What is Apache Spark – A Quick Guide to Drift in Spark
1. Objective In this Apache Spark tutorial, we will have a brief look at What is Apache Spark, What is the history of Spark? Apache Spark is an advanced analytics engine which can easily...
![]()
1. Objective In this Apache Spark tutorial, we will have a brief look at What is Apache Spark, What is the history of Spark? Apache Spark is an advanced analytics engine which can easily...
1. Objective In this HDFS tutorial, we are going to learn the remaining important and frequently used HDFS commands using CLI, with the help of which we will be able to perform HDFS file operations...
Practice the most frequently used Hadoop HDFS commands to perform operations on HDFS files/directories with usage and examples. In this Hadoop HDFS commands tutorial, we are going to learn the remaining important and frequently used...
In this Hadoop HDFS Commands tutorial, we are going to learn the remaining important and frequently used Hadoop commands with the help of which we will be able to perform HDFS file operations like...
Explore the most essential and frequently used Hadoop HDFS commands to perform file operations on the world’s most reliable storage. Hadoop HDFS is a distributed file system that provides redundant storage space for files...
1. Install Hadoop 2 on Ubuntu 16.0.4: Objective This document describes how to install Hadoop 2 Ubuntu 16.0.4 OS. Single machine Hadoop cluster is also called as Hadoop Pseudo-Distributed Mode. The steps and procedure given...
Fault tolerance refers to the ability of the system to work or operate even in case of unfavorable conditions (like components failure). In this DataFlair article, we will learn the fault tolerance feature of...
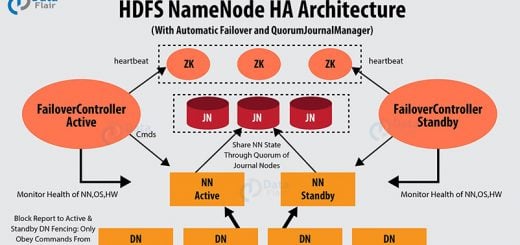
High Availability was a new feature added to Hadoop 2.x to solve the Single point of failure problem in the older versions of Hadoop. As the Hadoop HDFS follows the master-slave architecture where the...
1. Objective Hadoop MapReduce processes a huge amount of data in parallel by dividing the job into a set of independent tasks (sub-job). In Hadoop, MapReduce works by breaking the processing into phases: Map...
1. Objective HDFS follow Write once Read many models. So we cannot edit files already stored in HDFS, but we can append data by reopening the file. In Read-Write operation client first, interact with...