How Apache Spark Works – Run-time Spark Architecture
1. Objective
This Apache Spark tutorial will explain the run-time architecture of Apache Spark along with key Spark terminologies like Apache SparkContext, Spark shell, Apache Spark application, task, job and stages in Spark. Moreover, we will also learn about the components of Spark run time architecture like the Spark driver, cluster manager & Spark executors. At last, we will see how Apache spark works using these components.

How Apache Spark Works – Run-time Spark Architecture
Here we are going to learn how Apache Spark Works? In Apache Spark, the central coordinator is called the driver. When you enter your code in spark, SparkContext in the driver program creates the job when we call an Action. This job submits to DAG Scheduler which creates the operator graph and then submits it to task Scheduler. Task Scheduler launches the task via cluster manager. Thus, with the help of a cluster manager, a Spark Application launch on a set of machines.
So, let’s start Spark Architecture.
2. Internals of How Apache Spark works?
Apache Spark is an open source, general-purpose distributed computing engine used for processing and analyzing a large amount of data. Just like Hadoop MapReduce, it also works with the system to distribute data across the cluster and process the data in parallel. Spark uses master/slave architecture i.e. one central coordinator and many distributed workers. Here, the central coordinator is called the driver.
The driver runs in its own Java process. These drivers communicate with a potentially large number of distributed workers called executors. Each executor is a separate java process. A Spark Application is a combination of driver and its own executors. With the help of cluster manager, a Spark Application is launched on a set of machines. Standalone Cluster Manager is the default built in cluster manager of Spark. Apart from its built-in cluster manager, Spark also works with some open source cluster manager like Hadoop Yarn, Apache Mesos etc.
3. Terminologies of Spark
i. Apache SparkContext
SparkContext is the heart of Spark Application. It establishes a connection to the Spark Execution environment. It is used to create Spark RDDs, accumulators, and broadcast variables, access Spark services and run jobs. SparkContext is a client of Spark execution environment and acts as the master of Spark application. The main works of Spark Context are:
- Getting the current status of spark application
- Canceling the job
- Canceling the Stage
- Running job synchronously
- Running job asynchronously
- Accessing persistent RDD
- Unpersisting RDD
- Programmable dynamic allocation
Read about SparkContext in detail.
ii. Apache Spark Shell
Spark Shell is a Spark Application written in Scala. It offers command line environment with auto-completion. It helps us to get familiar with the features of Spark, which help in developing our own Standalone Spark Application. Thus, this tool helps in exploring Spark and is also the reason why Spark is so helpful in processing data set of all size.
iii. Spark Application
The Spark application is a self-contained computation that runs user-supplied code to compute a result. A Spark application can have processes running on its behalf even when it’s not running a job.
iv. Task
A task is a unit of work that sends to the executor. Each stage has some task, one task per partition. The Same task is done over different partitions of RDD.
Learn: Spark Shell Commands to Interact with Spark-Scala
v. Job
The job is parallel computation consisting of multiple tasks that get spawned in response to actions in Apache Spark.
vi. Stage
Each job divides into smaller sets of tasks called stages that depend on each other. Stages are classified as computational boundaries. All computation cannot be done in a single stage. It achieves over many stages.
4. Components of Spark Run-time Architecture
i. Apache Spark Driver
The main() method of the program runs in the driver. The driver is the process that runs the user code that creates RDDs, and performs transformation and action, and also creates SparkContext. When the Spark Shell is launched, this signifies that we have created a driver program. On the termination of the driver, the application is finished.
The driver program splits the Spark application into the task and schedules them to run on the executor. The task scheduler resides in the driver and distributes task among workers. The two main key roles of drivers are:
- Converting user program into the task.
- Scheduling task on the executor.
The structure of Spark program at a higher level is: RDDs consist of some input data, derive new RDD from existing using various transformations, and then after it performs an action to compute data. In Spark Program, the DAG (directed acyclic graph) of operations create implicitly. And when the driver runs, it converts that Spark DAG into a physical execution plan.
ii. Apache Spark Cluster Manager
Spark relies on cluster manager to launch executors and in some cases, even the drivers launch through it. It is a pluggable component in Spark. On the cluster manager, jobs and action within a spark application scheduled by Spark Scheduler in a FIFO fashion. Alternatively, the scheduling can also be done in Round Robin fashion. The resources used by a Spark application can dynamically adjust based on the workload. Thus, the application can free unused resources and request them again when there is a demand. This is available on all coarse-grained cluster managers, i.e. standalone mode, YARN mode, and Mesos coarse-grained mode.
Learn: Spark RDD – Introduction, Features & Operations of RDD
iii. Apache Spark Executors
The individual task in the given Spark job runs in the Spark executors. Executors launch once in the beginning of Spark Application and then they run for the entire lifetime of an application. Even if the Spark executor fails, the Spark application can continue with ease. There are two main roles of the executors:
- Runs the task that makes up the application and returns the result to the driver.
- Provide in-memory storage for RDDs that are cached by the user.
5. How to launch a Program in Spark?
Despite using any cluster manager, Spark comes with the facility of a single script that can use to submit a program, called as spark-submit. It launches the application on the cluster. There are various options through which spark-submit can connect to different cluster manager and control how many resources our application gets. For some cluster managers, spark-submit can run the driver within the cluster (e.g., on a YARN worker node), while for others, it can run only on your local machine.
6. How to Run Apache Spark Application on a cluster
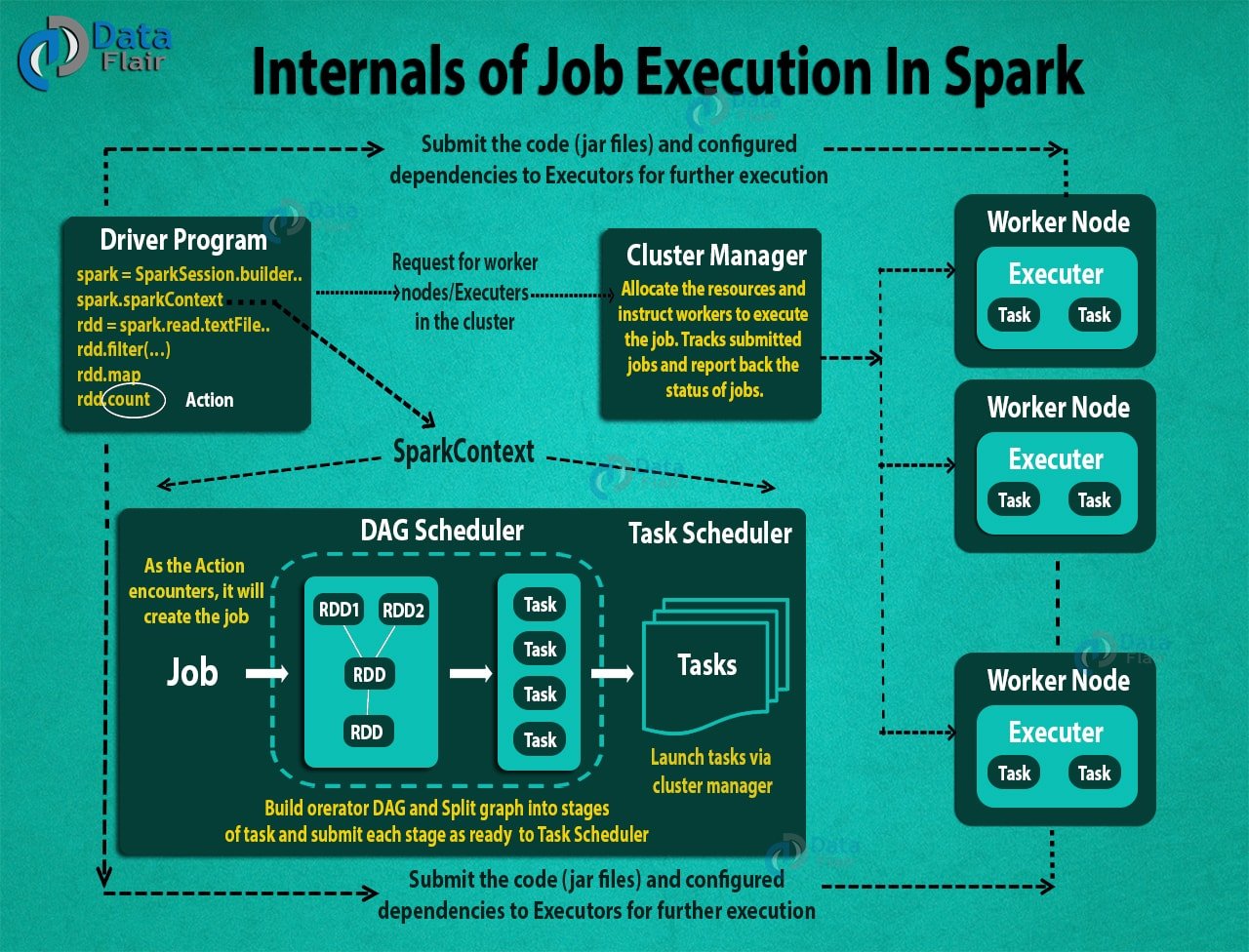
Complete Picture of Apache Spark Job Execution Flow.
- Using spark-submit, the user submits an application.
- In spark-submit, we invoke the main() method that the user specifies. It also launches the driver program.
- The driver program asks for the resources to the cluster manager that we need to launch executors.
- The cluster manager launches executors on behalf of the driver program.
- The driver process runs with the help of user application. Based on the actions and transformation on RDDs, the driver sends work to executors in the form of tasks.
- The executors process the task and the result sends back to the driver through the cluster manager.
So, this was all in how Apache Spark works. If you have any query about Apache Spark job execution flow, so feel free to share with us. We will be happy to solve them.
Reference:
http://spark.apache.org/
See Also-
Your opinion matters
Please write your valuable feedback about DataFlair on Google


hi,
can you please help on below.
we are using spark with java.
we are trying to read the data from hive tables(internally stores in parquet format) using dataframe and converting this to java rdd and working on some transformations and actions but not working.
if you have any reference please share.
I am currently doing a feasibility work in spark. An xml file is the input to the feasibility work.
I have read the topic how Apache spark works. One suggestion,If you explain with sample application, information will be more clear.
I have some doubts on input file partitioning.
This is sample application in python- wordcount
if __name__ == “__main__”:
if len(sys.argv) != 2:
print(“Usage: wordcount “, file=sys.stderr)
exit(-1)
spark = SparkSession\
.builder\
.appName(“PythonWordCount”)\
.getOrCreate()
lines = spark.read.text(sys.argv[1]).rdd.map(lambda r: r[0])
counts = lines.flatMap(lambda x: x.split(‘ ‘)) \
.map(lambda x: (x, 1)) \
.reduceByKey(add)
output = counts.collect()
for (word, count) in output:
print(“%s: %i” % (word, count))
spark.stop()
some doubts
1. Is the above function run in the driver?
2. which tasks are running in parallel?
3. How the input file is being partitioned and in which line?
4. Can we control the partitioning?
My requirement- a task should be done on a partition which contains a specified tag in the xml file.
XML file should be partitioned by the tag
I would like a download link please