Top Features of HDFS – An Overview for Beginners
Have you ever thought why the Hadoop Distributed File system is the world’s most reliable storage system?
Hadoop Distributed File System(HDFS) can store a large quantity of structured as well as unstructured data. HDFS provides reliable storage for data with its unique feature of Data Replication. HDFS is highly fault-tolerant, reliable, available, scalable, distributed file system.
The article enlists the essential features of HDFS like cost-effective, fault tolerance, high availability, high throughput, etc.
Before discussing the features of HDFS, let us first revise the short introduction to HDFS.
Introduction to HDFS
HDFS is the Hadoop Distributed File System for storing large data ranging in size from Megabytes to Petabytes across multiple nodes in a Hadoop cluster.
HDFS breaks the files into data blocks, creates replicas of files blocks, and store them on different machines. It is highly fault-tolerant and reliable distributed storage for big data.
Features of HDFS
The key features of HDFS are:
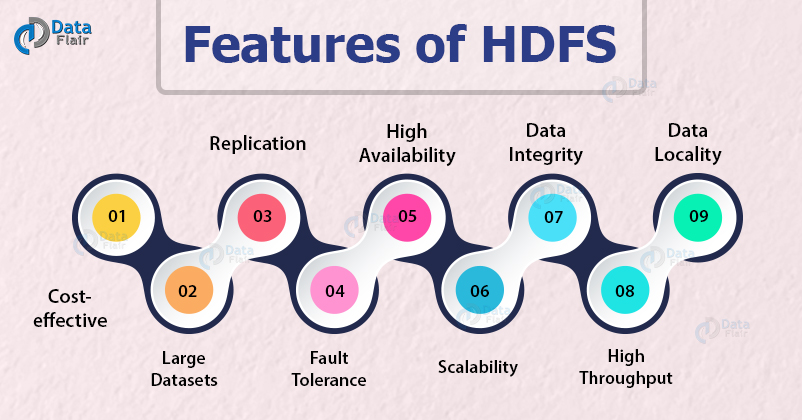
1. Cost-effective:
In HDFS architecture, the DataNodes, which stores the actual data are inexpensive commodity hardware, thus reduces storage costs.
2. Large Datasets/ Variety and volume of data
HDFS can store data of any size (ranging from megabytes to petabytes) and of any formats (structured, unstructured).
3. Replication
Data Replication is one of the most important and unique features of HDFS. In HDFS replication of data is done to solve the problem of data loss in unfavorable conditions like crashing of a node, hardware failure, and so on.
The data is replicated across a number of machines in the cluster by creating replicas of blocks. The process of replication is maintained at regular intervals of time by HDFS and HDFS keeps creating replicas of user data on different machines present in the cluster.
Hence whenever any machine in the cluster gets crashed, the user can access their data from other machines that contain the blocks of that data. Hence there is no possibility of a loss of user data.
Follow this guide to learn more about the data read operation.
4. Fault Tolerance and reliability
HDFS is highly fault-tolerant and reliable. HDFS creates replicas of file blocks depending on the replication factor and stores them on different machines.
If any of the machines containing data blocks fail, other DataNodes containing the replicas of that data blocks are available. Thus ensuring no loss of data and makes the system reliable even in unfavorable conditions.
Hadoop 3 introduced Erasure Coding to provide Fault Tolerance. Erasure Coding in HDFS improves storage efficiency while providing the same level of fault tolerance and data durability as traditional replication-based HDFS deployment.
To study the fault tolerance features in detail, refer to Fault Tolerance.
5. High Availability
The High availability feature of Hadoop ensures the availability of data even during NameNode or DataNode failure.
Since HDFS creates replicas of data blocks, if any of the DataNodes goes down, the user can access his data from the other DataNodes containing a copy of the same data block.
Also, if the active NameNode goes down, the passive node takes the responsibility of the active NameNode. Thus, data will be available and accessible to the user even during a machine crash.
To study the high availability feature in detail, refer to the High Availability article.
6. Scalability
As HDFS stores data on multiple nodes in the cluster, when requirements increase we can scale the cluster.
There is two scalability mechanism available: Vertical scalability – add more resources (CPU, Memory, Disk) on the existing nodes of the cluster.
Another way is horizontal scalability – Add more machines in the cluster. The horizontal way is preferred since we can scale the cluster from 10s of nodes to 100s of nodes on the fly without any downtime.
7. Data Integrity
Data integrity refers to the correctness of data. HDFS ensures data integrity by constantly checking the data against the checksum calculated during the write of the file.
While file reading, if the checksum does not match with the original checksum, the data is said to be corrupted. The client then opts to retrieve the data block from another DataNode that has a replica of that block. The NameNode discards the corrupted block and creates an additional new replica.
8. High Throughput
Hadoop HDFS stores data in a distributed fashion, which allows data to be processed parallelly on a cluster of nodes. This decreases the processing time and thus provides high throughput.
9. Data Locality
Data locality means moving computation logic to the data rather than moving data to the computational unit.
In the traditional system, the data is brought at the application layer and then gets processed.
But in the present scenario, due to the massive volume of data, bringing data to the application layer degrades the network performance.
In HDFS, we bring the computation part to the Data Nodes where data resides. Hence, with Hadoop HDFS, we are not moving computation logic to the data, rather than moving data to the computation logic. This feature reduces the bandwidth utilization in a system.
Summary
In short, after looking at HDFS features we can say that HDFS is a cost-effective, distributed file system. It is highly fault-tolerant. HDFS ensures high availability of the Hadoop cluster.
HDFS provides horizontal scalability. It also checks for data integrity. We can store large volume and variety of data in HDFS.
To learn more about HDFS follow the introductory guide.
If you find any difficulty while working with HDFS, ask us.
Keep Learning!!
You give me 15 seconds I promise you best tutorials
Please share your happy experience on Google


Nice blog to Learn Big Data from Basics
This line “Hence, with Hadoop HDFS, we are not moving computation logic to the data, rather than moving data to the computation logic.” is wrong, it should be other way round