



Free Flink course with real-time projects Start Now!!
This step by step tutorial will explain how to create an Apache Flink project in Eclipse and how to submit the application after the creation of jar.
Learn how to configure a development environment for developing Apache Flink Application. If you want to learn more about Apache Flink you can refer this Apache Flink introduction guide.
How to Create an Apache Flink Application in Java?
Apache Flink is an open source framework and distributed processing engine. Flink can be stateful computation over bounded and unbounded data streams. It is specially designed to run in all common cluster environments and perform computations at any scale and in-memory.
Here, we will learn the step by step to create an Apache Flink application in java in eclipse-
- Platform
- Create a project
- Make a class WordCount
- Copy wordcount code in an editor
- Export Apache Flink jar file
- Go to the Flink home directory
- Sample data
- Submit Flink application
- Output
i. Platform
- Operating system: Ubuntu (or any flavor of Linux)
- Java 7.x or higher
- Eclipse – Latest version
ii. Steps to Create Project
a. Create a new java project
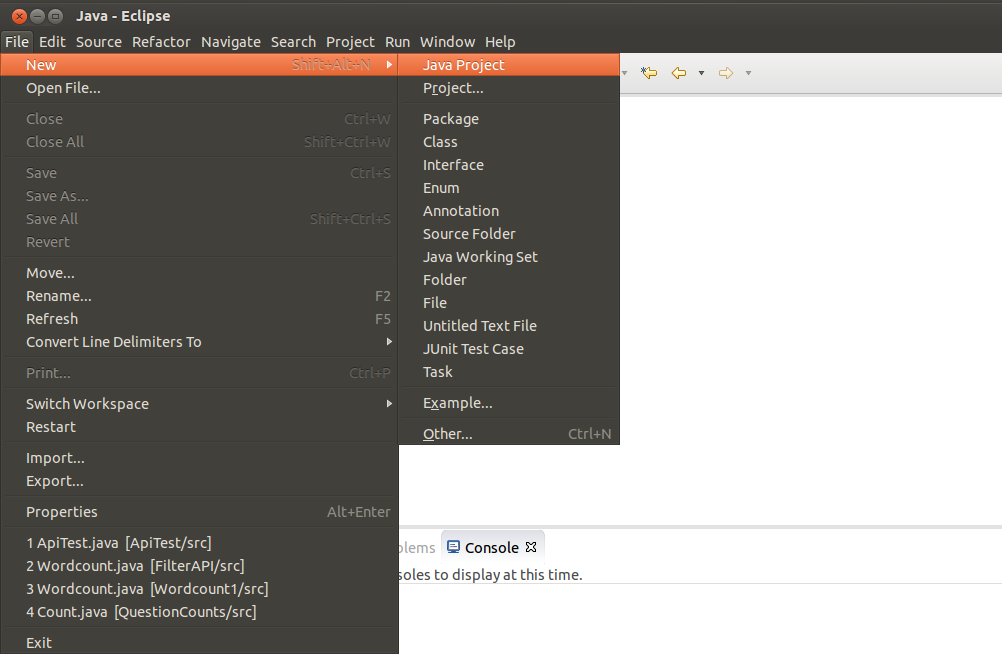
Apache Flink Application – make new project
b. You can name the project as WordCount or with a name of your choice.
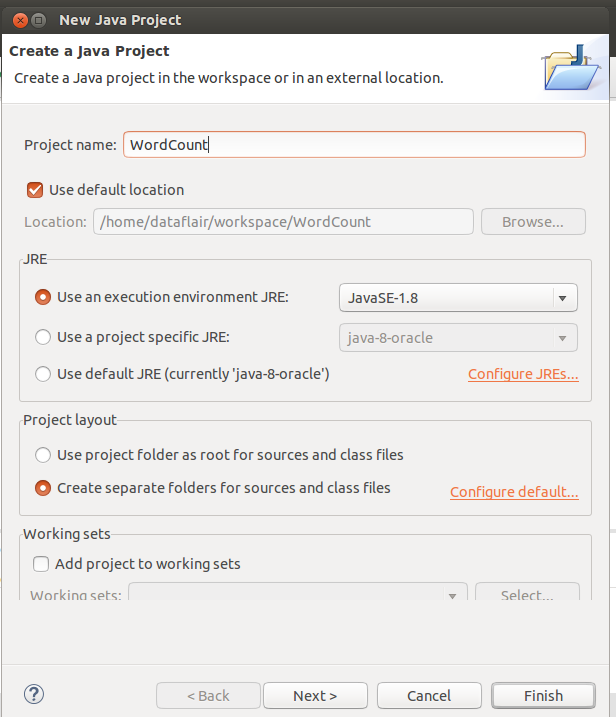
create an Apache Flink Application – make new project
c. Add the following JAR in the build path. You can find the jar files in the lib directory in Flink home:
- flink-dist_2.11-1.0.3.jar
- flink-python_2.11-1.0.3.jar
- log4j-1.2.17.jar
- slf4j-log4j12-1.7.7.jar
d. Right Click on the project and select Configure build path option from build path
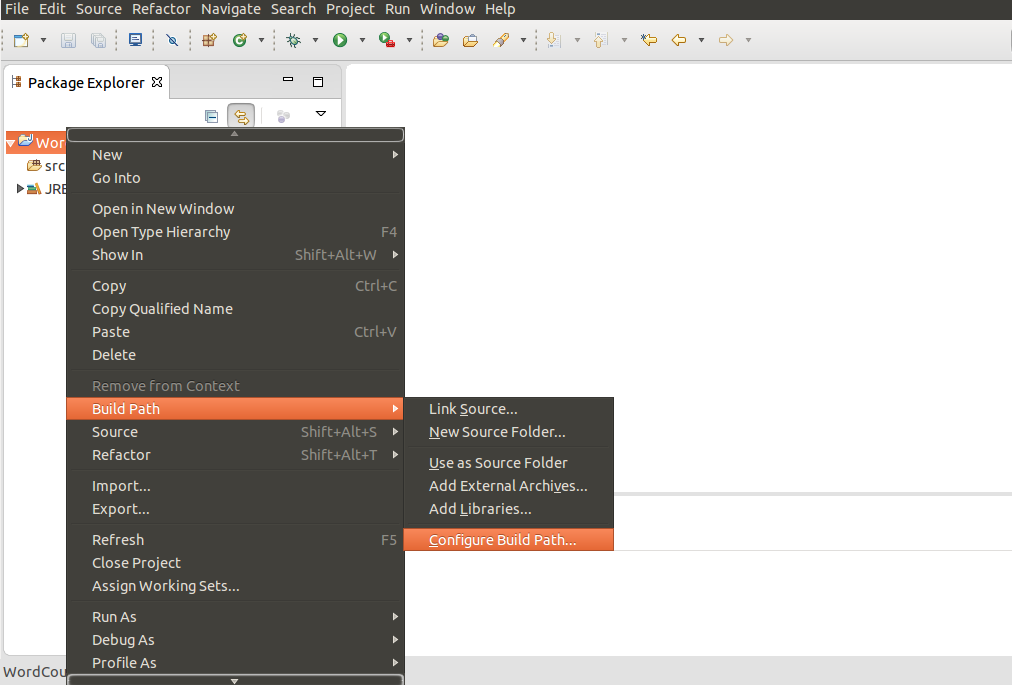
Apache Flink Project – configure buid path
e. Add the jar Files from lib folder present in Apache flink home
Create Flink Application in Java – add jar
iii. Make a class WordCount
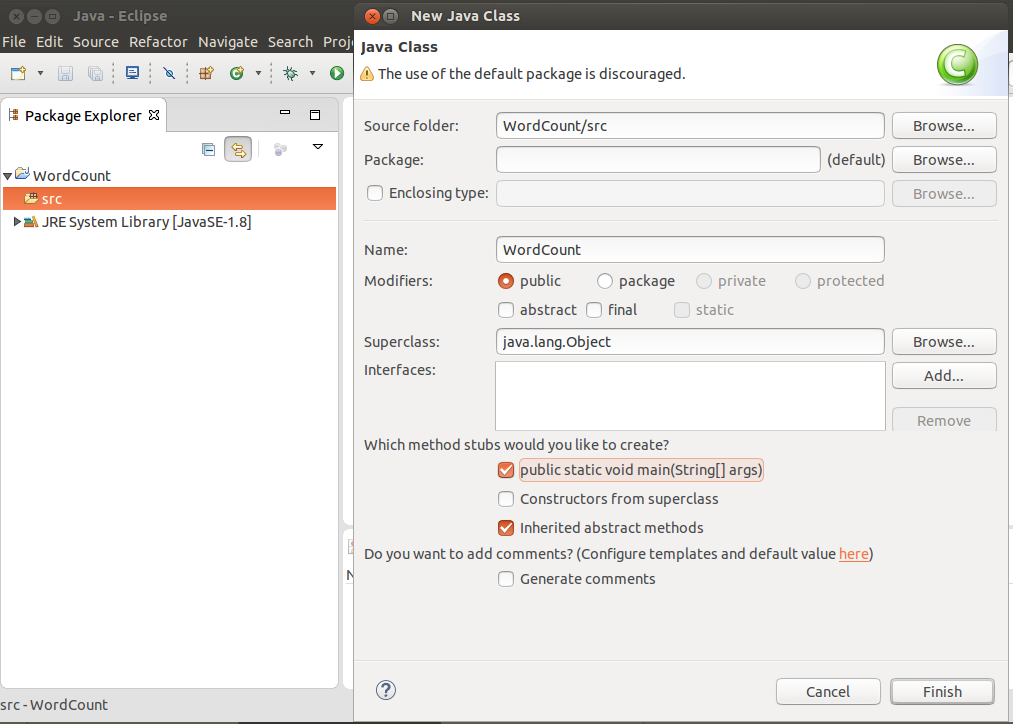
Apache Flink Application – make new class
iv. Copy below Apache Flink Wordcount Code in Editor
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.aggregation.Aggregations;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.util.Collector;
public class WordCount {
public static void main(String[] args) throws Exception {
// set up the execution environment
final ParameterTool params = ParameterTool.fromArgs(args);
final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
env.getConfig().setGlobalJobParameters(params);
// get input data
DataSet<String> text = env.readTextFile(params.get("input"));
DataSet<Tuple2<String, Integer>> counts =
// split up the lines in pairs (2-tuples) containing: (word,1)
text.flatMap(new Splitter())
// group by the tuple field "0" and sum up tuple field "1"
.groupBy(0)
.aggregate(Aggregations.SUM, 1);
// emit result
counts.writeAsText(params.get("output"));
// execute program
env.execute("WordCount Example");
}
}
//The operations are defined by specialized classes, here the Splitter class.
class Splitter implements FlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) {
// normalize and split the line into words
String[] tokens = value.split("\\W+");
// emit the pairs
for (String token : tokens) {
if (token.length() > 0) {
out.collect(new Tuple2<String, Integer>(token, 1));
}
}
}
}
v. Export the Apache Flink Jar File
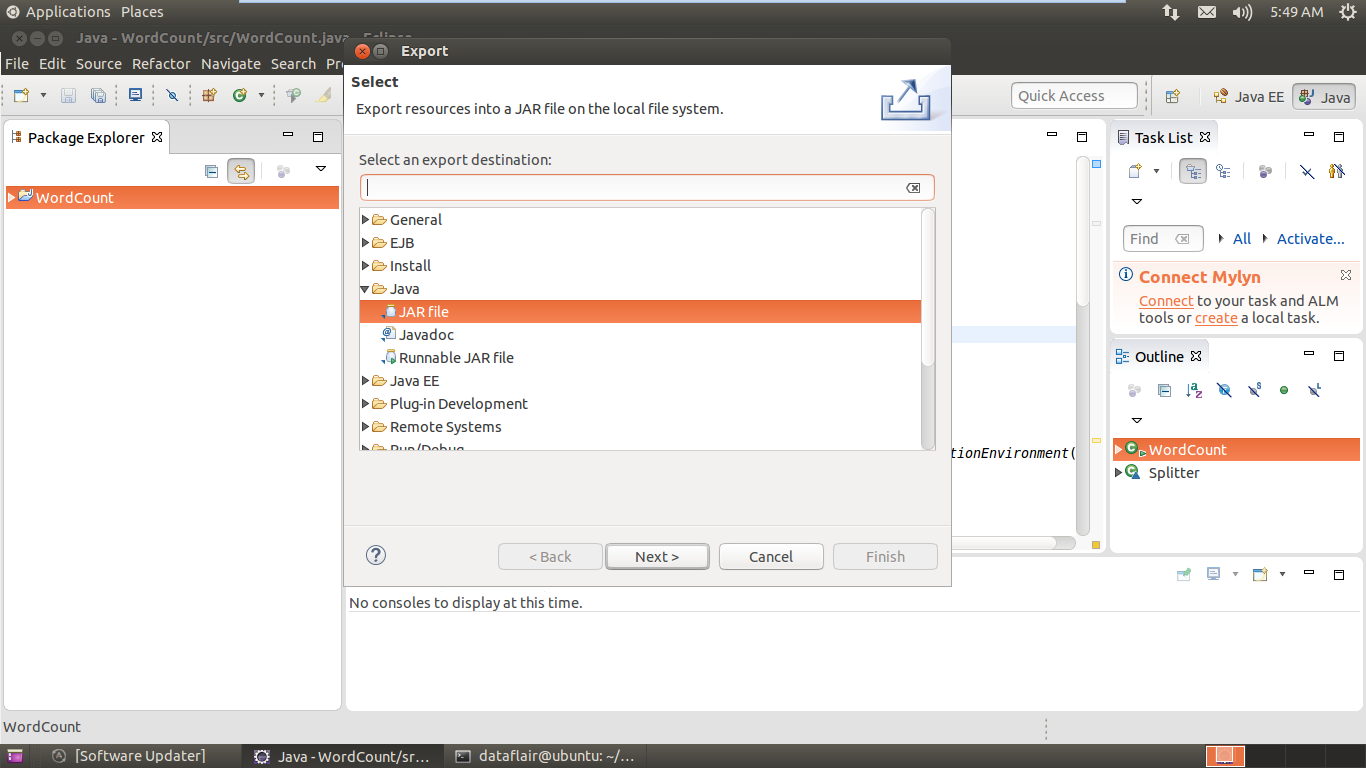
Before running created Apache Flink word count application we have to create a jar file. Right click on project >> export
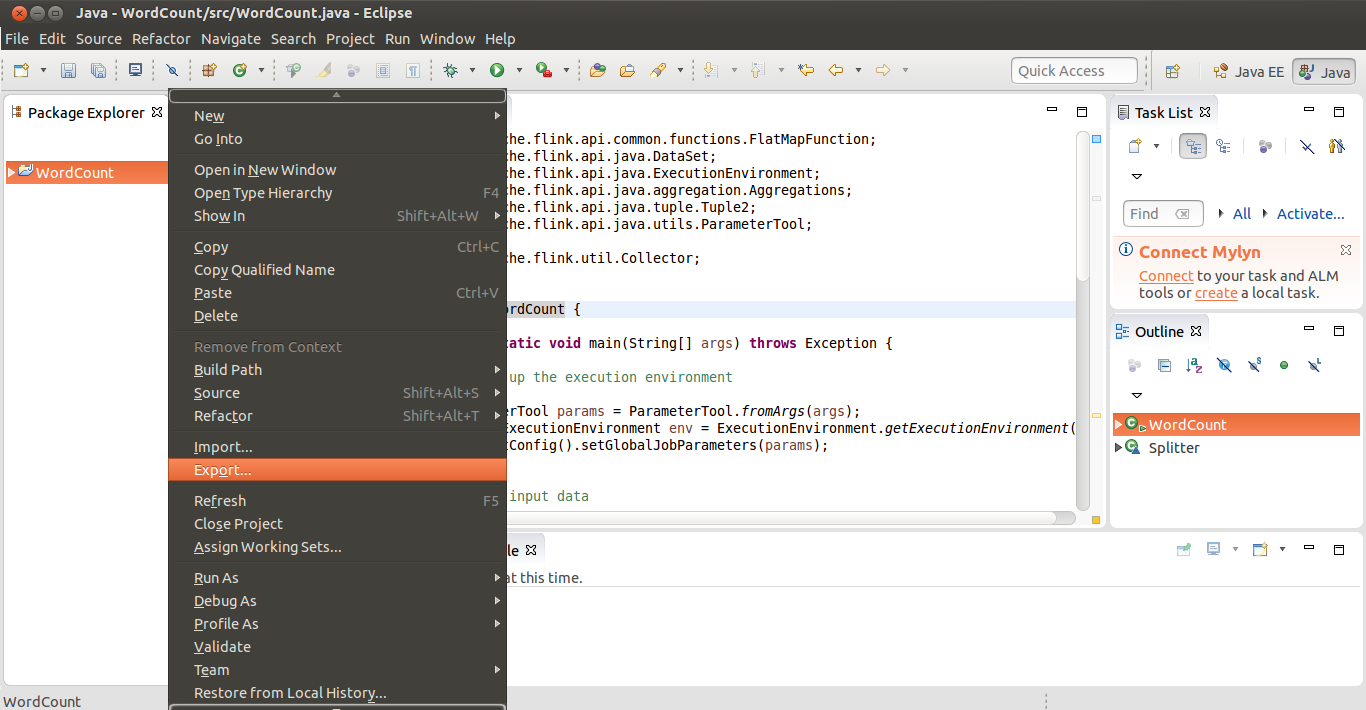
Apache Flink Application – export jar
Select Jar-file Option to Export
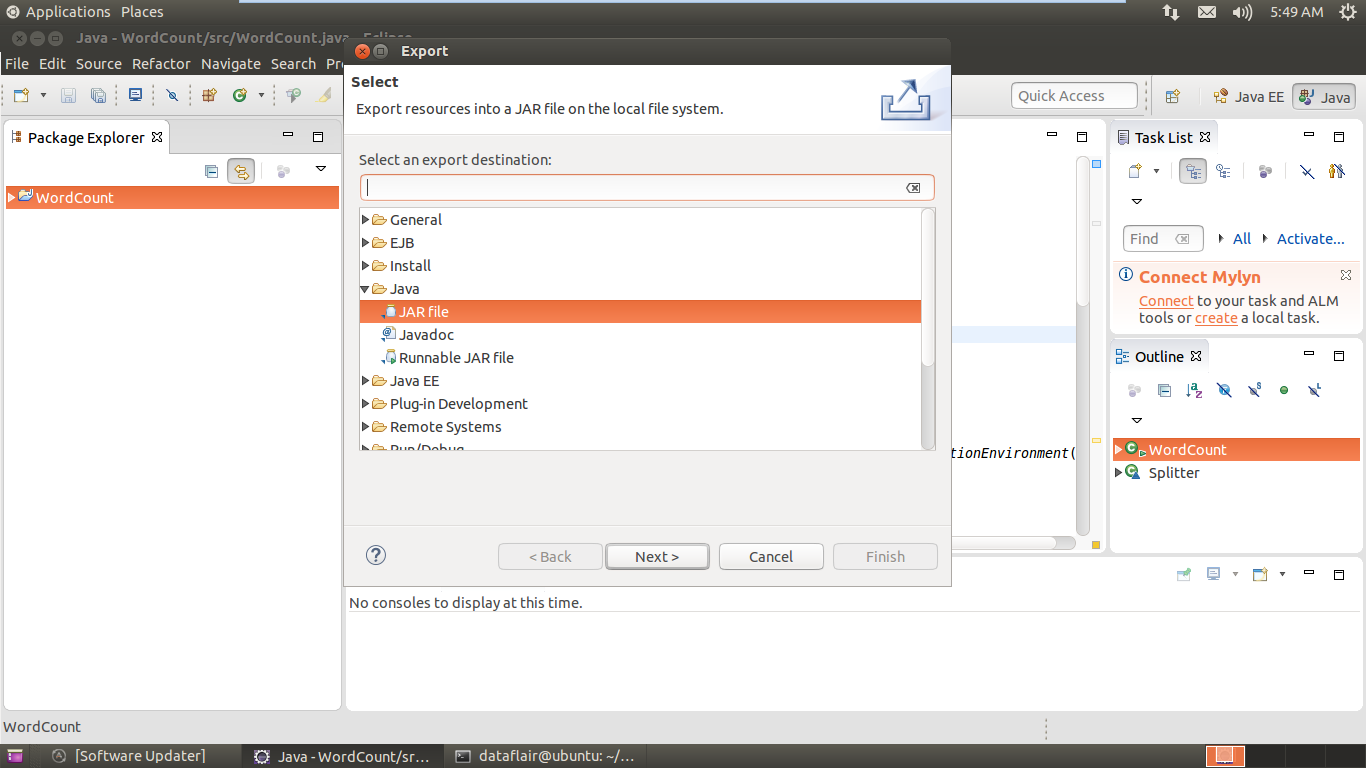
Create a project in Flink – choose jar option
Create the Jar file
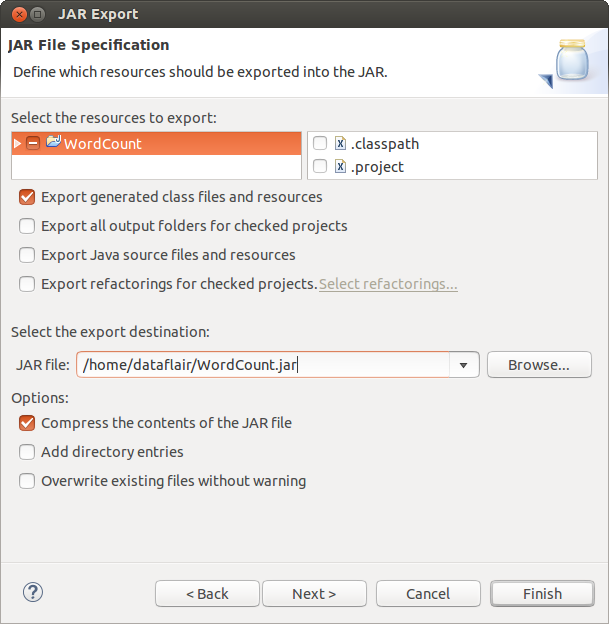
Apache Flink Application – export jar v2
vi. Go to Apache Flink Home Directory
i. start the Apache Flink services by using following commands
cd Flink bin/start-local.sh
Apache Flink Application – flink home
vii. Sample Data
Save the following data as input.txt, according to our command it is saved in a home folder.
DataFlair services pvt ltd provides training in Big Data Hadoop, Apache Spark, Apache Flink, Apache Kafka, Hbase, Apache Hadoop Admin 10000 students are taking training from DataFlair services pvt ltd The chances of getting good job in big data hadoop is high If you want to become an expert hadoop developer then enroll now!! hurry up!!
viii. Submit Apache Flink Application
Use the following command to Submit the Apache Flink Application
bin/flink run --class <class-name> <Jar path> --input <Input File Path> --output <Output Flie Path> bin/flink run --class WordCount /home/dataflair/WordCount.jar --input file:///home/dataflair/input.txt --output file:///home/dataflair/Desktop/output.txt<br/>
Apache Flink run command
We have successfully exported the Apache Flink program. To learn more about the installation of Apache Flink you can refer this Apache Flink installation guide.
Let’s understand above command:
–class is used to specify the main class which is an entry point of your program
/home/dataflair/WordCount.jar – It is the jar file in which your program exist
–input is used to specify the input path of your file
–output is used to specify the output path of your file
When you will run the above command you will get the following result on your terminal-
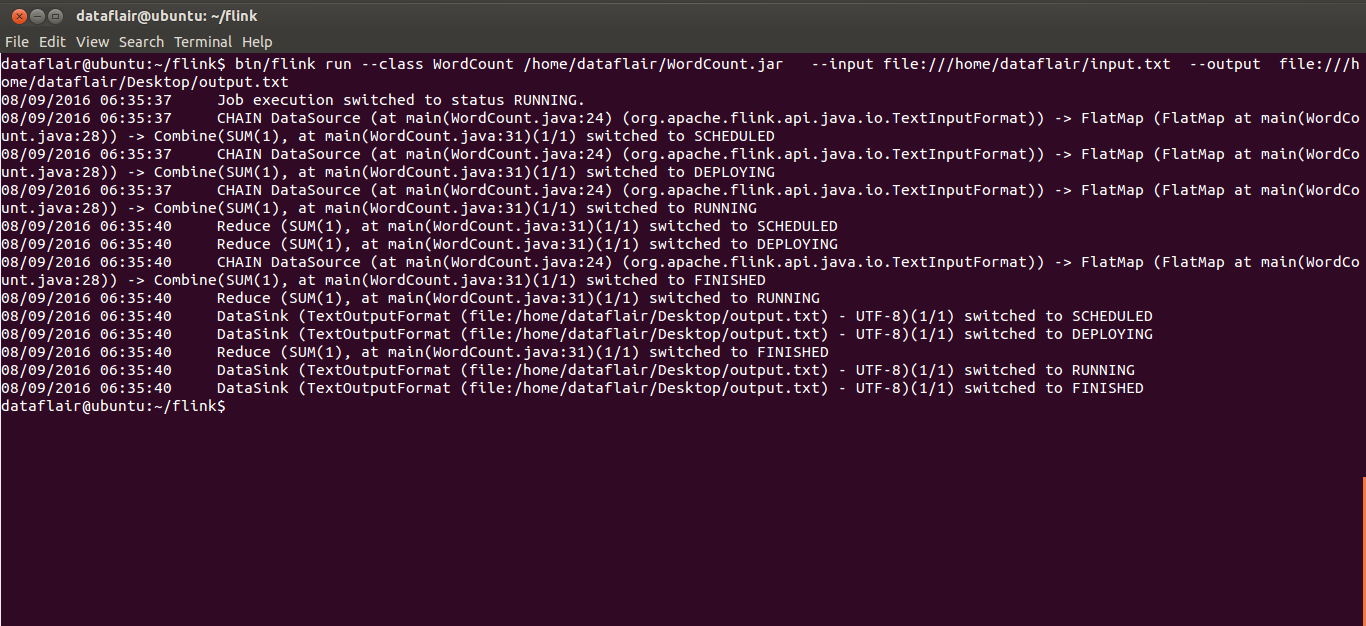
Apache Flink run command output
ix. Output

Apache Flink Application – output
Here is the output of our Apache Flink Word Count program.
We can also create Apache Flink project in Scala as well. To Learn Scala follow this Scala tutorial.
So, we have created an Apache Flink Application in Java in Eclipse. Hope you like our explanation. Still, if any doubt, ask freely in the comment tab.
Conclusion
Developers may take use of Apache Flink’s distributed stream and batch processing capabilities for effective big data analysis and application development by building an Apache Flink application in Java.
Developers can take advantage of Flink’s powerful features to process data from various sources, apply sophisticated transformations, and output results to various sinks by setting up the Flink environment, adding necessary dependencies, writing the application code using Flink’s Java API, and deploying it on a Flink cluster.
Java developers may create highly dependable and performant data processing applications that address a variety of big data concerns across industries thanks to Flink’s fault tolerance, scalability, and performance optimisations.