NLTK Python Tutorial (Natural Language Toolkit)
Free Machine Learning courses with 130+ real-time projects Start Now!!
Python course with 57 real-time projects - Learn Python
In our last session, we discussed the NLP Tutorial. Today, in this NLTK Python Tutorial, we will learn to perform Natural Language Processing with NLTK. We will perform tasks like NLTK tokenize, removing stop words, stemming NLTK, lemmatization NLTK, finding synonyms and antonyms, and more.
So, let’s start NLTK Python Tutorial.

NLTK Python Tutorial (Natural Language Toolkit)
What is NLTK?
NLTK stands for Natural Language Toolkit. This is a suite of libraries and programs for symbolic and statistical NLP for English. It ships with graphical demonstrations and sample data.
First getting to see the light in 2001, NLTK hopes to support research and teaching in NLP and other areas closely related. These include Artificial Intelligence, empirical linguistics, cognitive science, information retrieval, and Machine Learning.
How to Install NLTK?
To install NLTK, you can use Python pip-
pip install nltk
Then to import it, you can type in the interpreter-
>>> import nltk
Finally, to install packages from NLTK, you need to use its downloader. Try this-
>>> nltk.download()
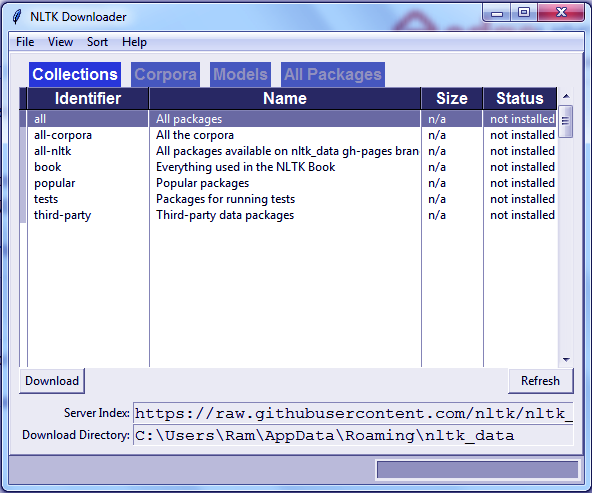
NLTK Python Tutorial – How to Install NLTK?
Technology is evolving rapidly!
Stay updated with DataFlair on WhatsApp!!
You can download all packages or choose the ones you wish to download. Explore the ‘All Packages’ tab.
NLTK Python Tutorial – NLTK Tokenize Text
Before processing the text in NLTK Python Tutorial, you should tokenize it. What we mean is you should split it into smaller parts- paragraphs to sentences, sentences to words. We have two kinds of tokenizers- for sentences and for words.
a. NLTK Sentence Tokenizer
Let’s try tokenizing a sentence.
>>> text="Today is a great day. It is even better than yesterday. And yesterday was the best day ever." >>> from nltk.tokenize import sent_tokenize >>> sent_tokenize(text)
[‘Today is a great day.’, ‘It is even better than yesterday.’, ‘And yesterday was the best day ever.’]
Let’s try another? We’ll use an exchange of dialogues this time.
>>> sent_tokenize("Hi, how are you? I'm good, you? Great!")[‘Hi, how are you?’, “I’m good, you?”, ‘Great!’]
Okay, one more in NLTK Python Tutorial. How about we use words like Mrs. and Martinez’s in the text? Will the tokenizer be able to catch it?
>>> nltk.sent_tokenize("Last night, I went to Mrs. Martinez's housewarming. It was a disaster.")[“Last night, I went to Mrs. Martinez’s housewarming.”, ‘It was a disaster.’]
- Tokenizing for a language other than English-
>>> sent_tokenize("Enchanté, comment allez-vous? Tres bien. Mersi, et vous?","french")[‘Enchanté, comment allez-vous?’, ‘Tres bien.’, ‘Mersi, et vous?’]
- Issues while tokenizing-
One issue we face while tokenizing is abbreviations-
>>> sent_tokenize("She holds an MDS. in Oral Pathology")[‘She holds an MDS.’, ‘in Oral Pathology’]
Whoops! That was supposed to be one complete sentence it split into two.
b. NLTK Word Tokenizer
First, let’s tokenize text in NLTK Python Tutorial.
>>> nltk.word_tokenize(text)
[‘Today’, ‘is’, ‘a’, ‘great’, ‘day’, ‘.’, ‘It’, ‘is’, ‘even’, ‘better’, ‘than’, ‘yesterday’, ‘.’, ‘And’, ‘yesterday’, ‘was’, ‘the’, ‘best’, ‘day’, ‘ever’, ‘.’]
Now, let’s try it for Mrs. Martinez’s housewarming.
>>> nltk.word_tokenize("Last night, I went to Mrs. Martinez's housewarming. It was a disaster.")[‘Last’, ‘night’, ‘,’, ‘I’, ‘went’, ‘to’, ‘Mrs.’, ‘Martinez’, “‘s”, ‘housewarming’, ‘.’, ‘It’, ‘was’, ‘a’, ‘disaster’, ‘.’]
Notice how it judged Mrs. to be one word but Martinez’s to be two? NLTK uses PunktSentenceTokenizer for this.
Have a look at Python Charts
Find Synonyms From NLTK WordNet
WordNet is an NLP database with synonyms, antonyms, and brief definitions. We downloaded this with the NLTK downloader.
>>> from nltk.corpus import wordnet
>>> syn=wordnet.synsets('love')
>>> syn[Synset(‘love.n.01’), Synset(‘love.n.02’), Synset(‘beloved.n.01’), Synset(‘love.n.04’), Synset(‘love.n.05’), Synset(‘sexual_love.n.02’), Synset(‘love.v.01’), Synset(‘love.v.02’), Synset(‘love.v.03’), Synset(‘sleep_together.v.01’)]
Let’s choose the first member from this-
>>> syn[0].definition()
‘a strong positive emotion of regard and affection’
>>> syn[0].examples()
[‘his love for his work’, ‘children need a lot of love’]
But love isn’t the only thing we’re chasing after. Do you know the meaning of life? 42?
>>> syn=wordnet.synsets('life')
>>> syn[0].definition()‘a characteristic state or mode of living’
>>> syn[0].examples()
[‘social life’, ‘city life’, ‘real life’]
Nope, still doesn’t answer our questions. But Python does a good job. Okay, one more example.
>>> syn=wordnet.synsets('AI')
>>> syn[Synset(‘army_intelligence.n.01’), Synset(‘artificial_intelligence.n.01’), Synset(‘three-toed_sloth.n.01’), Synset(‘artificial_insemination.n.01’)]
>>> syn[1].definition()
‘the branch of computer science that deal with writing computer programs that can solve problems creatively’
>>> syn[1].examples()
[‘workers in AI hope to imitate or duplicate intelligence in computers and robots’]
- To get the list of synonyms:
>>> synonyms=[]
>>> for syn in wordnet.synsets('AI'):
for lemma in syn.lemmas():
synonyms.append(lemma.name())
>>> synonyms[‘Army_Intelligence’, ‘AI’, ‘artificial_intelligence’, ‘AI’, ‘three-toed_sloth’, ‘ai’, ‘Bradypus_tridactylus’, ‘artificial_insemination’, ‘AI’]
Find Antonyms From NLTK WordNet
To get the list of antonyms, we first need to check the lemmas- are there antonyms?
>>> from nltk.corpus import wordnet
>>> antonyms=[]
>>> for syn in wordnet.synsets('depressed'):
for l in syn.lemmas():
if l.antonyms():
antonyms.append(l.antonyms()[0].name())
>>> antonyms[‘elate’]
One more?
>>> for syn in wordnet.synsets('ugly'):
for l in syn.lemmas():
if l.antonyms():
antonyms.append(l.antonyms()[0].name())
>>> antonyms[‘beautiful‘]
NLTK Python Tutorial – Stemming NLTK
We have talked of stemming before this. Check Stemming and Lemmatization with Python. Well, stemming involves removing affixes from words and returning the root.
Search engines like Google use this to efficiently index pages. The most common algorithm for stemming is the PorterStemmer. Let’s take an example.
>>> stemmer.stem('loving')‘love’
>>> stemmer.stem('trainee')‘traine’
By now, you have figured we don’t settle for just one example. So here’s more.
>>> stemmer.stem('syllabi')‘syllabi’
>>> stemmer.stem('alibi')‘alibi’
>>> stemmer.stem('formulae')‘formula’
>>> stemmer.stem('criteria')‘criteria’
>>> stemmer.stem('believes')‘believ’
>>> stemmer.stem('writes')‘write’
>>> stemmer.stem('writing')‘write’
>>> stemmer.stem('write')‘write’
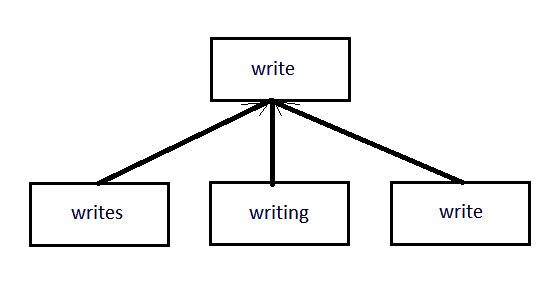
NLTK Python Tutorial – Stemming
Other algorithms include Lancaster and Snowball.
a. Stemming Words from Other Languages
>>> from nltk.stem import SnowballStemmer >>> SnowballStemmer.languages
(‘arabic’, ‘danish’, ‘dutch’, ‘english’, ‘finnish’, ‘french’, ‘german’, ‘hungarian’, ‘italian’, ‘norwegian’, ‘porter’, ‘portuguese’, ‘romanian’, ‘russian’, ‘spanish’, ‘swedish’)
>>> rom_stemmer=SnowballStemmer('romanian')
>>> rom_stemmer.stem('englezească') #English‘englez’
>>> rom_stemmer.stem('cocoș') #Cocks‘cocoș’
>>> rom_stemmer.stem('frigidere') #Refrigerators‘frigid’
>>> rom_stemmer.stem('frigider') #Refrigerator‘frigider’
>>> rom_stemmer.stem('goi') #Empty- plural‘goi’
>>> rom_stemmer.stem('goale') #Empty- plural‘goal’
>>> rom_stemmer.stem('frumoasă') #Beautiful- female‘frumoas’
>>> rom_stemmer.stem('frumoase') #Beautiful- plural‘frumoas’
>>> rom_stemmer.stem('frumoși') #Beautiful- plural‘frumoș’
Psst., please let us know if you catch an incorrect depiction of the language Romanian!
Python NLTK Tutorial – Lemmatizing NLTK Using WordNet
If you noticed, some words that stemming gave us weren’t actual words you could look up in the dictionary. So we come to lemmatizing- this will return real words. Let’s do this too.
>>> from nltk.stem import WordNetLemmatizer
>>> lemmatizer=WordNetLemmatizer()
>>> lemmatizer.lemmatize('believes')‘belief’
Stemming gave us ‘believ’ for this; lemmatizing gave us ‘belief’. See the clear difference? Where stemming returned ‘thi’, see what lemmatizer gives us:
>>> lemmatizer.lemmatize('this')‘this’
With ‘believes’, to work with a verb instead of a noun, use the ‘pos’ argument-
>>> lemmatizer.lemmatize('believes',pos='v')‘believe’
And now, how about some adjectives?
>>> lemmatizer.lemmatize('crossing',pos='a') #adjective‘crossing’
>>> lemmatizer.lemmatize('crossing',pos='v') #verb‘cross’
>>> lemmatizer.lemmatize('crossing',pos='n') #noun‘crossing’
>>> lemmatizer.lemmatize('crossing',pos='r') #adverb‘crossing’
Since lemmatizing gives us better results within context, it is often slower than stemming.
Python NLTK Tutorial – NLTK Stop Words
We can filter NLTK stop words from text before processing it.
>>> from nltk.corpus import stopwords
>>> stopwords.words('english')[‘i’, ‘me’, ‘my’, ‘myself’, ‘we’, ‘our’, ‘ours’, ‘ourselves’, ‘you’, “you’re”, “you’ve”, “you’ll”, “you’d”, ‘your’, ‘yours’, ‘yourself’, ‘yourselves’, ‘he’, ‘him’, ‘his’, ‘himself’, ‘she’, “she’s”, ‘her’, ‘hers’, ‘herself’, ‘it’, “it’s”, ‘its’, ‘itself’, ‘they’, ‘them’, ‘their’, ‘theirs’, ‘themselves’, ‘what’, ‘which’, ‘who’, ‘whom’, ‘this’, ‘that’, “that’ll”, ‘these’, ‘those’, ‘am’, ‘is’, ‘are’, ‘was’, ‘were’, ‘be’, ‘been’, ‘being’, ‘have’, ‘has’, ‘had’, ‘having’, ‘do’, ‘does’, ‘did’, ‘doing’, ‘a’, ‘an’, ‘the’, ‘and’, ‘but’, ‘if’, ‘or’, ‘because’, ‘as’, ‘until’, ‘while’, ‘of’, ‘at’, ‘by’, ‘for’, ‘with’, ‘about’, ‘against’, ‘between’, ‘into’, ‘through’, ‘during’, ‘before’, ‘after’, ‘above’, ‘below’, ‘to’, ‘from’, ‘up’, ‘down’, ‘in’, ‘out’, ‘on’, ‘off’, ‘over’, ‘under’, ‘again’, ‘further’, ‘then’, ‘once’, ‘here’, ‘there’, ‘when’, ‘where’, ‘why’, ‘how’, ‘all’, ‘any’, ‘both’, ‘each’, ‘few’, ‘more’, ‘most’, ‘other’, ‘some’, ‘such’, ‘no’, ‘nor’, ‘not’, ‘only’, ‘own’, ‘same’, ‘so’, ‘than’, ‘too’, ‘very’, ‘s’, ‘t’, ‘can’, ‘will’, ‘just’, ‘don’, “don’t”, ‘should’, “should’ve”, ‘now’, ‘d’, ‘ll’, ‘m’, ‘o’, ‘re’, ‘ve’, ‘y’, ‘ain’, ‘aren’, “aren’t”, ‘couldn’, “couldn’t”, ‘didn’, “didn’t”, ‘doesn’, “doesn’t”, ‘hadn’, “hadn’t”, ‘hasn’, “hasn’t”, ‘haven’, “haven’t”, ‘isn’, “isn’t”, ‘ma’, ‘mightn’, “mightn’t”, ‘mustn’, “mustn’t”, ‘needn’, “needn’t”, ‘shan’, “shan’t”, ‘shouldn’, “shouldn’t”, ‘wasn’, “wasn’t”, ‘weren’, “weren’t”, ‘won’, “won’t”, ‘wouldn’, “wouldn’t”]
>>> from nltk.corpus import stopwords
>>> text="Today is a great day. It is even better than yesterday. And yesterday was the best day ever!"
>>> stopwords=set(stopwords.words('english'))
>>> from nltk.tokenize import word_tokenize
>>> words=word_tokenize(text)
>>> wordsFiltered=[]
>>> for w in words:
if w not in stopwords:
wordsFiltered.append(w)
>>> wordsFiltered[‘Today’, ‘great’, ‘day’, ‘.’, ‘It’, ‘even’, ‘better’, ‘yesterday’, ‘.’, ‘And’, ‘yesterday’, ‘best’, ‘day’, ‘ever’, ‘!’]
NLTK Python Tutorial – Speech Tagging
NLTK can classify words as verbs, nouns, adjectives, and more into one of the following classes:
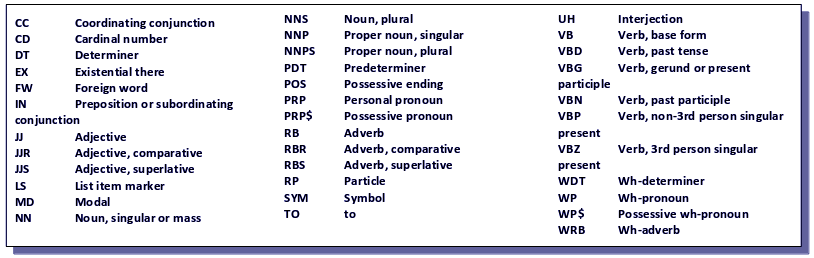
Python NLTK Tutorial – Speech Tagging
>>> import nltk
>>> from nltk.tokenize import PunktSentenceTokenizer
>>> text='I am a human being, capable of doing terrible things'
>>> sentences=nltk.sent_tokenize(text)
>>> for sent in sentences:
print(nltk.pos_tag(nltk.word_tokenize(sent)))[(‘I’, ‘PRP’), (‘am’, ‘VBP’), (‘a’, ‘DT’), (‘human’, ‘JJ’), (‘being’, ‘VBG’), (‘,’, ‘,’), (‘capable’, ‘JJ’), (‘of’, ‘IN’), (‘doing’, ‘VBG’), (‘terrible’, ‘JJ’), (‘things’, ‘NNS’)]
Match the arguments at position 1 with the table to figure out the output.
So, this was all in NLTK Python Tutorial. Hope you like our explanation.
Conclusion
Hence, in this NLTK Python Tutorial, we discussed the basics of Natural Language Processing with Python using NLTK. Moreover, we discussed tokenizing, stemming, lemmatization, finding synonyms and antonyms, speech tagging, and filtering out stop words.
Still, if you have any query regarding NLTK Python Tutorial, ask in the comment tab. You can also share your experience of reading this article through comments.
We work very hard to provide you quality material
Could you take 15 seconds and share your happy experience on Google


nice tutorial. it all worked!
yes
Learning
Can I write a chatbot in Danish for example using NLTK?
Flawless tutorial, very helpful for newbies like me, thanks guys for taking the time in putting this together.
Thank you for your nicely done tutorial on NLTK