Python Django Project – Learn to Build your own News Aggregator Web App
Python course with 57 real-time projects - Learn Python
FREE Online Courses: Elevate Skills, Zero Cost. Enroll Now!
After gaining knowledge from the Django tutorials, it’s time to implement and showcase that. In this Python django project, you will learn to build your own news aggregator web application by integrating Django with other technologies.
Although, some prerequisite is important.
Prerequisite
You need to have some basic knowledge of these libraries:
- Django Framework
- BeautifulSoup
- requests module
What is a News Aggregator?
It is a web application which aggregates data (news articles) from multiple websites. Then presents the data in one location.
News aggregator service is a very important start of the day.
There are various publications and news sites online. They publish their content on multiple platforms. Now, imagine when you open 10-20 news sites every day. The time you waste to gain information. Information gain is everything in today’s world.
It can give you leverage over those who don’t have it. Now, is there a way we can make it easier? Yes!!
A news aggregator makes this task easier. In a news aggregator, you can select the websites you want to follow. Then the news aggregator collects the articles for you. And, you are just a click away to get information from various websites.
This task otherwise takes too much time on our schedule.
About the Django Project
A news aggregator is a combination of web crawlers and web applications. Both of these technologies have their implementation in Python. That makes it easier for us.
So, our news aggregator will work in 3 steps:
- It scrapes the web for the articles. (In this Django project, we are scraping a website called theonion)
- Then it stores the article’s images, links, and title.
- The stored objects in the database are served to the client. The client gets information in a nice template.
So, that’s how our web app will work.
You can find the complete source code of this Django project in this Github repository:
This is a screenshot of the page.
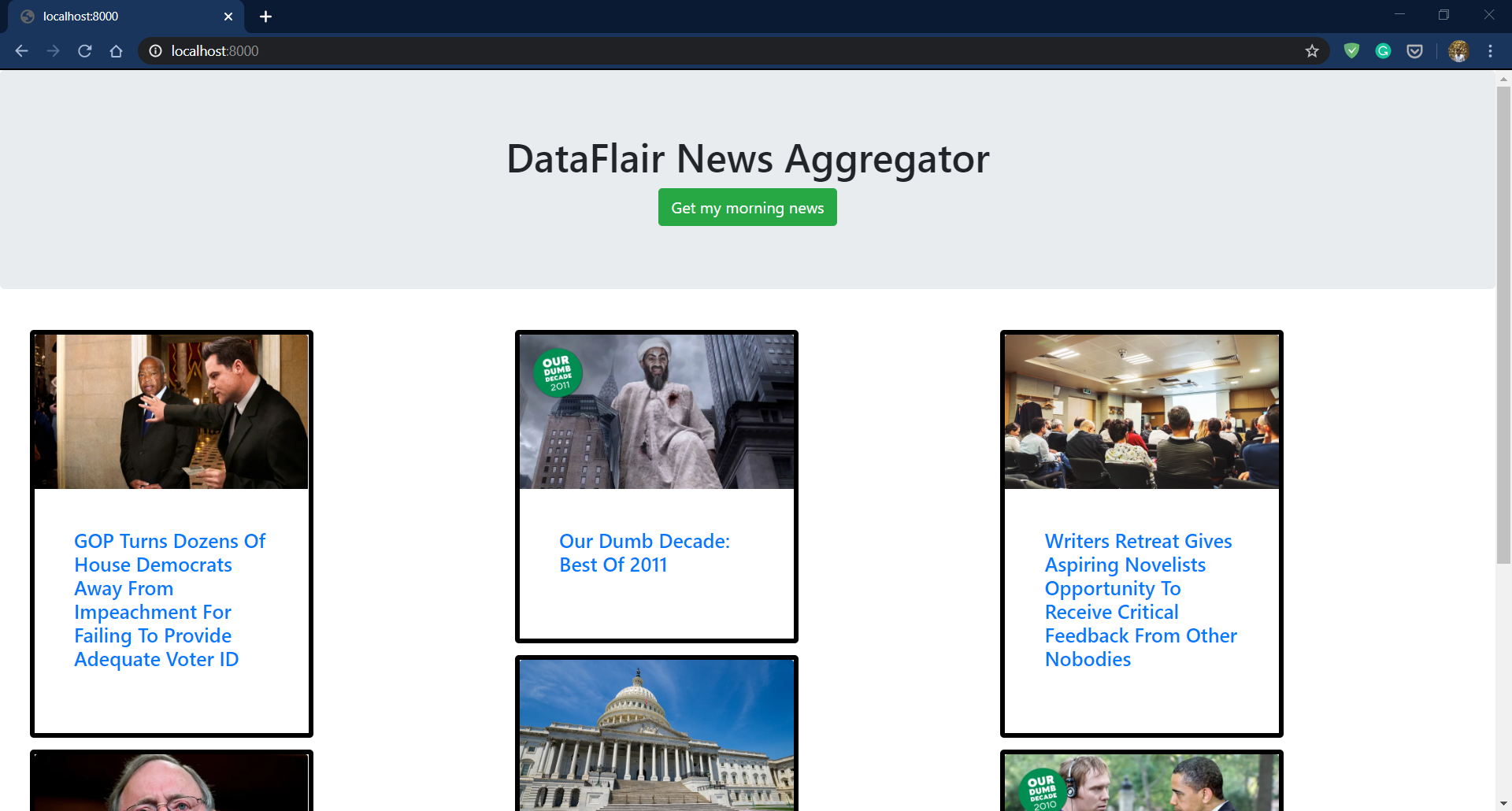
This might not look very interesting. There are lots of things we will need to do before getting this page.
Also, check out the page of theonion website before proceeding.

So, let’s get started.
Steps to Build Django Project on News Aggregator App
Before starting, we will need to install some of the libraries. We will install the requests and BeautifulSoup libraries. You can install them using pip.
pip install bs4 pip install requests

Now, we will make a new Python Django project named DataFlair_NewsAggregator. Then we will make new application news.
Commands:
django-admin startproject DataFlair_NewsAggregator
Move into the folder where manage.py is present.
python manage.py startapp news
Writing Models
We will be storing the urls and articles in our database. For that, we will need the model.
In news/models.py, create these models.
Code:
from django.db import models
class Headline(models.Model):
title = models.CharField(max_length=200)
image = models.URLField(null=True, blank=True)
url = models.TextField()
def __str__(self):
return self.title
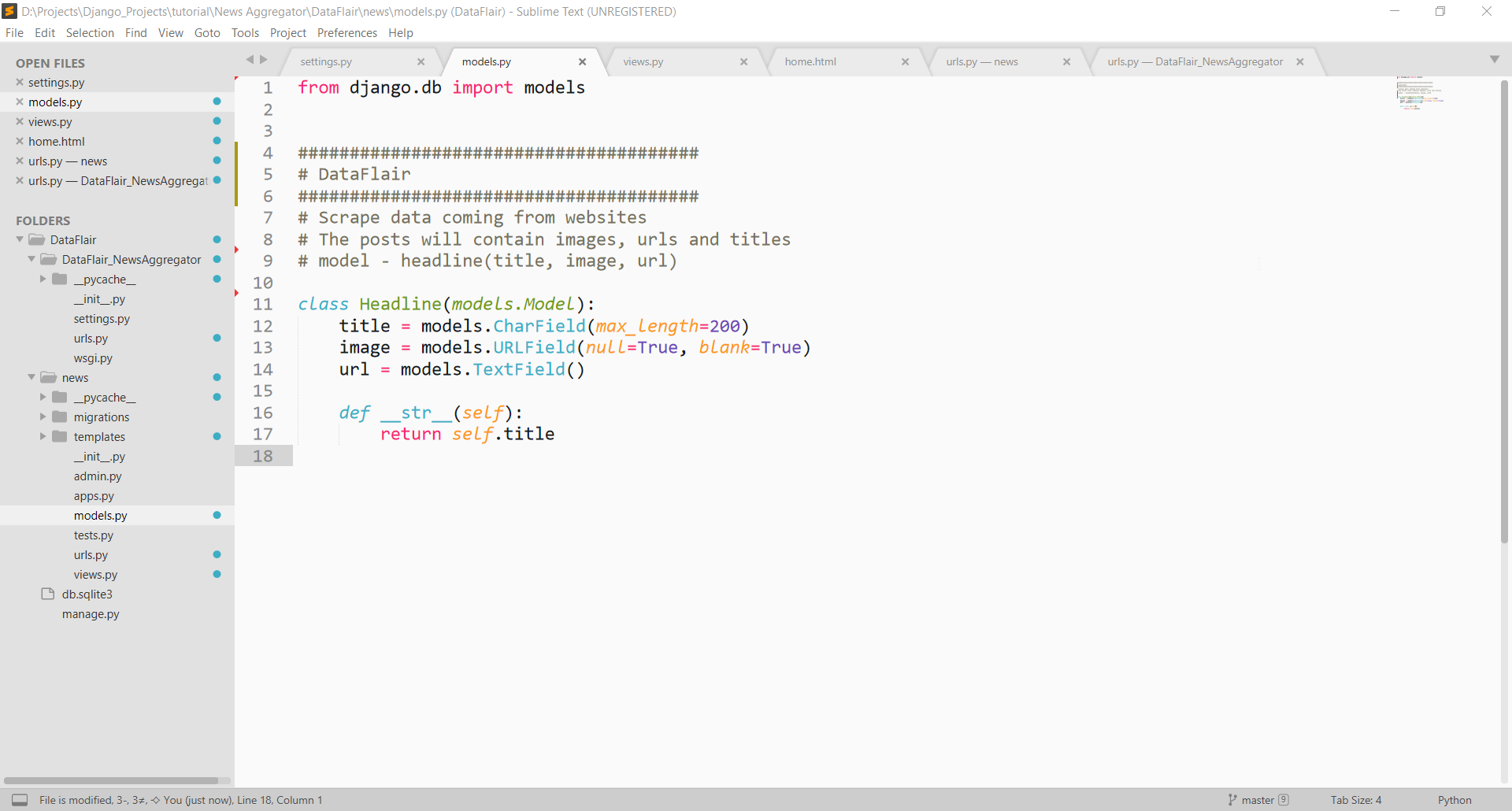
Our models will be able to store three things:
- Title of the article
- URL of the origin or source
- URL of the article image
We are using simple model fields for that purpose. Also, the image field can be blank. The __str__() method will return the string representation of the object. These are simple Django concepts.
Now, let’s start with the steps for web crawlers.
Step 1 – Scrape the website
We will be scraping the website for getting articles. Web-Scraping means extracting data from the websites. We extract meaningful data from the websites. In this case, we will be extracting the articles from the theonion website.
To scrape the website, we will use beautifulsoup and requests module. These libraries are the bs4 and requests and modules are used for web crawling.
Open news/views.py file.
First, import these libraries before using them.
Code:
import requests from django.shortcuts import render, redirect from bs4 import BeautifulSoup as BSoup from news.models import Headline
We will be making the first view function as scrape().
Code:
def scrape(request):
session = requests.Session()
session.headers = {"User-Agent": "Googlebot/2.1 (+http://www.google.com/bot.html)"}
url = "https://www.theonion.com/"
content = session.get(url, verify=False).content
soup = BSoup(content, "html.parser")
News = soup.find_all('div', {"class":"curation-module__item"})
for artcile in News:
main = artcile.find_all('a')[0]
link = main['href']
image_src = str(main.find('img')['srcset']).split(" ")[-4]
title = main['title']
new_headline = Headline()
new_headline.title = title
new_headline.url = link
new_headline.image = image_src
new_headline.save()
return redirect("../")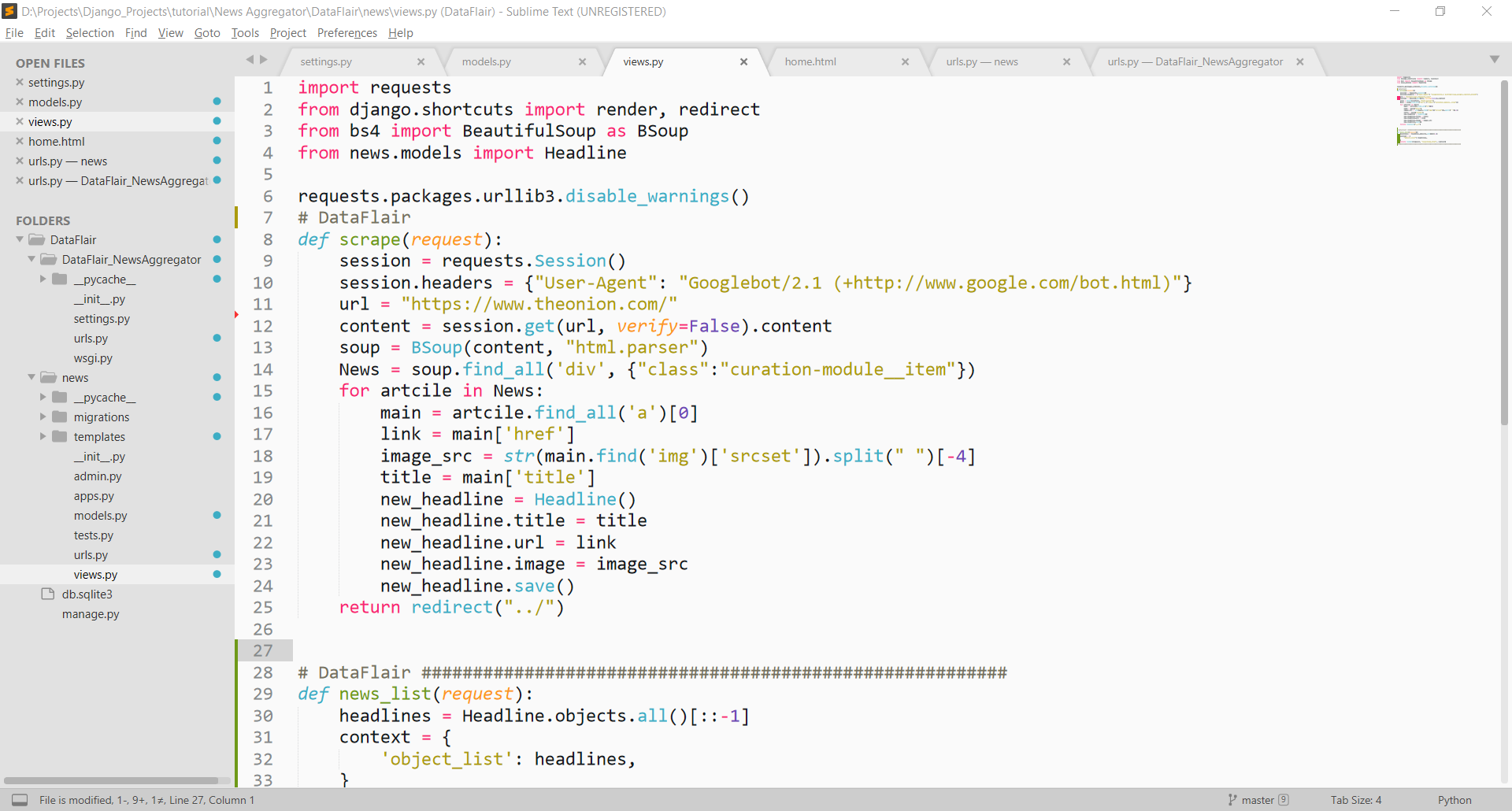
This view function uses modules like requests, bs4 and Django’s shortcuts.
We have imported the model Headline from news.models. Also, we have other libraries.
The first line of the function is a setting for requests framework. These settings are necessary. They will prevent the errors to stop the execution of the program. Then we write our view function scrape(). The scrape() method will scrape the news articles from the URL “theonion.com”.
The first variable is the session object of the requests module. These are essential to make a connection to the server. This is the abstraction provided by requests framework.
The session variables have headers as HTTP headers. These headers are used by our function to request the webpage. The scrapper acts like a normal http client to the news site. The User-Agent key is important here.
This HTTP header will tell the server information about the client. We are using Google bot for that purpose. When our client requests anything on the server, the server sees our request coming as a Google bot. You can configure it look like a browser User-Agent.
That won’t affect our use-case though. After that, we introduce the content variable. We store the webpage or response given by the server in content. Now, the beautifulsoup comes in.
The beautiful soup is a library that can extract data from HTML web pages. We create a soup object where we pass the HTML page. Alongside the HTML page, we also pass HTML parser as a parameter.
The HTML parser will parse the HTML as a BeautifulSoup object. In this object, we can access HTML elements and their texts.
In the News object, we return the <div> of a particular class. We selected this class from the webpage inspection. We inspected the webpage of the website theonion. Now, we select the elements which have the information we need.

As you can see from this image, by inspecting the element, we find a common class. The rest is just extracting information from that element.
Now we get 3 elements of this class. That means that the three articles are present in this class. These articles have a very general structure. Now, we will extract the information which we need. In this case, we have to extract the title, link, and image link.
Using a for loop, we can iterate over soup objects. In the for loop, the main variable will hold the link to the origin webpage. The main attribute gets the anchor tag. Since, the <div>s returned only have one <a>tag, we get most of our work done here.
The <a> tag contains title and href of the original link. We can access the href in <a> tag by writing main[‘href’].
Similarly, we can extract the title by main[‘title’]. Remember the main is the <a> tag beautifulsoup object.
Then we find the image URL. To get the image_src, we find the image in the main. This is all according to the webpage layout. We are not doing this because of syntax.
These are how the website has made its webpage. We are simply finding the elements and accessing them appropriately. You need to have some basics clear of beautiful soup and HTML.
So, once we get the image, we extract the srcset attribute from the same.
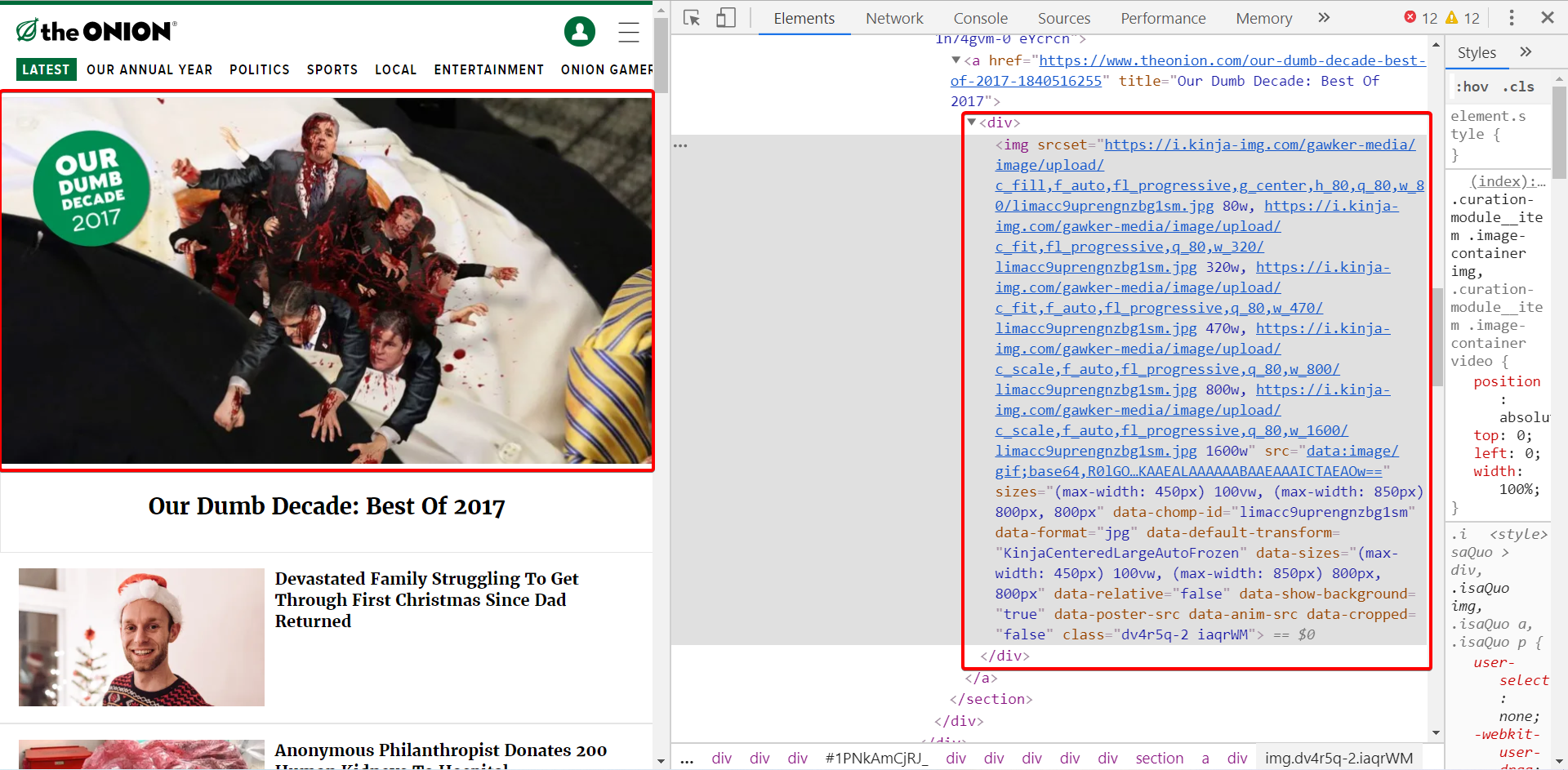
The srcset attribute contains various sizes of images, as we can see in the image. There we have to extract the size of the image which is big enough for us. We select the one with 800 width.
We get a string that has the source of the image and its width. And, we can travel over that list using Python indexing. As you can see in the code, we use the split() on the string to get a list. There we use index [-4]. That will give us the URL of 80 width image. That is stored as string in the image_src variable.
Step 2 – Store the data in the database
We have made our model Headline for this purpose. Now we will be performing the standard storing procedure. We create a new Headline() object. There we fill the corresponding fields.
Code:
new_headline = Headline() new_headline.title = title new_headline.url = link new_headline.image = image_src new_headline.save()
This the standard code for storing in the database.
Step 3 – Serve the stored database objects
This step is very easy too. We create a new view function for this purpose. That is news_list() method. The code lies in the file news/views.py file.
Code:
def news_list(request):
headlines = Headline.objects.all()[::-1]
context = {
'object_list': headlines,
}
return render(request, "news/home.html", context)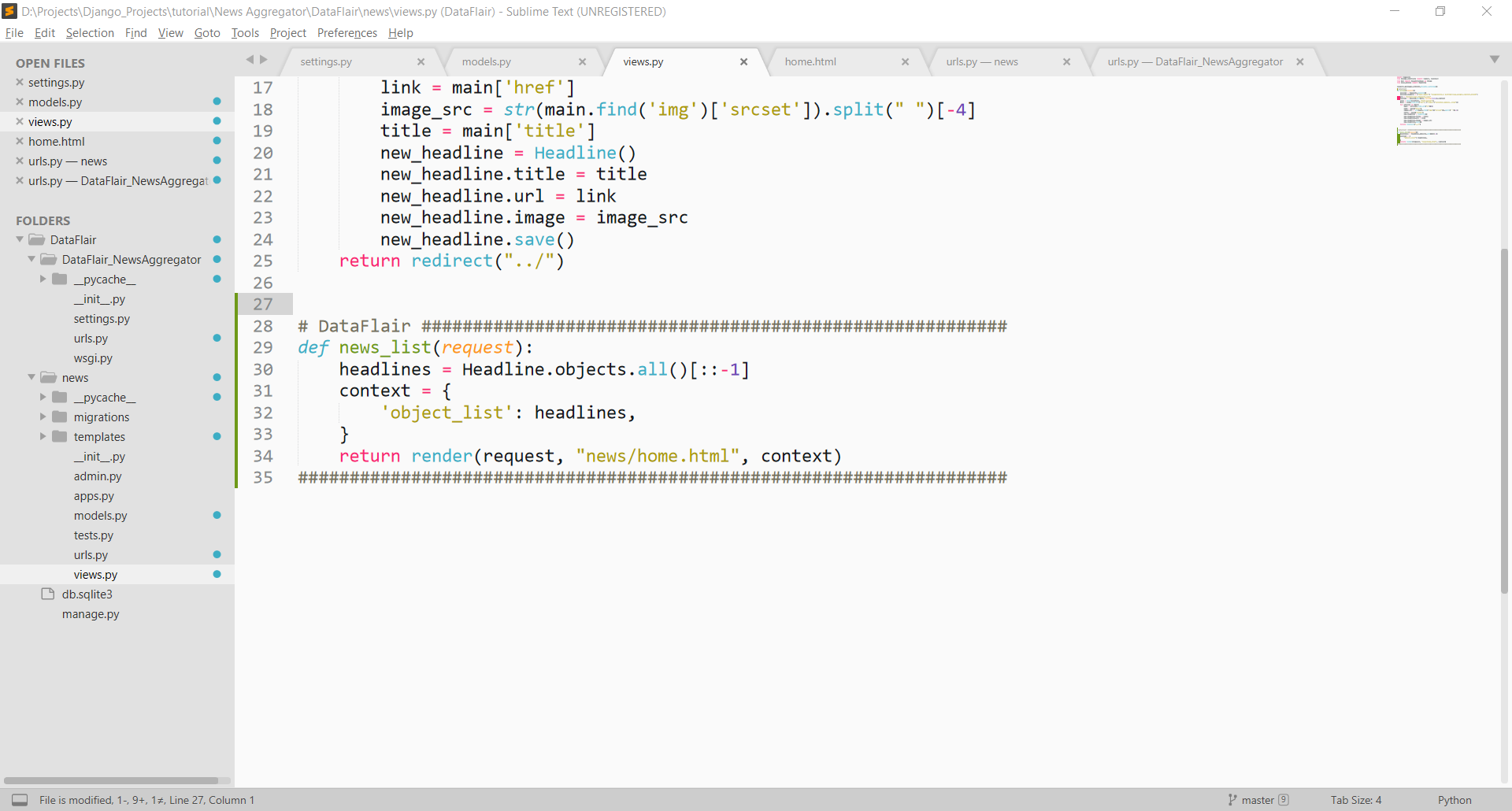
Here is a simple Django code. We simply extract all the elements from the database. Since we want the latest info on top, we reverse the list. Then we simply pass the list in a context. The context is then given to home.html in folder news/template/news.
Writing Templates
Here is the code for home.html. In this template, we are using bootstrap and HTML. The code in the home.html:
<!DOCTYPE html>
<html>
<head>
<title></title>
<link rel="stylesheet" href="https://maxcdn.bootstrapcdn.com/bootstrap/4.0.0/css/bootstrap.min.css" integrity="sha384-Gn5384xqQ1aoWXA+058RXPxPg6fy4IWvTNh0E263XmFcJlSAwiGgFAW/dAiS6JXm" crossorigin="anonymous">
</head>
<body>
<div class="jumbotron">
<center><h1>DataFlair News Aggregator</h1>
<a href="{% url 'scrape' %}" class="btn btn-success">Get my morning news</a>
</form>
</center>
</div>
<div class="card-columns" style="padding: 10px; margin: 20px;">
{% for object in object_list %}
<div class="card" style="width: 18rem;border:5px black solid;">
<img class="card-img-top" src = "{{ object.image }}">
<div class="card-body">
<h5 class="card-title"><div class="card-body">
<a href="{{object.url}}"><h5 class="card-title">{{object.title}}</h5></a>
</div></h5>
</div>
</div>
{% endfor %}
</div>
</div>
<script
src="http://code.jquery.com/jquery-3.3.1.min.js"
integrity="sha256-FgpCb/KJQlLNfOu91ta32o/NMZxltwRo8QtmkMRdAu8="
crossorigin="anonymous"></script>
<script src="https://cdnjs.cloudflare.com/ajax/libs/popper.js/1.12.9/umd/popper.min.js" integrity="sha384-ApNbgh9B+Y1QKtv3Rn7W3mgPxhU9K/ScQsAP7hUibX39j7fakFPskvXusvfa0b4Q" crossorigin="anonymous"></script>
<script src="https://maxcdn.bootstrapcdn.com/bootstrap/4.0.0/js/bootstrap.min.js" integrity="sha384-JZR6Spejh4U02d8jOt6vLEHfe/JQGiRRSQQxSfFWpi1MquVdAyjUar5+76PVCmYl" crossorigin="anonymous"></script>
</body>
</html>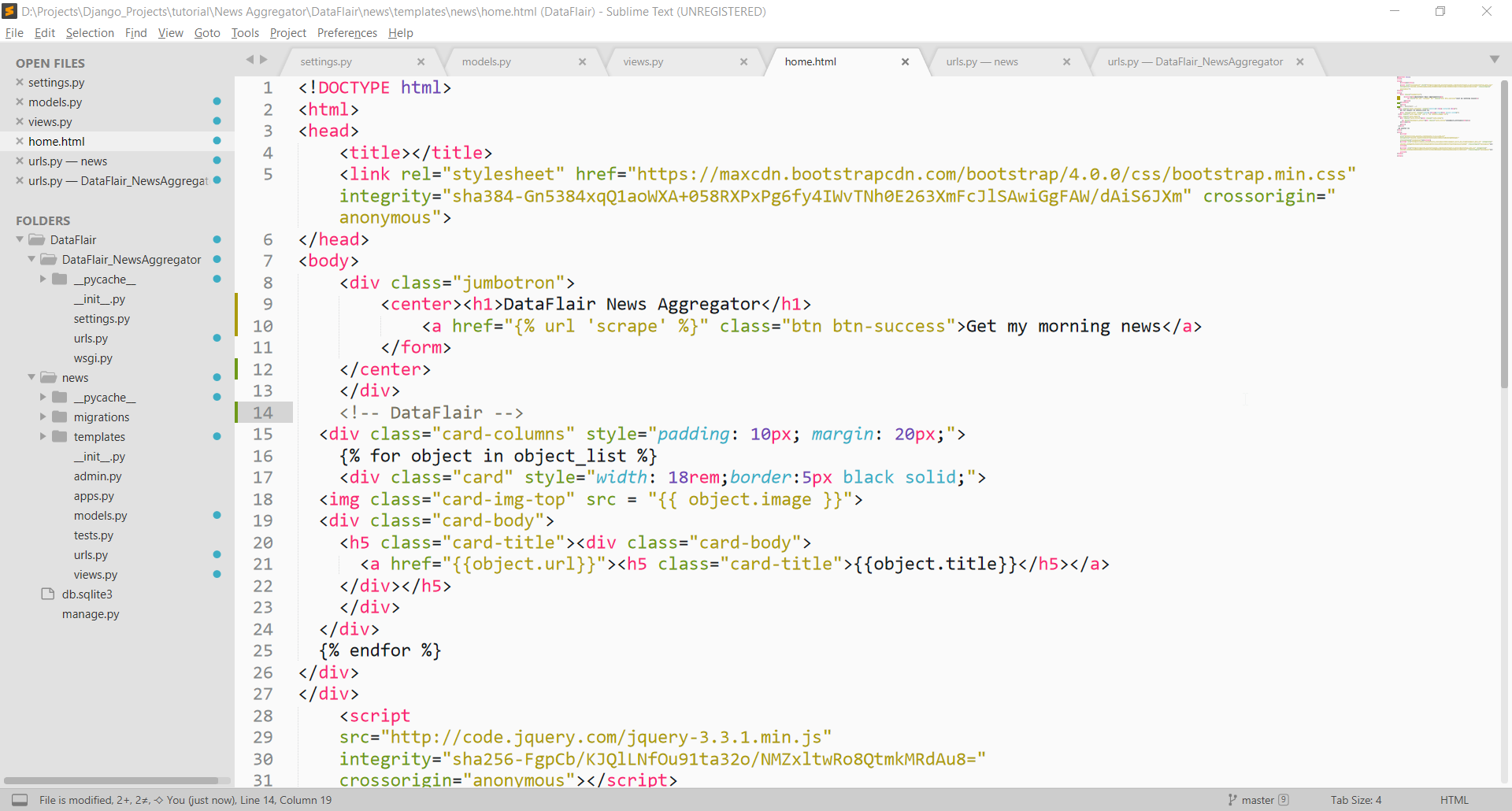
The basic knowledge of bootstrap and HTML can help here. It’s a simple Django template.
We have provided a link to the scrape view function. At line 10, the link to the scrape view function is provided. We will be defining our urls and then you will have a clearer picture.
Then at line 15, our news logic is written. Here we print the news objects one by one. The for loop is used for that purpose.
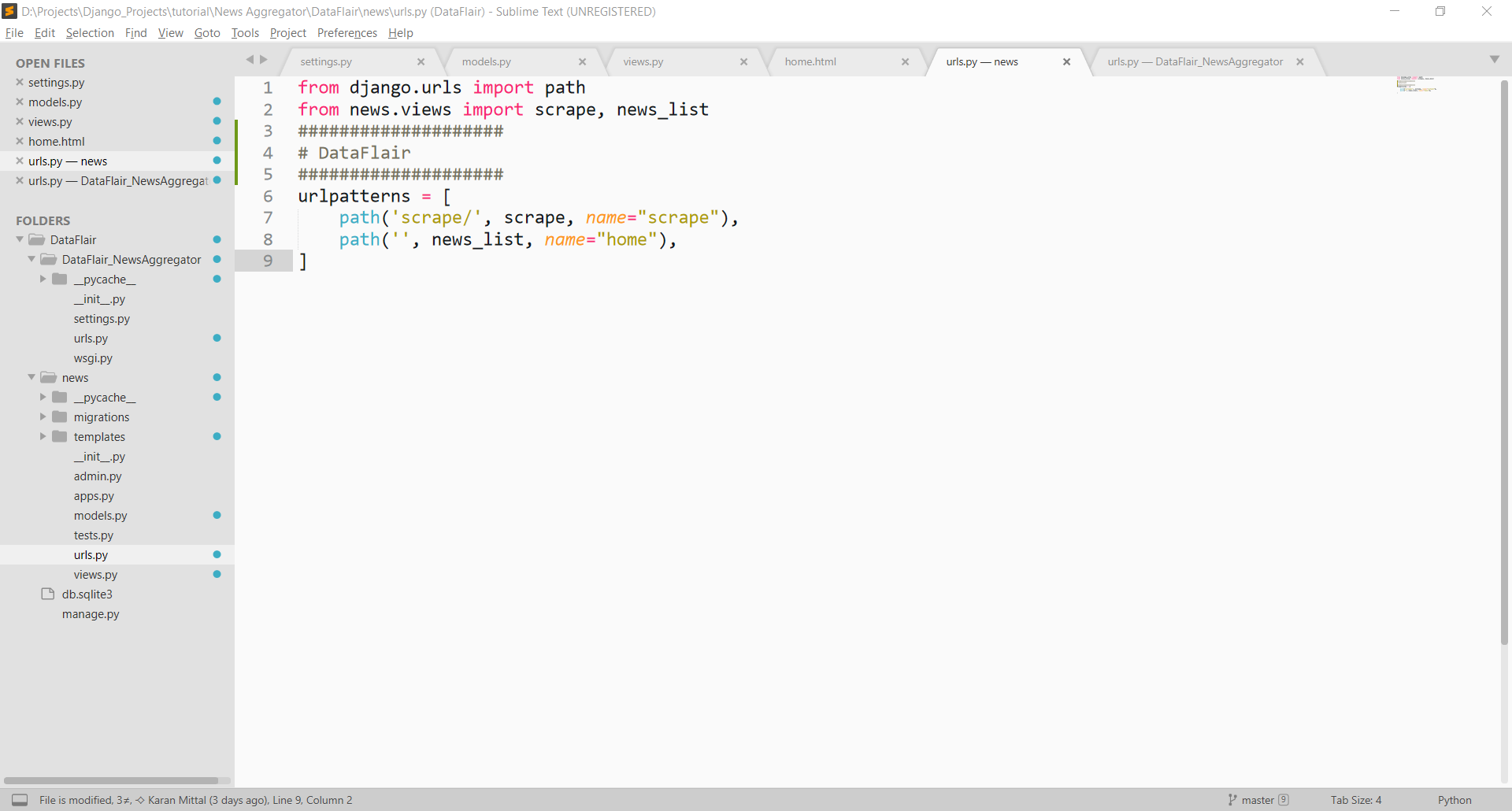
Configuring urls.py
Last, we configure our urls.py file. Make a file news/urls.py. Paste this code inside the urls.py.
Code:
from django.urls import path
from news.views import scrape, news_list
urlpatterns = [
path('scrape/', scrape, name="scrape"),
path('', news_list, name="home"),
]
Then we also need to connect this to main urls.py. Open DataFlair_NewsAggregator/urls.py file and paste this code inside that or update it.
Code:
from django.contrib import admin
from django.urls import path, include
urlpatterns = [
path('admin/', admin.site.urls),
path('', include("news.urls")),
]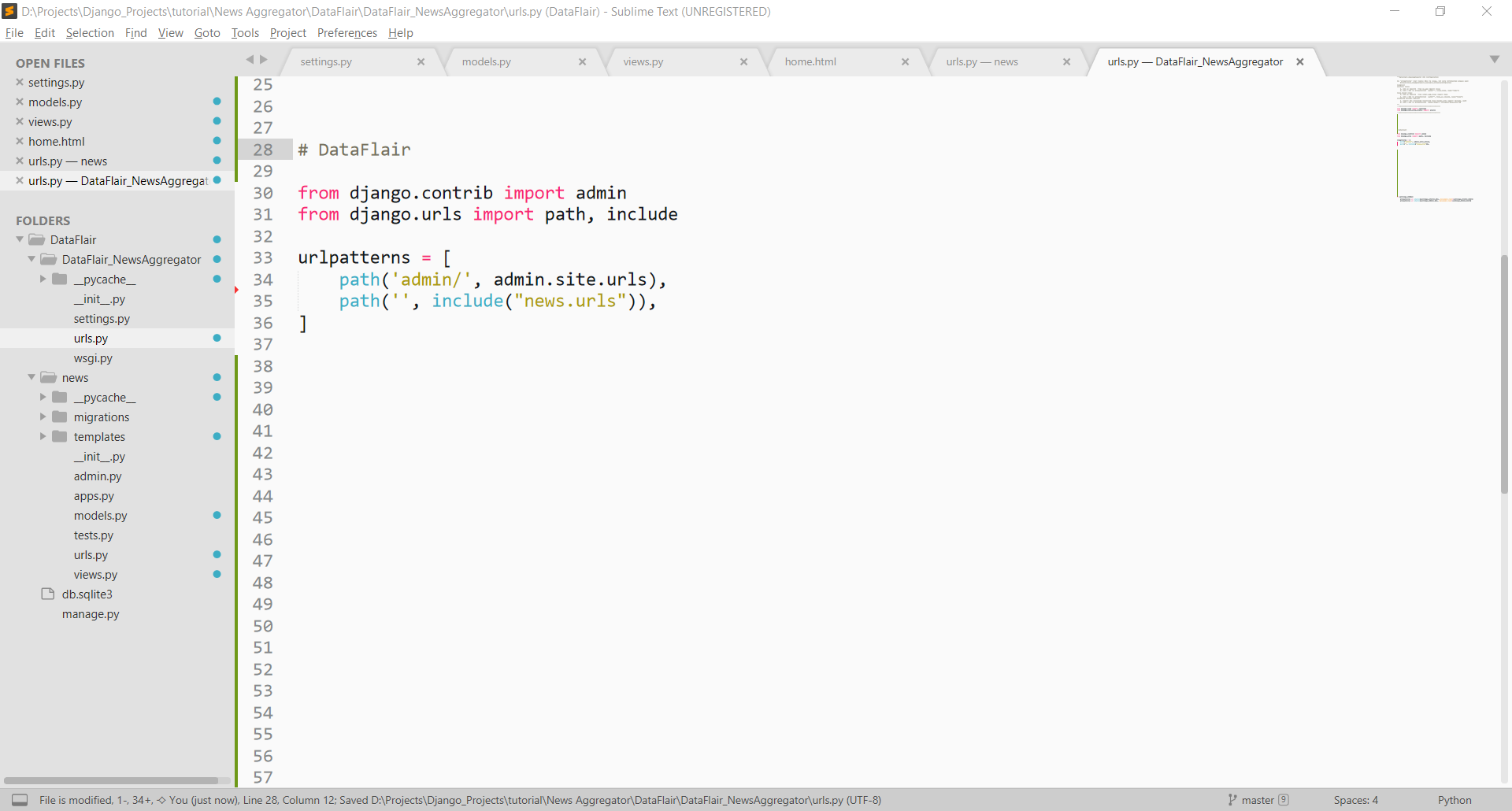
This is the normal Django code to connect urls.
So, our Python example project is complete. Let’s run it and see the homepage. In this case, when we open server and run news_list view.
Output:
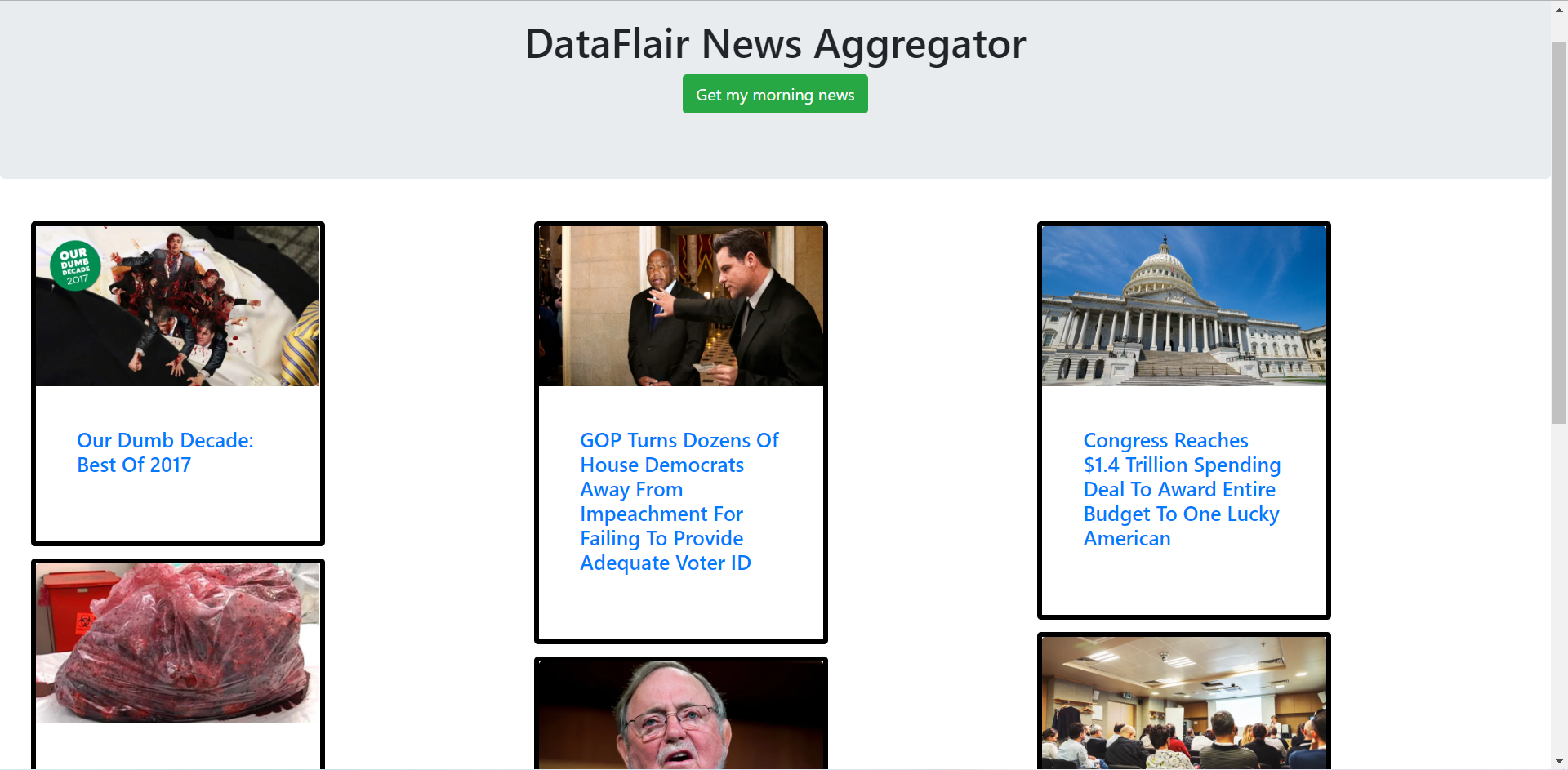
You can click on the links. That will take you to the original article page.
Now, you can configure this to gather your favorite article websites. Although, be wary of blocks. Many times, bots are not legally allowed to scrape content. So, web scraping comes at its own cost.
But, for our purpose, we now know some very cool basics. We also have a very interesting project to showcase. You can enhance this Django application as much as you can.
Summary
We have successfully completed the first project in Django. We are using web scraping and Django. This integration is as easy as invoking a function in Python.
You can make some more projects in Django using the same concepts. Django lets you integrate machine learning too.
How was your experience working on the Django project? Do share in the comment section.
We work very hard to provide you quality material
Could you take 15 seconds and share your happy experience on Google


I personally enjoyed the project given that I am a beginner in django, this has boosted my morals and confidence level. I would love to learn even more and get even more projects to get me going as I grow up my career. Thanks again for this tutorial
Hey Blaise,
Glad that you liked our article. Check these 500+ project ideas and dedicate all your time in implementing the projects & become industry-ready.
how I replace the news articles with another different news, I am not able to change the news articles? plz explain..
To refer to any other news website you can change the url int this line: url = “https ://www. theonion .com/”
That did not work. I even used invalid URLs and it keeps bringing the same old news.
I noticed db.sqlite3 had a record in news_list table which I suspect is the source and not the URL.
Hi, thank you for this article it is very informative. I’m struggling with my models, where dol put this code:
new_headline = Headline()
new_headline.title = title
new_headline.url = link
new_headline.image = image_src
new_headline.save()
You have to paste this in views.py inside the scrape function.
no need to put it any where, it is already present in views.py
I am getting an error which says ‘Headline’ has no ‘objects’ member in views.py
Please guide me
Check your Headline class in models.py file, Its name should strictly match with the one used in views.py file.
I am getting the very old content of the onion site which is being shown in blog not the latest one.How to change that?
Change the url to the lastest one and scrape from the new website.
Thanks for the tutorial, very helpful. However I am only getting the news sites as shown when this tutorial was made, it doesnt give the news on the website so therefor isnt actually giving the morning news…
Do you know of any fixes? Thanks!
Change the url specified in the views.py file and after that, you might need to change some more lines in vies.py to properly scrape from the new website. To change this, you need to observe the HTML code of the new website. To view the HTML code of any website -Right-click anywhere on its home page and then select inspect from the list displayed.
Same here.
I am also not able to get the news after clicking on get morning news. Did you resolve it?
Change the url specified in the views.py file and after that, you might need to change some more lines in vies.py to properly scrape from the new website. To change this, you need to observe the HTML code of the new website. To view the HTML code of any website -Right-click anywhere on its home page and then select inspect from the list displayed.
Whether if I enter a keyword which news I need will I get it the news for the keyword which I entered.?
i need analysis phase and functional and non-functional requirements
Do you have a hospital aggretor based on this?
Based on the requirements you can develop hospital aggregator project, the implementation will be similar
i cannot redirect to the original news link as the url which I’m getting after scrapping is not complete and after adding the base url in front of it ,it is not working it turns like localhost:8000/url_which_I’m_getting after scrapping instead of the original link to the news page. Can you please help me with this?
How to provide tutorial material, soft copy or hardcopy
This project is about collecting the news articles from various websites at one place but here we are only collecting the articles from single website
I personally enjoyed the project but I am getting this error [The view topProd.views.scrape didn’t return an HttpResponse object. It returned None instead]
Thank you for this tutorial! I was looking for a news aggregator project written in python and this one is a good example. I have a question. Basically a News Aggregator scrapes the web. Does it require a proxy as long as it scrapes only link, title and image?
Can I collect news articles from multiple websites at the same time in this program?
Also I’m facing difficulty collecting feeds from another website and I know that I have to change the requirement in views.py but I don’t know exactly what to observer in the html code while inspecting.
please give me full code
from which file can i run this project?
Hello,I am getting an error that “django.db.utils.DatabaseError: file is not a database”.can you tell me how can i resolve it
Several people asked the same question without a solid answer. This isn’t even scrapping new content, it seems like it’s reading from the Sqlite3 DB. Anyways, thanks for sharing.