Learn SparkContext – Introduction and Functions
1. Objective
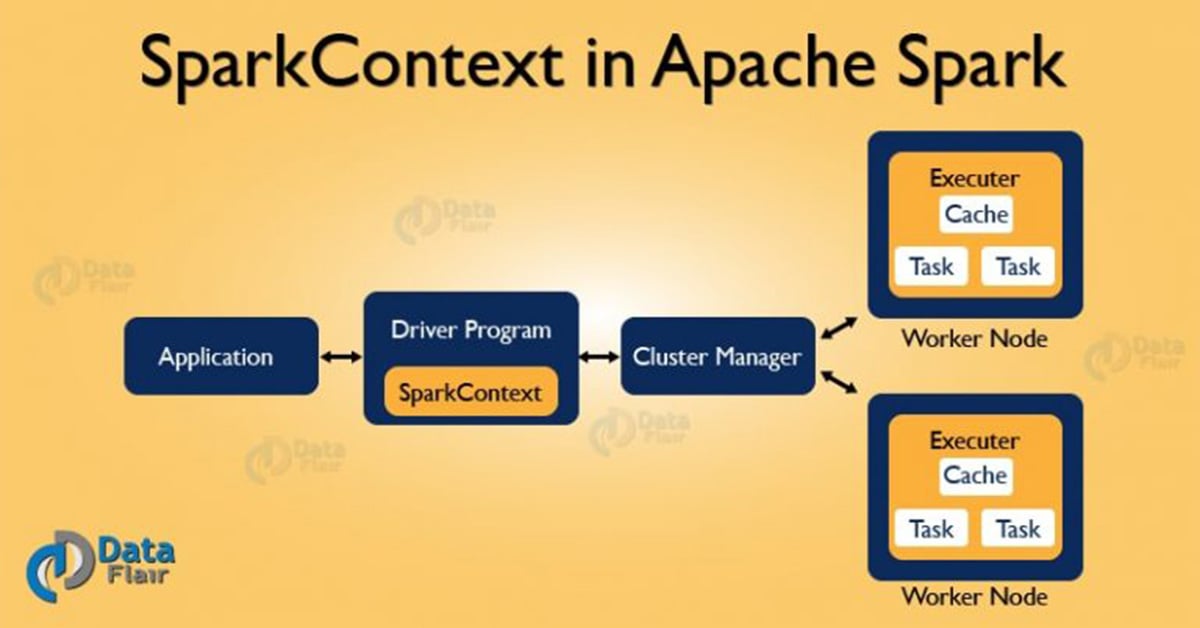
SparkContext is the entry gate of Apache Spark functionality. The most important step of any Spark driver application is to generate SparkContext. It allows your Spark Application to access Spark Cluster with the help of Resource Manager (YARN/Mesos). To create SparkContext, first SparkConf should be made. The SparkConf has a configuration parameter that our Spark driver application will pass to SparkContext.
In this Apache Spark tutorial, we will deeply understand what is SparkContext in Spark. How to create SparkContext Class in Spark with the help of Spark-Scala word count program. We will also learn various tasks of SparkContext and how to stop SparkContext in Apache Spark.
So, let’s start SparkContext tutorial.
Learn SparkContext – Introduction and Functions
Learn how to install Apache Spark in standalone mode and Apache Spark installation in a multi-node cluster.
2. What is SparkContext in Apache Spark?
SparkContext is the entry point of Spark functionality. The most important step of any Spark driver application is to generate SparkContext. It allows your Spark Application to access Spark Cluster with the help of Resource Manager. The resource manager can be one of these three- Spark Standalone, YARN, Apache Mesos.
3. How to Create SparkContext Class?
If you want to create SparkContext, first SparkConf should be made. The SparkConf has a configuration parameter that our Spark driver application will pass to SparkContext. Some of these parameter defines properties of Spark driver application. While some are used by Spark to allocate resources on the cluster, like the number, memory size, and cores used by executor running on the worker nodes.
In short, it guides how to access the Spark cluster. After the creation of a SparkContext object, we can invoke functions such as textFile, sequenceFile, parallelize etc. The different contexts in which it can run are local, yarn-client, Mesos URL and Spark URL.
Once the SparkContext is created, it can be used to create RDDs, broadcast variable, and accumulator, ingress Spark service and run jobs. All these things can be carried out until SparkContext is stopped.
4. Stopping SparkContext
Only one SparkContext may be active per JVM. You must stop the active it before creating a new one as below:
stop(): Unit
It will display the following message:
INFO SparkContext: Successfully stopped SparkContext
5. Spark Scala Word Count Example
Let’s see how to create SparkContext using SparkConf with the help of Spark-Scala word count example-
[php]
package com.dataflair.spark
import org.apache.spark.SparkContext
import org.apache.spark.SparkConf
object Wordcount {
def main(args: Array[String]) {
//Create conf object
val conf = new SparkConf()
.setAppName(“WordCount”)
//create spark context object
val sc = new SparkContext(conf)
//Check whether sufficient params are supplied
if (args.length < 2) {
println(“Usage: ScalaWordCount <input> <output>”)
System.exit(1)
}
//Read file and create RDD
val rawData = sc.textFile(args(0))
//convert the lines into words using flatMap operation
val words = rawData.flatMap(line => line.split(” “))
//count the individual words using map and reduceByKey operation
val wordCount = words.map(word => (word, 1)).reduceByKey(_ + _)
//Save the result
wordCount.saveAsTextFile(args(1))
//stop the spark context
sc.stop
}
}[/php]
6. Functions of SparkContext in Apache Spark

10 Important Functions of SparkContext in Apache Spark
i. To get the current status of Spark Application
- SpkEnv – It is a runtime environment with Spark’s public services. It interacts with each other to establish a distributed computing platform for Spark Application. A SparkEnv object that holds the required runtime services for running Spark application with the different environment for the driver and executor represents the Spark runtime environment.
- SparkConf – The Spark Properties handles maximum applications settings and are configured separately for each application. We can also easily set these properties on a SparkConf. Some common properties like master URL and application name, as well as an arbitrary key-value pair, configured through the set() method.
- Deployment environment (as master URL) – Spark deployment environment are of two types namely local and clustered. Local mode is non-distributed single-JVM deployment mode. All the execution components – driver, executor, LocalSchedulerBackend, and master are present in same single JVM. Hence, the only mode where drivers are useful for execution is the local mode. For testing, debugging or demonstration purpose, the local mode is suitable because it requires no earlier setup to launch spark application. While in clustered mode, the Spark runs in distributive mode. Learn Spark Cluster Manager in detail.
ii. To set the configuration
- Master URL – The master method returns back the current value of spark.master which is deployment environment in use.
- Local properties-Creating Logical Job Groups – The reason of local properties concept is to form logical groups of jobs by means of properties that create the separate job launched from different threads belong to a single logic group. We can set a local property which will affect Spark jobs submitted from a thread, such as the Spark fair scheduler pool.
- Default Logging level – It lets you set the root login level in a Spark application, for example, Spark Shell.
iii. To Access various services
It also helps in accessing services like TaskScheduler, LiveListenBus, BlockManager, SchedulerBackend, ShuffelManager and the optional ContextCleaner.
iv. To Cancel a job
cancleJob simply requests DAGScheduler to drop a Spark job.
Learn about Spark DAG(Directed Acyclic Graph) in detail.
v. To Cancel a stage
cancleStage simply requests DAGScheduler to drop a Spark stage.
vi. For Closure cleaning in Spark
Spark cleanups the closure every time an Action occurs, i.e. the body of Action before it is serialized and sent over the wire to execute. The clean method in SparkContext does this. This, in turn, calls ClosureClean.clean method. It not only cleans the closure but also referenced closure is clean transitively. It assumes serializable until it does not explicitly reference unserializable objects.
vii. To Register Spark listener
We can register a custom SparkListenerInterface with the help of addSparkListener method. We can also register custom listeners using the spark.extraListeners setting.
viii. Programmable Dynamic allocation
It also provides the following method as the developer API for dynamic allocation of executors: requestExecutors, killExecutors, requestTotalExecutors, getExecutorIds.
ix. To access persistent RDD
getPersistentRDDs gives the collection of RDDs that have marked themselves as persistent via cache.
x. To unpersist RDDs
From the master’s Block Manager and the internal persistentRdds mapping, the unpersist removes the RDD.
So, this was all in Sparkcontext Tutorial. Hope you like our explanation.
7. Conclusion
Hence, SparkContext provides the various functions in Spark like get the current status of Spark Application, set the configuration, cancel a job, Cancel a stage and much more. It is an entry point to the Spark functionality. Thus, it acts a backbone.
If you have any query about this tutorial, So feel free to Share with us. We will be glad to solve them.
See Also-
Did we exceed your expectations?
If Yes, share your valuable feedback on Google


Awesome work Guys, very informative site I must say.
I have a query here regarding the wordcount program, once I write this program, how do i pass the arguments to the program,
can you please give example here ?
I did try to “:paste” this program on my single node machine. got the message : defined object Wordcount
now how do I pass the parameters here ?