


Free Flink course with real-time projects Start Now!!
This is a comprehensive Flink guide which covers all the aspects of Flink. The Objective of this Apache Flink tutorial is to understand Flink meaning. Moreover, we will see how is Apache Flink lightning fast? Also, we will discuss Flink features and history.
At last, we will also discuss the internals of Flink Architecture and its execution model in this Apache Flink Tutorial.
So, let’s start Apache Flink Tutorial.
What is Flink?
Apache Flink is the next generation Big Data tool also known as 4G of Big Data.
- It is the true stream processing framework (doesn’t cut stream into micro-batches).
- Flink’s kernel (core) is a streaming runtime which also provides distributed processing, fault tolerance, etc.
- Flink processes events at a consistently high speed with low latency.
- It processes the data at lightning fast speed.
- It is the large-scale data processing framework which can process data generated at very high velocity.
Apache Flink is the powerful open source platform which can address following types of requirements efficiently:
- Batch Processing
- Interactive processing
- Real-time stream processing
- Graph Processing
- Iterative Processing
- In-memory processing
Flink is an alternative to MapReduce, it processes data more than 100 times faster than MapReduce. It is independent of Hadoop but it can use HDFS to read, write, store, process the data. Flink does not provide its own data storage system. It takes data from distributed storage.
Apache Flink video tutorial

Flink Tutorial – History
The development of Flink is started in 2009 at a technical university in Berlin under the stratosphere. It was incubated in Apache in April 2014 and became a top-level project in December 2014.
Flink is a German word meaning swift / Agile. The logo of Flink is a squirrel, in harmony with the Hadoop ecosystem.
Flink Tutorial – Ecosystem
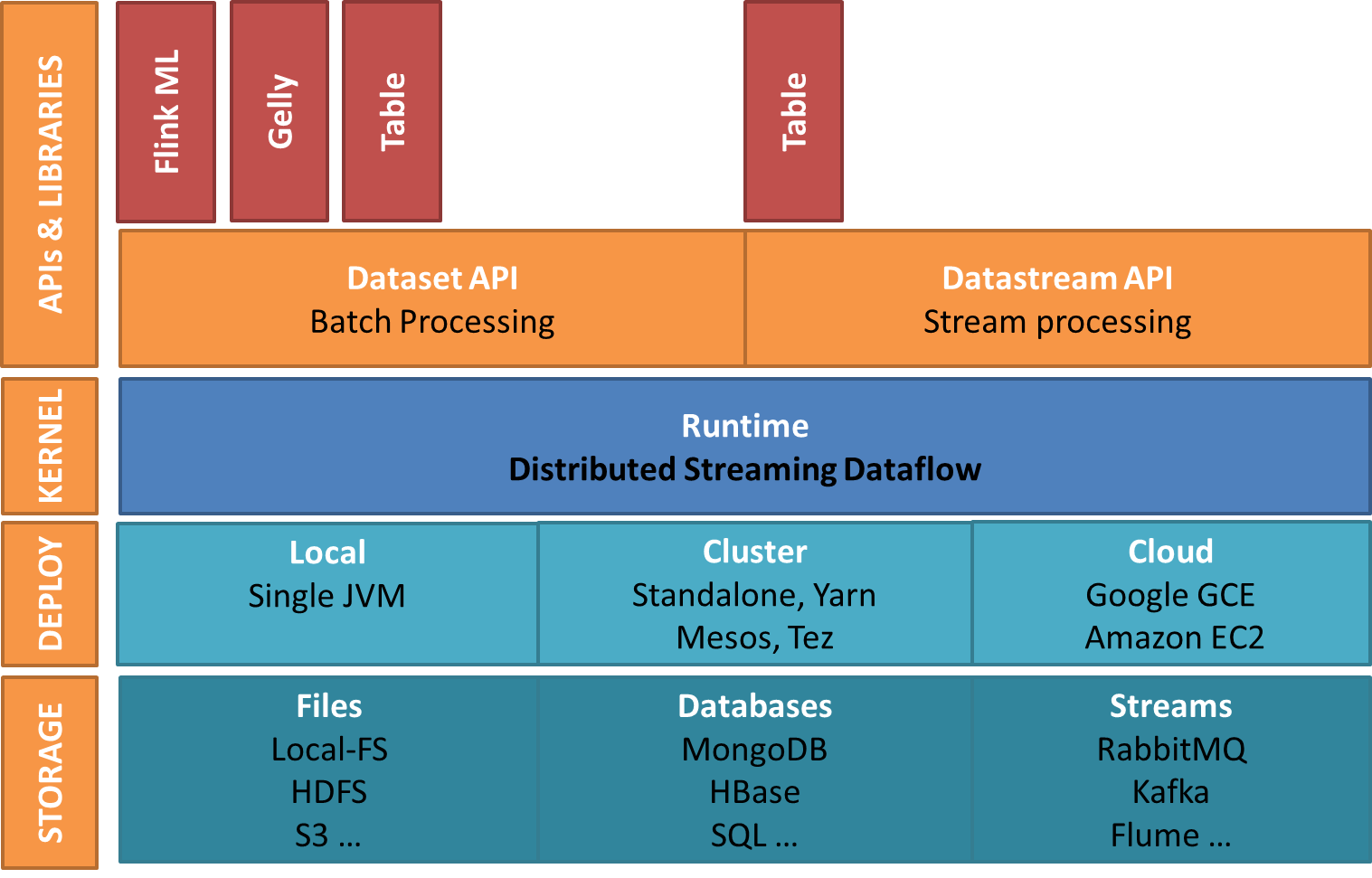
Apache Flink Tutorial- Ecosystem Components
Above diagram shows complete ecosystem of Apache Flink. There are different layers in the ecosystem diagram:
i. Storage / Streaming
Flink doesn’t ship with the storage system; it is just a computation engine. Flink can read, write data from different storage system as well as can consume data from streaming systems. Below is the list of storage/streaming system from which Flink can read write data:
- HDFS – Hadoop Distributed File System
- Local-FS – Local File System
- S3 – Simple Storage Service from Amazon
- HBase – NoSQL Database in Hadoop ecosystem
- MongoDB – NoSQL Database
- RDBMS – Any relational database
- Kafka – Distributed messaging Queue
- RabbitMQ – Messaging Queue
- Flume – Data Collection and Aggregation Tool
The second layer is the deployment/resource management. Flink can be deployed in following modes:
- Local mode – On a single node, in single JVM
- Cluster – On a multi-node cluster, with following resource manager.
- Standalone – This is the default resource manager which is shipped with Flink.
- YARN – This is a very popular resource manager, it is part of Hadoop, introduced in Hadoop 2.x
- Mesos – This is a generalized resource manager.
- Cloud – on Amazon or Google cloud
The next layer is Runtime – the Distributed Streaming Dataflow, which is also called as the kernel of Apache Flink. This is the core layer of flink which provides distributed processing, fault tolerance, reliability, native iterative processing capability, etc.
The top layer is for APIs and Library, which provides the diverse capability to Flink:
ii. DataSet API
It handles the data at the rest, it allows the user to implement operations like map, filter, join, group, etc. on the dataset. It is mainly used for distributed processing.
Actually, it is a special case of Stream processing where we have a finite data source. The batch application is also executed on the streaming runtime.
iii.DataStream API
It handles a continuous stream of the data. To process live data stream it provides various operations like map, filter, update states, window, aggregate, etc.
It can consume the data from the various streaming source and can write the data to different sinks. It supports both Java and Scala.
Now let’s discuss some DSL (Domain Specific Library) Tool’s
iv. Table
It enables users to perform ad-hoc analysis using SQL like expression language for relational stream and batch processing. It can be embedded in DataSet and DataStream APIs.
Actually, it saves users from writing complex code to process the data instead allows them to run SQL queries on the top of Flink.
v. Gelly
It is the graph processing engine which allows users to run set of operations to create, transform and process the graph. Gelly also provides the library of an algorithm to simplify the development of graph applications.
It leverages native iterative processing model of Flink to handle graph efficiently. Its APIs are available in Java and Scala.
vi. FlinkML
It is the machine learning library which provides intuitive APIs and an efficient algorithm to handle machine learning applications. We write it in Scala.
As we know machine learning algorithms are iterative in nature, Flink provides native support for iterative algorithm to handle the same quite effectively and efficiently.
To use Above APIs and start working on Flink follow this use-case guide.
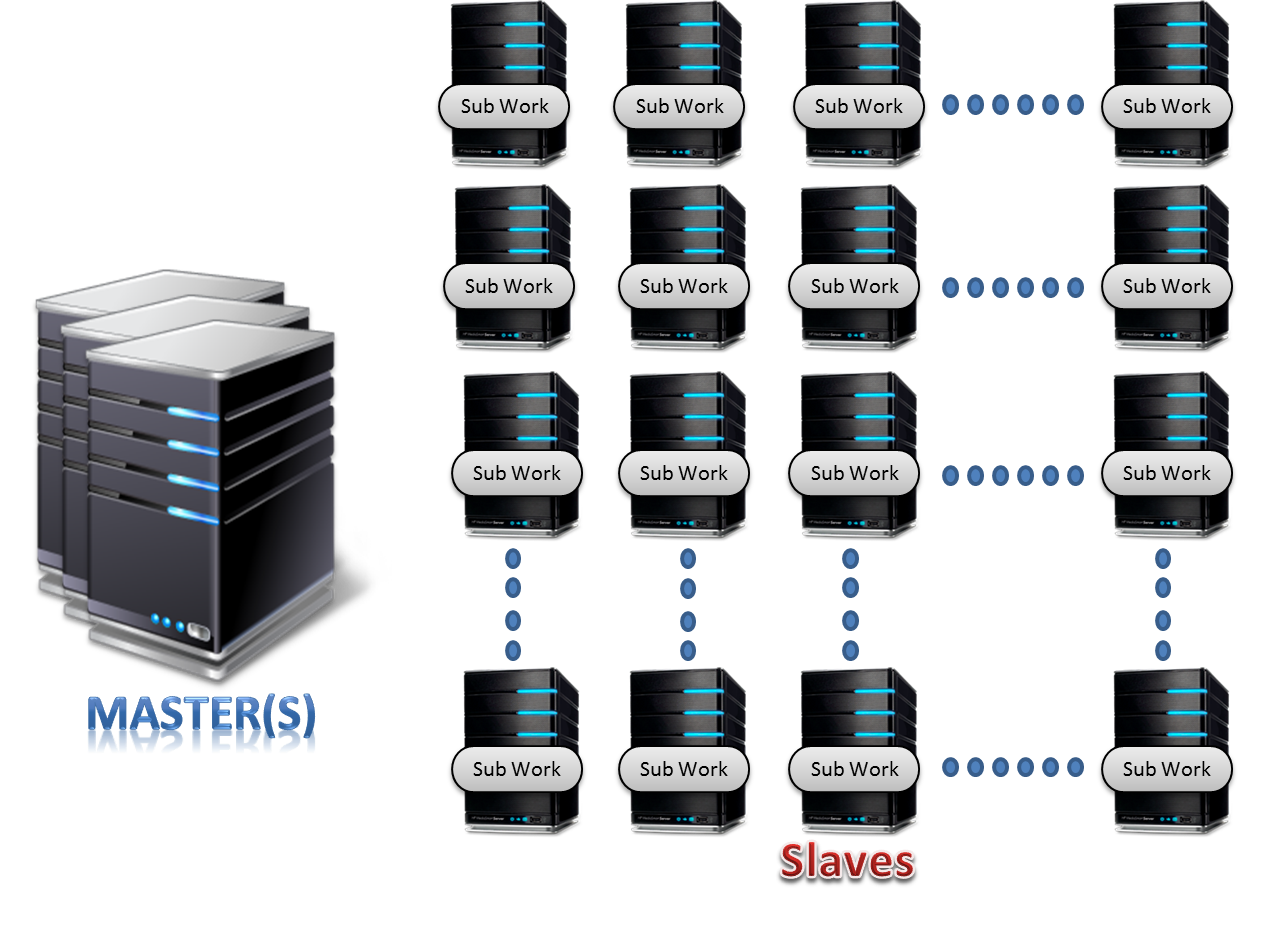
Flink Architecture
Apache Flink tutorial- Flink Architecture
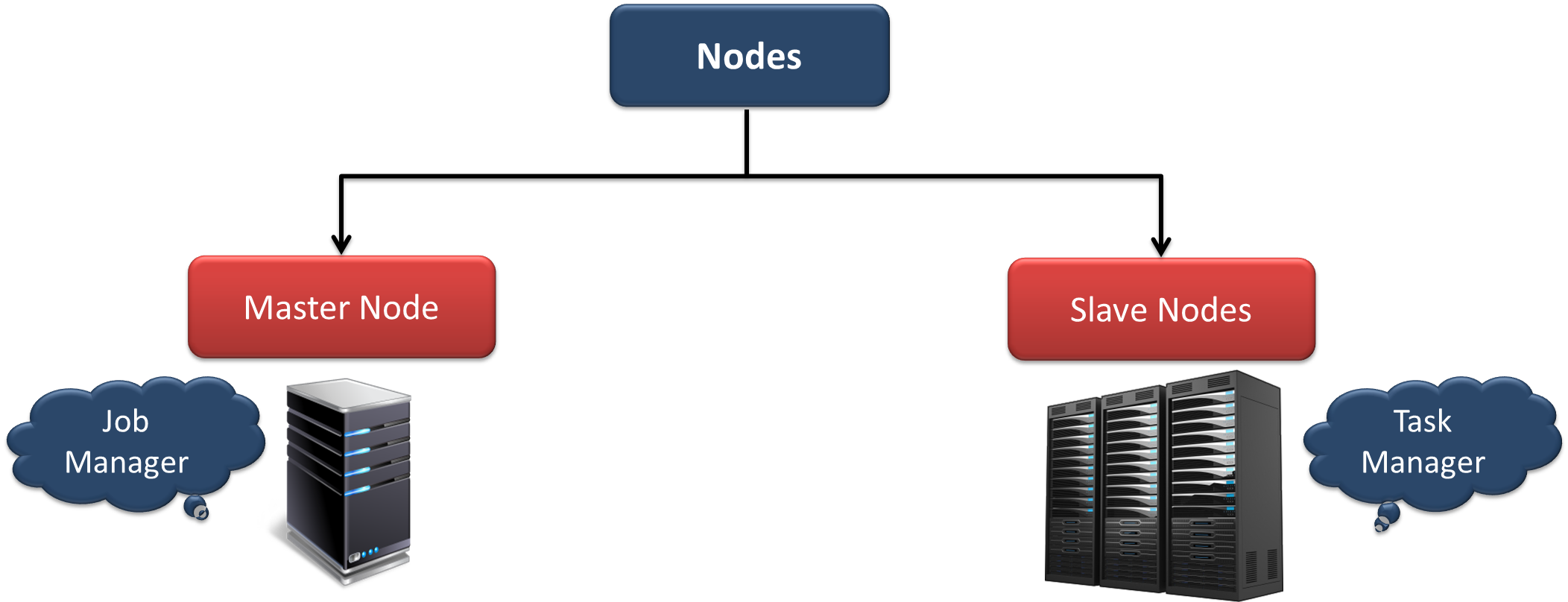
apache flink tutorial – Flink node daemons
Flink works in Master-slave fashion. Master is the manager node of the cluster where slaves are the worker nodes. As shown in the figure master is the centerpiece of the cluster where the client can submit the work/job /application.
Now the master will divide the work and submit it to the slaves in the cluster. In this manner, Flink enjoys distributed computing power which allows Flink to process the data at lightning fast speed.
There are two types of nodes a master and slave node. On master node we configure the master daemon of Flink called “Job Manager” runs, and on all the slave nodes the slave daemon of the Flink called “Node Manager”.
Flink Features
Let’s now learn features of Apache Flink in this Apache Flink tutorial-
- Streaming – Flink is a true stream processing engine.
- High performance – Flink’s data streaming Runtime provides very high throughput.
- Low latency – Flink can process the data in sub-second range without any delay/
- Event Time and Out-of-Order Events – Flink supports stream processing and windowing where events arrive delayed or out of order.
- Lightning fast speed – Flink processes data at lightning fast speed (hence also called as 4G of Big Data).
- Fault Tolerance – Failure of hardware, node, software or a process doesn’t affect the cluster.
- Memory management – Flink works in managed memory and never get out of memory exception.
- Broad integration – Flink can be integrated with the various storage system to process their data, it can be deployed with various resource management tools. It can also be integrated with several BI tools for reporting.
- Stream processing – Flink is a true streaming engine, can process live streams in the sub-second interval.
- Program optimizer – Flink is shipped with an optimizer, before execution of a program it is optimized.
- Scalable – Flink is highly scalable. With increasing requirements, we can scale the flink cluster.
- Rich set of operators – Flink has lots of pre-defined operators to process the data. All the common operations can be done using these operators.
- Exactly-once Semantics – It can maintain custom state during computation.
- Highly flexible Streaming Windows – In flink we can customize windows by triggering conditions flexibly, to get the required streaming patterns. We can create window according to time t1 to t5 and data-driven windows.
- Continuous streaming model with backpressure – Data streaming applications are executed with continuous (long-lived) operators. Flink’s streaming engine naturally handles backpressure.
- One Runtime for Streaming and Batch Processing – Batch processing and data streaming both have common runtime in flink.
- Easy and understandable Programmable APIs – Flink’s APIs are developed in a way to cover all the common operations, so programmers can use it efficiently.
- Little tuning required – Requires no memory, network, serializer to configure.
Flink Tutorial- Dataset Transformations
- Map – It takes 1 element as input and produces 1 element as output.
- FlatMap – It takes 1 element and produces 0 or more elements as output.
- Filter – Evaluate a boolean expression for each element and retains those records which return true.
- KeyBy – Partitions the data into disjoint partitions each has elements of the same key.
- Union, Join, Split, select, window, etc.. are the common operators we use to process the data
Flink Execution Model
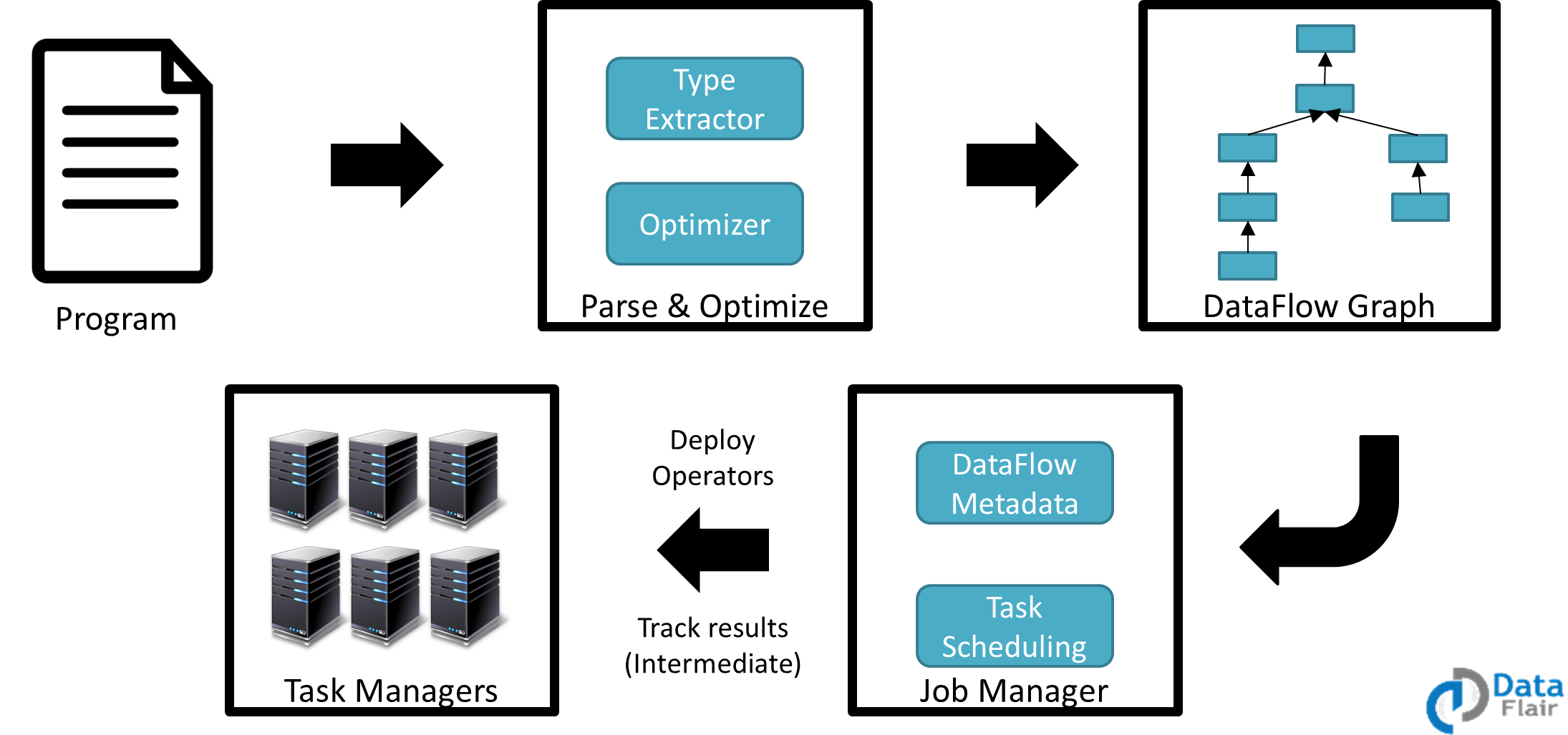
Apache flink Tutorial – Flink execution model
As shown in the figure the following are the steps to execute the applications in Flink:
- Program – Developer wrote the application program.
- Parse and Optimize – The code parsing, Type Extractor, and Optimization are done during this step.
- DataFlow Graph – Each and every job converts into the data flow graph.
- Job Manager – Now job manager schedules the task on the task managers; keeps the data flow metadata. Job manager deploys the operators and monitors the intermediate task results
- Task Manager – The tasks are executed on the task manager, they are the worker nodes.
Flink Tutorial- Execution Engine
The core of flink is the scalable and distributed streaming data flow engine withthe following features:
- True Streaming – It executes every application as a streaming application.
- Versatile – Engine allows to run existing MapReduce, Storm, Cascading applications
- Native support for iterative execution – It allows cyclic data flows natively
- Custom memory manager – We operate Flink on managed memory
- Cost based optimizer – Flink has optimizer for both DataSet and DataStream APIs.
- BYOS – Bring Your Own Storage. Flink can use any storage system to process the data
- BYOC – Bring Your Own Cluster. We can deploy Flink on different cluster managers.
Conclusion – Flink Tutorial
Hence, in this Apache Flink Tutorial, we discussed the meaning of Flink. Moreover, we saw Flink features, history, and the ecosystem. Also, we discussed dataset transformations, the execution model and engine in Flink.
In this Flink tutorial, we have also given a video of Flink tutorial, which will help you to clear your Flink concepts. Do watch that video and share your feedback with us.