replicate that data on other DataNodes.
- Whenever a user requests to access his data, NameNode provides the IP of the closest DataNode containing user data. Meanwhile, if DataNode fails, the NameNode redirects the user to the other DataNode containing a copy of the same data. The user requesting for data read, access the data from other DataNodes containing a copy of data, without any downtime. Thus cluster is available to the user even if any of the DataNodes fails.
2. Availability if NameNode fails
NameNode is the only node that knows the list of files and directories in a Hadoop cluster. “The filesystem cannot be used without NameNode”.
The addition of the High Availability feature in Hadoop 2 provides a fast failover to the Hadoop cluster. The Hadoop HA cluster consists of two NameNodes (or more after Hadoop 3) running in a cluster in an active/passive configuration with a hot standby. So, if an active node fails, then a passive node becomes the active NameNode, takes the responsibility, and serves the client request.
This allows for the fast failover to the new machine even if the machine crashes.
Thus, data is available and accessible to the user even if the NameNode itself goes down.
Let us now study the NameNode High Availability in detail.
Before going to NameNode High Availability architecture, one should know the reason for introducing such architecture.
[ps2id id=’Reason-for-introducing-High-Availability’ target=”/]Reason for introducing NameNode High Availability Architecture
Prior to Hadoop 2.0, NameNode is the single point of failure in a Hadoop cluster. This is because:
1. Each cluster consists of only one NameNode. If the NameNode fails, then the whole cluster would go down. The cluster would be available only when we either restart the NameNode or bring it on a separate machine. These had limited availability in two ways:
- The cluster would be unavailable if the machine crash until an operator restarts the NameNode.
- Planned maintenance events such as software or hardware upgrades on the NameNode, results in downtime of the Hadoop cluster.
2. The time taken by NameNode to start from cold on large clusters with many files can be 30 minutes or more. This long recovery time is a problem.
To overcome these problems Hadoop High Availability architecture was introduced in Hadoop 2.
Refer Hadoop HDFS Architecture to learn about NameNode and DataNodes in detail.
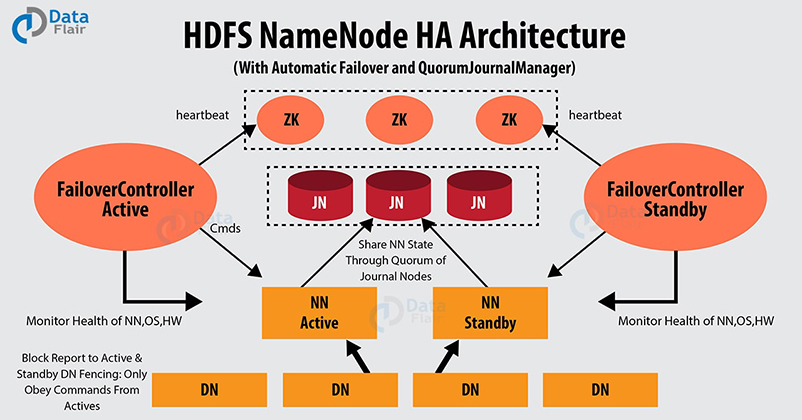
[ps2id id=’NameNode-High-Availability-Architecture’ target=”/]Hadoop NameNode High Availability Architecture

The HDFS high availability feature introduced in Hadoop 2 addressed this problem by providing the option for running two NameNodes in the same cluster in an Active/Passive configuration with a hot standby.
Thus if the running NameNode (active) goes down, then the other NameNode (passive) takes the responsibility of serving the client request without interruption.
Passive node is the standby node that acts as a slave node, having similar data as an active node. It maintains enough state to provide a fast failover.
This allows for the fast failover to a new NameNode in the case of the machine crash or during administrative initiated failure for planned maintenance.
1. Issues in maintaining consistency Of HDFS HA cluster:
There are two issues in maintaining the consistency of the HDFS high availability cluster. They are:
- The active node and the passive node should always be in sync with each other and must have the same metadata. This allows us to restore the Hadoop cluster to the same namespace where it crashed.
- Only one NameNode in the same cluster must be active at a time. If two NameNodes are active at a time, then cluster gets divided into smaller clusters, each one believing it is the only active cluster. This is known as the “Split-brain scenario” which leads to data loss or other incorrect results. Fencing is a process that ensures that only one NameNode is active at a time.
Let us now understand how these high availability clusters are being configured and managed.
[ps2id id=’Implementation-of-NameNode-High-Availability-architecture’ target=”/]Implementation of NameNode High Availability architecture
With two or more running NameNode in the same cluster, only one active at a time, we can configure and manage an HA HDFS cluster, using any of the two ways:
1. Using Quorum Journal Nodes
Quorum Journal Nodes is an HDFS implementation.
The active node and the passive nodes communicate with a group of separate daemons called “JournalNodes,” which is the lightweight process to get sync with each other.
The active node writes the edit log modification to the majority of JournalNodes.
There are generally three JournalNode daemons that allow the system to tolerate the failure of a single machine.
The system can tolerate at most (N-1) / 2 failures when running with N JournalNodes.
One should run an odd number of JNs, to increase the number of failures the system tolerates.
The active NameNode updates the edit log in the JNs.
The standby nodes, continuously watch the JNs for edit log change. Standby nodes read the changes in edit logs and apply them to their namespace.
If the active NameNode fails, the standby will ensure that it has read all the edits from JournalNodes before promoting itself to the Active state. It ensures that the NameNode state is properly synchronized before a failure occurs.
For providing fast failover, the Standby node must have up-to-date information regarding the location of blocks in the cluster. To achieve this, DataNodes have the IPs of all NameNodes and send block information and heartbeats to all.
Fencing Of NameNode:
In order to prevent the HA cluster from the “split-brain scenario,” as discussed earlier, only one NameNode should be active at a time.
Fencing is a process that ensures this property in a cluster.
In the Quorum JournalNodes implementation:
- The JournalNodes will allow only a single NameNode to be a writer at a time.
- During failover, the standby which is to become active will take over the responsibility of writing to the JournallNodes, preventing other NameNode from continuing in the active state.
- The new active node can safely proceed with failover.
2. Using Shared Storage
In this implementation, the active node and the standby nodes have access to a directory on a shared storage device in order to keep their states synchronized with each other.
During any namespace modification performed by active NameNode, active node log the modification record to an edit log file that is stored in the shared storage device.
The standby nodes constantly watch this directory for edits. When edits occur, the Standby node applies them to its own namespace.
In the case of failure, the standby node must ensure that it has read all edits from the shared directory before promoting itself to the active state. This makes the namespace state, fully synchronized before a failover occurs.
The DataNodes send heartbeat messages and block locations to all the NameNodes. It makes standby nodes to have up-to-date information about the location of blocks in the cluster.
[ps2id id=’Fencing-of-NameNode’ target=”/]Fencing of NameNode:
To prevent the HA cluster from a split-brain scenario, the administrator must configure at least one fencing method. It ensures that only one NameNode is active at a time.
The fencing method can include the killing of the NameNode process and preventing its access to the shared storage directory.
We can fence the previously active name node with one of the fencing techniques called STONITH or “shoot the other node in the head”. It uses a specialized power distribution unit to forcibly power down the NameNode machine.
Conclusion
From this article, we can conclude that after the addition of the High Availability feature to Hadoop2, there is no single point of failure in the Hadoop cluster.
The files in HDFS are accessible even in unfavorable conditions such as NameNode failure or DataNode failure. We can configure and manage an HA HDFS cluster, using either Quorum JournalNode or Shared Storage.
Planning to master Hadoop? To learn more about the world’s most reliable storage layer follow HDFS introductory guide.
Any queries about HDFS NameNode high availability?
Ask our DataFlair experts in the comment section.
Happy Learning!!