Apache Flink – A Big Data Processing Platform
Free Flink course with real-time projects Start Now!!
The objective of this tutorial is to understand the recent advancements in Big Data industry, which is taking Big data towards maturity.
Till now to solve real-world problems we need to use multiple frameworks (specialized engines), which is very complex and costly. Today industry needs a unified platform like Apache Flink which alone can solve diverse big data problems.
So, let’s start Apache Flink Tutorial.
Big Data – Introduction
Big Data is still one of the Biggest Buzzwords in the industry. According to Gartner – “Big Data is new Oil”.
It has been accepted by each and every domain (Telecom, Retail, Finance, Healthcare, Banking etc.) that Big Data is a must to handle the growing data and analytics requirements. Overall we can say Big Data is a must for each and every business to survive or grow.
So, let’s talk about how Big Data evolved from the perspective of different solutions. The Big Data came into limelight when Google published a paper (long ago in 2004) about MapReduce a programming paradigm it is using to handle the huge volume of contents for indexing the web(Learn more from here about History of big data ).
After a year industry has got the first solution of Big Data known as Hadoop, if you are new to Hadoop you can follow this guide to understand what is Hadoop.
So, the current problem with the Big Data industry is that daily new tools/technologies are launched which promises something new, different and out-of-the-box.
Being a big data professional (developer, admin, analyst, lead, manager, architect, etc.) it’s very tough to learn a new technology every now and then. Also, it’s very complex and costly to deploy and manage multiple technologies
After Hadoop we keep getting tons of technologies to handle Big Data, like MapReduce – Batch processing engine, Apache Storm – Stream processing engine, Apache Tez – Batch and interactive engine, Apache Giraph – Graph processing engine, Apache Hive – SQL engine.
Specialized Frameworks and Associated Problems
Every framework is a specialized engine which solves some specific problems. But to solve real-world problems we need to combine multiple frameworks. Integration of multiple frameworks is powerful but making them work on the same platform is non-trivial, costly and complex.
Every framework has its own abstraction, to work with them we need to understand/master respective abstractions. They also have individual libraries and runtime, which is very tricky to manage and maintain different runtime on the same cluster.
It’s not possible for big data professionals to learn these many technologies, also it’s not possible for clients to invest huge amount for these multiple technologies.
If we observe each and every technology/tool in the figure is a specialized engine to solve some specific Big Data problems. Some of these frameworks are proprietary rest is open source. It is very difficult to keep upgrading the skills based on new requirements or the introduction of new frameworks.
As big data was in the evolution phase, it was acceptable to use multiple frameworks, but now the situation has become much too complex to handle these many technologies.
What is the solution??
The industry needs a generalized platform which alone can handle diverse workloads like:
- Batch Processing
- Interactive Processing
- Real-time (stream) Processing
- Graph Processing
- Iterative processing
- In-memory processing
Thus. the platform should also provide distributed computing, fault tolerance, high availability, ease of use and lightning fast speed.
The Rise of Big Data Platform
Time for data processing framework is over, now it’s time for the generalized platform. Recent advancements in big data show industry want to use single unified platform for all its Big data requirements.
Single platform evolves faster than multiple frameworks. It’s very easy to develop, manage and maintain the single platform. We need to master single technology to solve all big data problems.
As we move towards unified platform abstraction provided by it becomes crucial. The abstraction must be generic for all the components built on top of it. It should be able to support high-level libraries and tools.
This platform should be able to evolve with new requirements, as with IOT big data is growing faster than ever and there might be new requirements in the near future. It should be able to harness the advancements in the hardware.
Comparison Between the Unified Platform and Multiple Frameworks

Comparison between the unified platform and frameworks in big data
Apache Flink – The Unified Platform
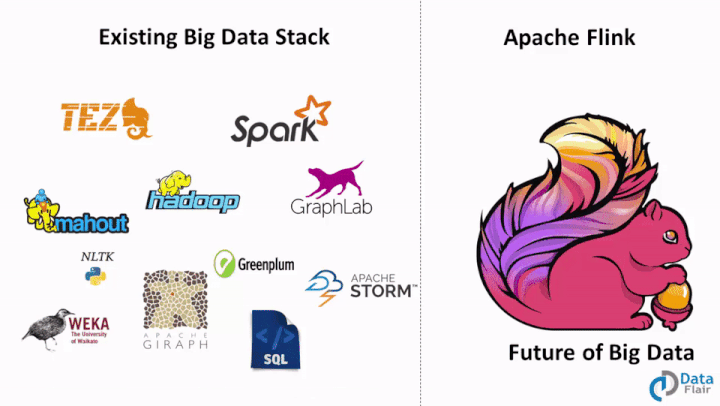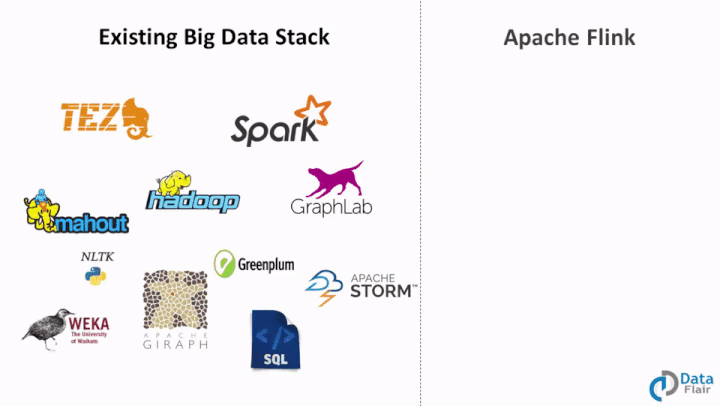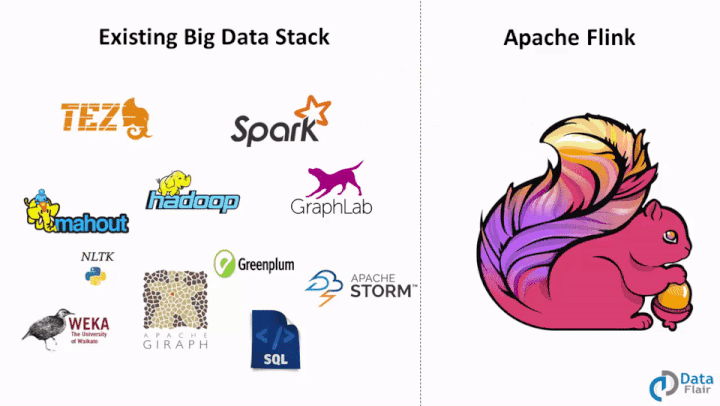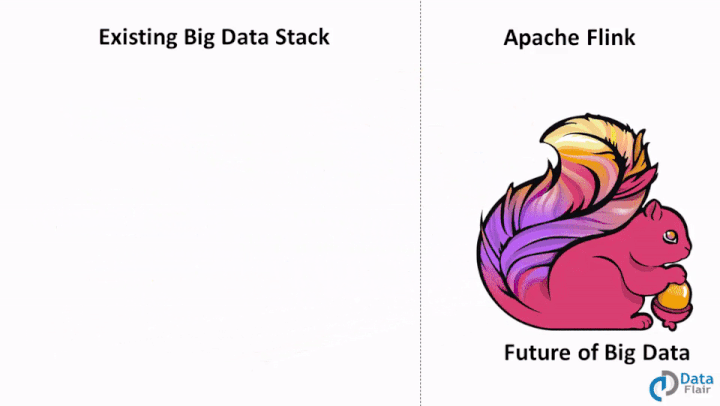
Apache Spark has started the new trend by offering a diverse platform to solve different problems but is limited due to its underlying batch processing engine which processes streams also as micro-batches. Flink has taken the same capability ahead and Flink can solve all the types of Big Data problems.
Apache Flink is a general purpose cluster computing tool, which can handle batch processing, interactive processing, Stream processing, Iterative processing, in-memory processing, graph processing.
Thus, Apache Flink is the next generation Big Data platform also known as 4G of Big Data. At the heart, it is a stream processing framework (doesn’t cut stream into micro-batches).
Flink’s kernel is a streaming runtime which also provides lightning fast speed, fault tolerance, distributed processing, ease of use, etc. Basically, Flink processes data at a consistently high speed with very low latency.
So, it is the large-scale data processing platform which can process data generated at very high speed.
Still, if you have any doubt regarding Apache Flink, ask freely through comments.
Your 15 seconds will encourage us to work even harder
Please share your happy experience on Google

