

1. Objective
In this Apache Spark tutorial, we will have a brief look at What is Apache Spark, What is the history of Spark? Apache Spark is an advanced analytics engine which can easily process real-time data. It is an in-memory processing framework which is efficient and much faster as compared to others like MapReduce. This tutorial will also cover ecosystem of Spark, Features of Apache Spark and industries those are using Apache Spark for day by day data operations.

What is Apache Spark – A Quick Guide to Drift in Spark
2. What is Apache Spark?
Earlier Hadoop MapReduce became very popular because of its efficiency to process large datasets. MapReduce is a framework which supports only Batch Processing. What if anybody wants to perform real-time analytics? What if anybody wants to process live streaming data? All these problems are addressed by a very popular data processing engine that is Apache Spark.
Spark was introduced by UC Berkeley’s in 2009, later in 2013, the project was donated to the Apache Software Foundation. Apache Spark became a top-level Apache project in 2014.
Apache Spark is an advanced analytics engine which can easily process real-time data. It is an in-memory processing framework which is efficient and much faster as compared to MapReduce. Apache Spark is highly efficient in iterative data processing. It writes the intermediate data into the memory so data need to be processed is already present in the memory so there is no need to read/write the data from disk (which saves huge disk seek time) in each step.
You can also refer this video tutorial for Apache Spark for more understanding.
3. Components of Spark
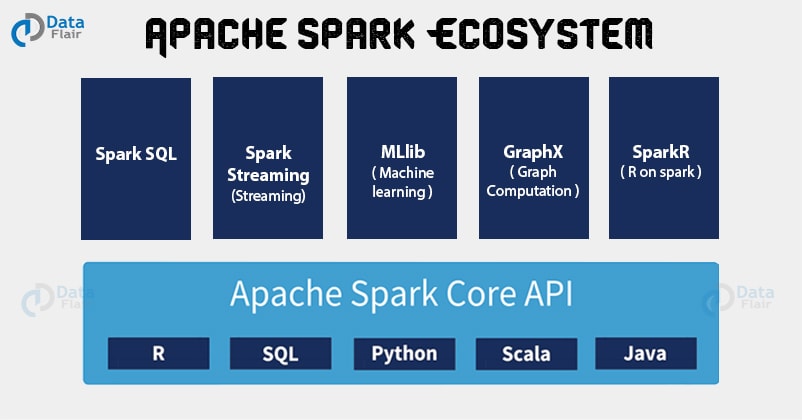
Ecosystem Components of Apache Spark
After studying what is Apache Spark, let’s now discuss the Spark Ecosystem which empowers the Spark functionality.
3.1. Spark Core
Apache Spark core is the execution engine for Spark which handles critical functionalities of Apache Spark like- memory management, task scheduling, interaction with storage systems and fault recovery. Spark core also consists of various APIs like R, Java, Python, Scala, etc. It is also a home to the APIs that define resilient distributed datasets (RDDs) which are the main programming abstraction of Apache Spark.
3.2. Spark SQL
Apache Spark SQL is built on the top of Spark core which handles querying data via SQL queries and it also supports Apache Hive variant of SQL that is Hive Query Language (HQL). Along with providing a SQL support to Spark, it also supports developers to combine SQL queries with the various programmatic data manipulations supported by RDDs in Java, Scala, and Python.
3.3. Spark Streaming
Apache Spark Streaming is the component which supports processing of live streaming of data. Spark Streaming provides the APIs which is like the Spark Core’s RDD provided by Spark Core. It helps a programmer to manipulate data stored on disk, in memory or arriving in real time.
3.4. MLlib
Spark MLlib is a library consists of common machine learning (ML) functionalities. It provides various kinds of machine learning algorithms. Spark MLlib includes regression, clustering, classification and collaborative filtering. It also provides functionality like model evaluation.
3.5. GraphX
GraphX is a library used for performing parallel computations and manipulations of graphs in Apache Spark. Spark GraphX also extends the Spark RDD APIs similarly as Spark core and Spark SQL. It allows us to create a directed graph. For manipulating graphs, GraphX provides various operators and a library of common graph algorithms.
3.6 SparkR
It is R package that gives light-weight frontend to use Apache Spark from R. The main idea behind SparkR was to explore different techniques to integrate the usability of R with the scalability of Spark. It allows data scientists to analyze large datasets and interactively run jobs on them from the R shell.
4. Feature of Apache Spark
Till now we have answered what is Apache Spark, what are the Spark ecosystem components? Now we will discuss the advantages of Apache Spark due to which Spark come into limelight. The various features of Spark are:
4.1 Speed
Speed is the reason behind the popularity of Apache Spark in various IT organizations. Since read/write operations get reduce while using Spark. Thus it is 100 times faster in memory processing and 10 times faster in disk processing.
4.2. Reusability
Apache Spark provides the provision of code reusability for batch processing, join streams against historical data, or run ad-hoc queries on stream state.
4.3. Fault tolerance
Spark and its RDD abstraction are designed to seamlessly handle failures of any worker nodes in the cluster. Thus, the loss of data and information is negligible. Follow this guide to learn Spark Fault tolerance feature in detail.
4.4 High-level Analytics
The best and unique feature of Apache Spark is its versatility. It supports Machine learning (ML), Graph algorithms, SQL queries and Streaming data along with MapReduce.
4.5 Supports Many Languages
Spark provides built-in APIs for various languages like Java, Scala or Python. Thus, it is possible to write applications in different languages.
5. Spark in Industries
IT organizations, for example, Cloudera, Pivotal, IBM, Intel, and MapR have all used Spark into their Hadoop stacks. Databricks, an organization established by a part of the developers of Spark, offers business backing for the product. Companies like Yahoo, NASA, Amazon, AutoDesk, eBay, Groupon, Taboola, TripAdvisor, Zaloni, among others, use the product for day by day data operations.
6. Conclusion
In conclusion, Apache Spark is a cluster computing platform designed to be fast, speed side and extends the popular MapReduce model to efficiently supports more type of computations, including interactive queries and stream processing. Since Spark integrates closely with other big data tool, hence this tight integration is the ability to build an application that seamlessly combines different computation model.
I hope you now you are comfortable with Spark, so try your hands on Apache Spark Quiz and test your knowledge.
For any query related to Apache Spark, please leave a comment.
See Also-
Reference:
http://spark.apache.org/