



Master Python with 70+ Hands-on Projects and Get Job-ready - Learn Python
Most of us use Twitter for contacting our friends, sharing posts, viewing and reacting to others’ posts, etc. We also use it to get to know about the topics of our interest or gather some insights. Have you ever wanted to automate your work of reading and writing Twitter data? Here is Twitter API to ease your job!
We will build a project to scrape data from Twitter using this API and Python. So, let’s get started.
What is Data Scraping?
Data Scraping is the technique of extracting web data in a format that is useful in finding the required insights or other requirements. In this project, we will be using the Twitter API (Application Programming Interface).
It is a very rich REST API for querying the system, gathering the needed information, and controlling the account. This acts as a “middleman service” between us and the Twitter application helping us to communicate with each other. Any requests we make go to the server first and the response given comes through the same route. It comes with a set of commands we can use for this purpose.
Before, all an important step we need to follow is to request an API for Twitter. Wondering how to do this? Don’t worry we guide you through the same in the coming up sections!
Scraping Data From Twitter using Python
In this project, we will be using the Tweepy module to connect to Twitter and extract its data in Python and store it in a CSV format using the Pandas module. Also, we will be building a GUI using Tkinter to get the inputs of what information to be extracted.
Download the Scraping Data From Twitter using Python Project
Please download the source code of the project scraping data from Twitter using the link: Twitter Data Scraper Project
Project Prerequisites
It is expected that the user has prior knowledge of Python. An important component that is required is the Python environment that needs to be set up. It acts as an interpreter, managing all the installed packages and running the written code.
There are many environments to choose from, with one being a standard one. You can install Python by downloading it from the Python website, if not installed yet.
Also, having a basic idea of the Tkinter module and pandas module would also help. You can install the required modules using the below commands:
pip install pandas pip install tk pip install tweetpy
Steps to build the project
We will be following the below steps to build this project:
1. Firstly, we start by requesting the Twitter API key for us to connect to Twitter. Wondering how? We will guide you through that too!
2. Now, we get to the coding part by importing all the necessary modules
3. Then we build the GUI using Tkinter
4. And write the function to extract the data based on the input given by user
Requesting the Twitter API
Twitter API gives us developer access to connect to Twitter and extract or modify data. and Here are the steps to follow to get the Twitter API:
1. Use this link to request an API by providing required inputs. It might take 2-3 hours to get the approval.
2. Once you get the approval, you will be able to see your project by going to the dashboard. And on selecting the keys and tokens option, you will be able to view the keys as shown in the below picture.
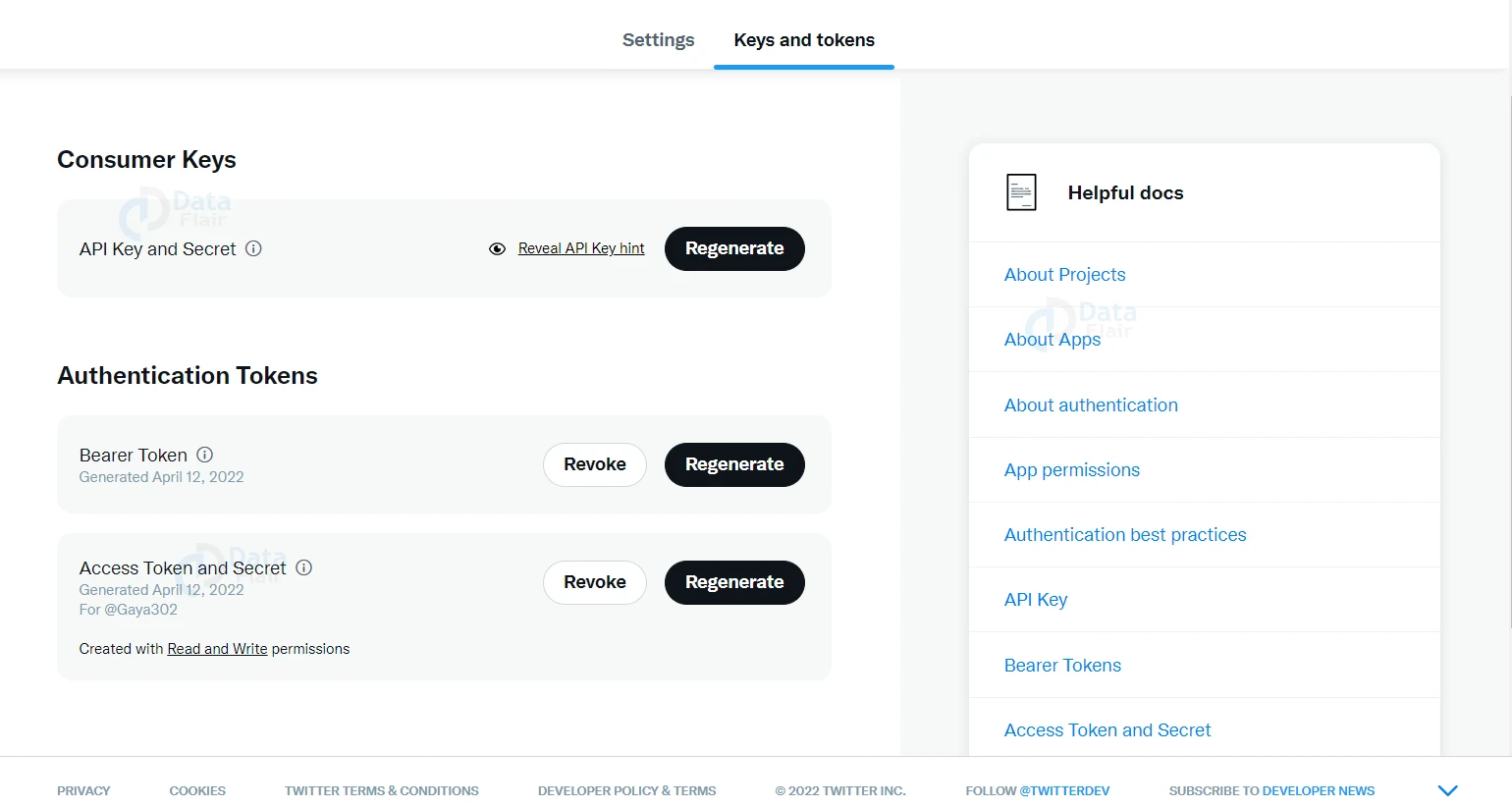
3. If you observe clearly, under the ‘Access Token and Secret’, you will be initially having ‘Created with Read Only permissions.
4. And we need to change this to ‘Read and Write’ for serving our purpose of extracting and writing data.
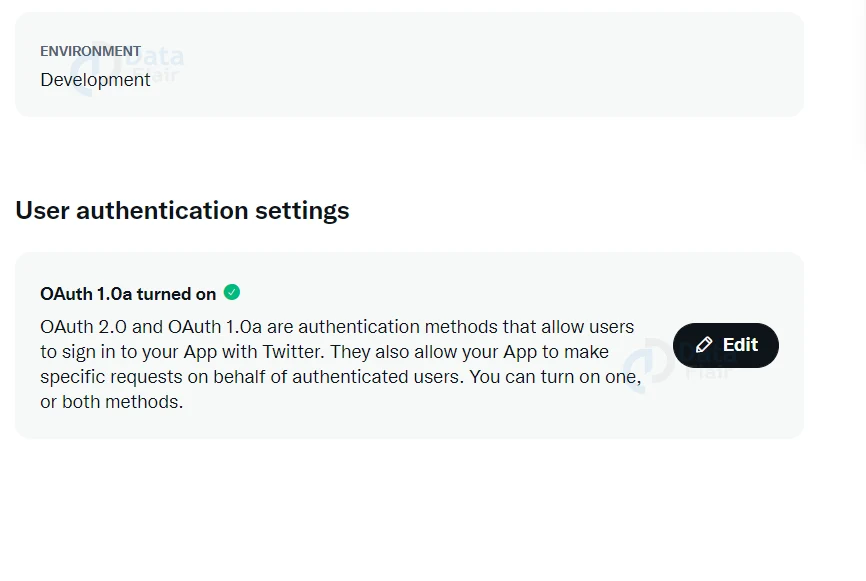
5. For this, we choose the Setting tab and click on the edit option in User authentication settings as shown in the below figure.
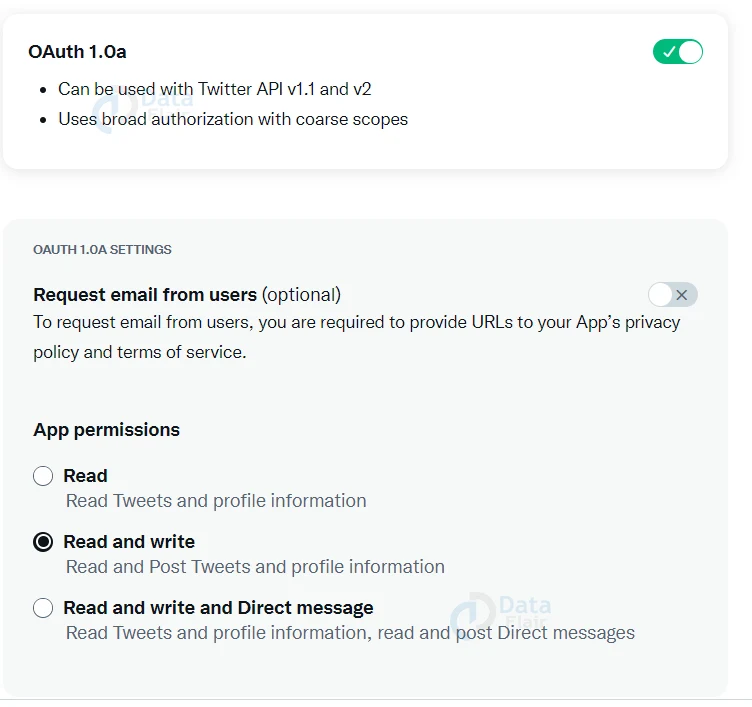
6. After this, we switch on the ‘OAuth 1.0a’, choose the ‘Read and write’ option, and save the changes.
7. And if you go back to the keys, you will observe the permissions changed to ‘Read and Write’. If not, you can regenerate the keys, and save the new ones.
Importing the modules
Here we import the pandas, tweepy, and Tkinter modules we discussed above. In addition, we also import the datetime module to give the latest tweets information.
import os import tweepy as tw import pandas as pd from datetime import datetime, timedelta from tkinter import * import base64 from tkinter import messagebox import tkinter.font as font
Creating the GUI
wn = tk.Tk()
wn.geometry("500x500")
wn.configure(bg='azure2')
wn.title("DataFlair Twitter Data Scraper")
searchWord = tk.StringVar()
direc=tk.StringVar(wn)
n=tk.IntVar(wn)
headingFrame1 = tk.Frame(wn,bg="gray91",bd=5)
headingFrame1.place(relx=0.05,rely=0.1,relwidth=0.9,relheight=0.16)
headingLabel = tk.Label(headingFrame1, text=" Welcome to DataFlair Twitter Data Srcaper", fg='grey19', font=('Courier',12,'bold'))
headingLabel.place(relx=0,rely=0, relwidth=1, relheight=1)
tk.Label(wn, text='Enter the word to be searched on twitter',bg='azure2', font=('Courier',10)).place(x=20,y=150)
tk.Entry(wn, textvariable=searchWord, width=35,font=('calibre',10,'normal')).place(x=20,y=170)
tk.Label(wn, text='Please enter number of data values you require',bg='azure2', anchor="e").place(x=20, y=200)
tk.Entry(wn,textvariable=n, width=35, font=('calibre',10,'normal')).place(x=20,y=220)
#Getting the path of the folder
tk.Label(wn, text='Please enter the folder location where csv file is to be saved',bg='azure2', anchor="e").place(x=20, y=250)
tk.Entry(wn,textvariable=direc, width=35, font=('calibre',10,'normal')).place(x=20,y=270)
ScrapeBtn = tk.Button(wn, text='Scrape', bg='honeydew2', fg='black', width=15,height=1,command=scrapeData)
ScrapeBtn['font'] = font.Font( size=12)
ScrapeBtn.place(x=15,y=350)
QuitBtn = tk.Button(wn, text='Exit', bg='old lace', fg='black',width=15,height=1, command=wn.destroy)
QuitBtn['font'] = font.Font( size=12)
QuitBtn.place(x=345,y=350)
wn.mainloop()
In this step, we create window using Tkinter and then add three entries, to take the inputs of the word to search, number of posts to store, and where to store the CSV. And then it has scrape and quit buttons which run the scrapeData() function and exit the screen respectively.
Creating the function to scrape
def scrapeData():
consumer_key= ''
consumer_secret= ''
access_token= ''
access_token_secret= ''
path = direc.get()
search_words = searchWord.get()
no=n.get()
auth = tw.OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(access_token, access_token_secret)
api = tw.API(auth, wait_on_rate_limit=True)
tweets = tw.Cursor(api.search_tweets,
q=search_words,
lang="en").items(no)
users_locs = [[tweet.created_at, tweet.id, tweet.user.screen_name,tweet.text]
for tweet in tweets]
twitterDf = pd.DataFrame(data=users_locs,
columns=['location', "id","user","Content"])
path=path+"/TwitterCSV.csv"
twitterDf.to_csv(path)
messagebox.showinfo("DataFlair Twitter Data Scraper","CSV file is saved successfully!")
Here is the main function that scrapes the data. In this, we
1. First take the inputs of path, word to search and count.
2. Then use the four keys, here empty strings are mentioned to hide the authentication and you can use your own keys, to connect to the twitter api
3. After that use the Cursor() function to extract data in the form of a iterator. The data extracted is looped to store it in the form of list.
- Strings in the twitter data prefixed with the letter “u”, called unicode strings.
For example: u”I am a string!” - It is a standard for representing a much larger variety of characters beyond the roman alphabet
- In case you encounter an error involving printing unicode, you can use the encode method to properly print the required information as shown below:
unicode_str = u"aaçççÃ&Ã"
encoded_str = unicode_string.encode('utf-8')
print(encoded_str)
4. Then convert to a data frame. Which is again stored in the form of a CSV file in the location the user gave.
5. After this, a message is shown saying the file is saved.
Python Twitter Data Scraping Output
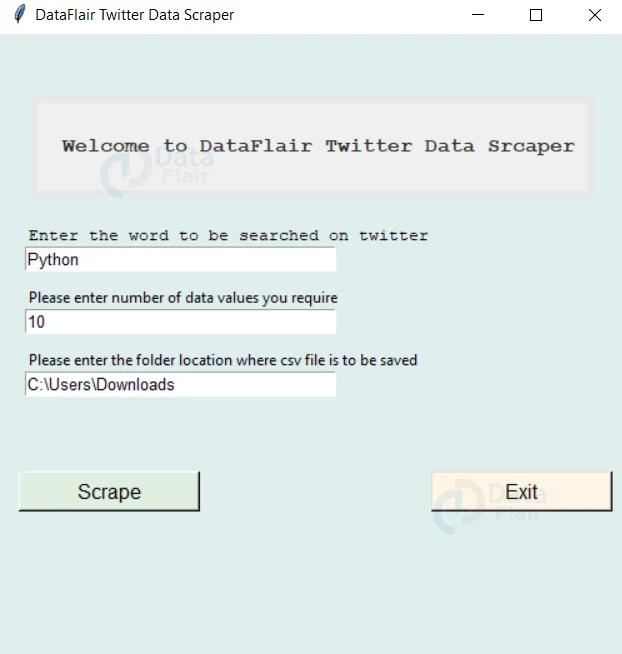
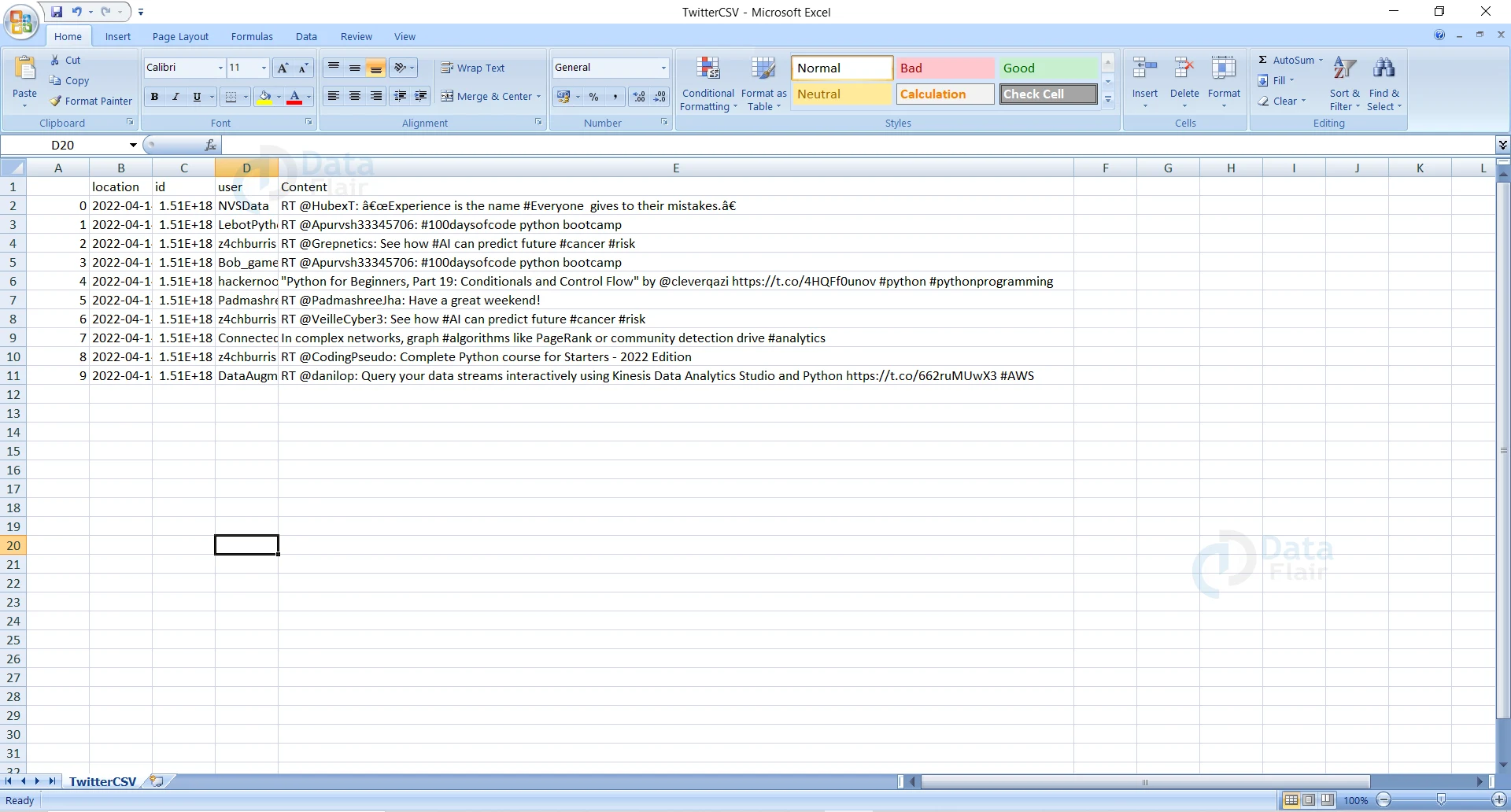
Saving as a Text
In the above GUI we created, we have saved the Twitter data in the form of a CSV file. We know that there are many other formats like this, the most famous one being a text file. Let’s also look into the way to save the information in the form of a text file using Python
Example of saving the Twitter data as a text file:
import tweepy
import json
access_token=""
access_token_secret=""
consumer_key=""
consumer_secret=""
search_words = 'Python'
no=5
auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(access_token, access_token_secret)
api = tweepy.API(auth, wait_on_rate_limit=True)
tweets = tweepy.Cursor(api.search_tweets,
q=search_words,
lang="en").items(no)
with open(r'twitter.txt', 'w', encoding='utf-8') as f:
for tweet in tweets:
f.write(str(tweet))
Conclusion
Congratulation! We have successfully learned to Scrape data from Twitter using Python. We got to use the tkinter and corresponding modules. Hope you enjoyed developing with us!