Apache Spark vs Hadoop MapReduce – Feature Wise Comparison [Infographic]
Apache Spark is an open-source, lightning fast big data framework which is designed to enhance the computational speed. Hadoop MapReduce, read and write from the disk, as a result, it slows down the computation. While Spark can run on top of Hadoop and provides a better computational speed solution. This tutorial gives a thorough comparison between Apache Spark vs Hadoop MapReduce.
In this guide, we will cover what is the difference between Spark and Hadoop MapReduce, how Spark is 100x faster than MapReduce. This comprehensive guide will provide feature wise comparison between Apache Spark and Hadoop MapReduce.
Note – Don’t miss the end, it contains Spark Vs Hadoop MapReduce.
So, let’s start the comparison of Spark vs Hadoop MapReduce.
Comparison Between Apache Spark vs Hadoop MapReduce
Below is the featurewise comparison of Apache Spark vs Hadoop MapReduce, let’s discuss in detail –
i. Introduction
- Apache Spark – It is an open source big data framework. It provides faster and more general purpose data processing engine. Spark is basically designed for fast computation. It also covers a wide range of workloads for example batch, interactive, iterative and streaming.
- Hadoop MapReduce – It is also an open source framework for writing applications. It also processes structured and unstructured data that are stored in HDFS. Hadoop MapReduce is designed in a way to process a large volume of data on a cluster of commodity hardware. MapReduce can process data in batch mode.
ii. Speed
- Apache Spark – Spark is a lightning fast cluster computing tool. Apache Spark runs applications up to 100x faster in memory and 10x faster on disk than Hadoop. Because of reducing the number of the reading/write cycle to disk and storing intermediate data in-memory Spark makes it possible.
- Hadoop MapReduce – MapReduce reads and writes from disk, as a result, it slows down the processing speed.
iii. Difficulty
- Apache Spark – Spark is easy to program as it has tons of high-level operators with RDD – Resilient Distributed Dataset.
- Hadoop MapReduce – In MapReduce, developers need to hand code each and every operation which makes it very difficult to work.
iv. Easy to Manage
- Apache Spark – Spark is capable of performing batch, interactive and Machine Learning and Streaming all in the same cluster. As a result, makes it a complete data analytics engine. Thus, no need to manage different component for each need. Installing Spark on a cluster will be enough to handle all the requirements.
- Hadoop MapReduce – As MapReduce only provides the batch engine. Hence, we are dependent on different engines. For example- Storm, Giraph, Impala, etc. for other requirements. So, it is very difficult to manage many components.
v. Real-time analysis
- Apache Spark – It can process real-time data i.e. data coming from the real-time event streams at the rate of millions of events per second, e.g. Twitter data for instance or Facebook sharing/posting. Spark’s strength is the ability to process live streams efficiently.
- Hadoop MapReduce – MapReduce fails when it comes to real-time data processing as it was designed to perform batch processing on voluminous amounts of data.
vi. latency
- Apache Spark – Spark provides low-latency computing.
- Hadoop MapReduce – MapReduce is a high latency computing framework.
vii. Interactive mode
- Apache Spark – Spark can process data interactively.
- Hadoop MapReduce – MapReduce doesn’t have an interactive mode.
viii. Streaming
- Apache Spark – Spark can process real-time data through Spark Streaming.
- Hadoop MapReduce – With MapReduce, you can only process data in batch mode.
ix. Ease of use
- Apache Spark – Spark is easier to use. Since its abstraction (RDD) enables a user to process data using high-level operators. It also provides rich APIs in Java, Scala, Python, and R.
- Hadoop MapReduce – MapReduce is complex. As a result, we need to handle low-level APIs to process the data, which requires lots of hand coding.
x. Recovery
- Apache Spark – RDDs allows recovery of partitions on failed nodes by re-computation of the DAG while also supporting a more similar recovery style to Hadoop by way of checkpointing, to reduce the dependencies of an RDDs.
- Hadoop MapReduce – MapReduce is naturally resilient to system faults or failures. So, it is a highly fault-tolerant system.
xi. Scheduler
- Apache Spark – Due to in-memory computation spark acts its own flow scheduler.
- Hadoop MapReduce – MapReduce needs an external job scheduler for example, Oozie to schedule complex flows.
xii. Fault tolerance
- Apache Spark – Spark is fault-tolerant. As a result, there is no need to restart the application from scratch in case of any failure.
- Hadoop MapReduce – Like Apache Spark, MapReduce is also fault-tolerant, so there is no need to restart the application from scratch in case of any failure.
xiii. Security
- Apache Spark – Spark is little less secure in comparison to MapReduce because it supports the only authentication through shared secret password authentication.
- Hadoop MapReduce – Apache Hadoop MapReduce is more secure because of Kerberos and it also supports Access Control Lists (ACLs) which are a traditional file permission model.
xiv. Cost
- Apache Spark – As spark requires a lot of RAM to run in-memory. Thus, increases the cluster, and also its cost.
- Hadoop MapReduce – MapReduce is a cheaper option available while comparing it in terms of cost.
xv. Language Developed
- Apache Spark – Spark is developed in Scala.
- Hadoop MapReduce – Hadoop MapReduce is developed in Java.
xvi. Category
- Apache Spark – It is data analytics engine. Hence, it is a choice for Data Scientist.
- Hadoop MapReduce – It is basic data processing engine.
xvii. License
- Apache Spark – Apache License 2
- Hadoop MapReduce – Apache License 2
xviii. OS support
- Apache Spark – Spark supports cross-platform.
- Hadoop MapReduce – Hadoop MapReduce also supports cross-platform.
xix. Programming Language support
- Apache Spark – Scala, Java, Python, R, SQL.
- Hadoop MapReduce – Primarily Java, other languages like C, C++, Ruby, Groovy, Perl, Python are also supported using Hadoop streaming.
xx. SQL support
- Apache Spark – It enables the user to run SQL queries using Spark SQL.
- Hadoop MapReduce – It enables users to run SQL queries using Apache Hive.
xxi. Scalability
- Apache Spark – Spark is highly scalable. Thus, we can add n number of nodes in the cluster. Also, a largest known Spark Cluster is of 8000 nodes.
- Hadoop MapReduce – MapReduce is also highly scalable we can keep adding n number of nodes in the cluster. Also, the largest known Hadoop cluster is of 14000 nodes.
xxii. The line of code
- Apache Spark – Apache Spark is developed in merely 20000 line of codes.
- Hadoop MapReduce – Hadoop 2.0 has 1,20,000 line of codes
xxiii. Machine Learning
- Apache Spark – Spark has its own set of machine learning ie MLlib.
- Hadoop MapReduce – Hadoop requires machine learning tool for example Apache Mahout.
xxiv. Caching
- Apache Spark – Spark can cache data in memory for further iterations. As a result, it enhances system performance.
- Hadoop MapReduce – MapReduce cannot cache the data in memory for future requirements. So, the processing speed is not that high as that of Spark.
xxv. Hardware Requirements
- Apache Spark – Spark needs mid to high-level hardware.
- Hadoop MapReduce – MapReduce runs very well on commodity hardware.
xxvi. Community
- Apache Spark – Spark is one of the most active projects at Apache. Since it has a very strong community.
- Hadoop MapReduce – MapReduce community has been shifted to Spark.
Apache Spark Vs Hadoop MapReduce – Infographic
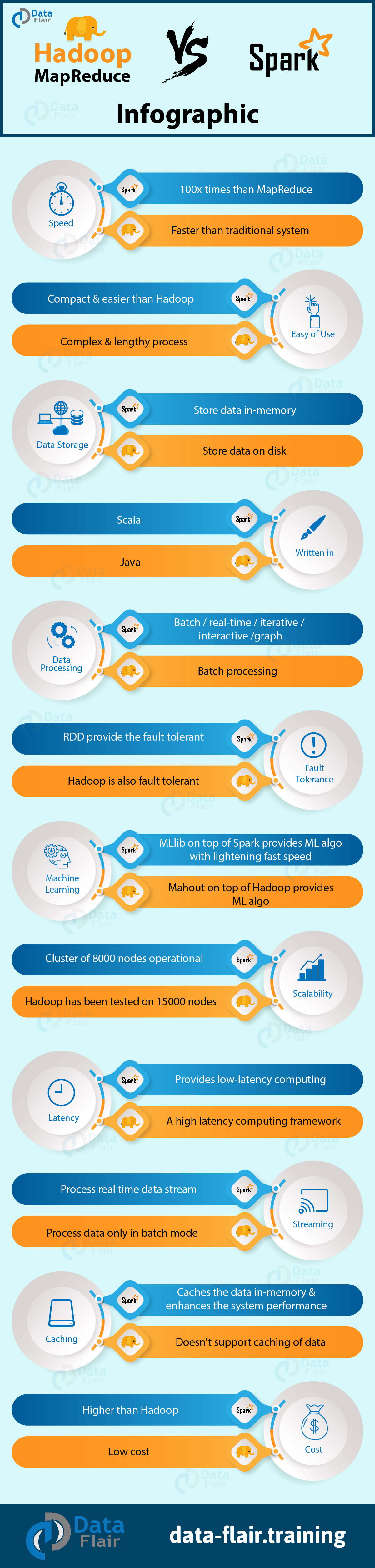
So, this was all in Spark vs Hadoop MapReduce. Hope you like our explanation.
Conclusion
Hence, the differences between Apache Spark vs Hadoop MapReduce shows that Apache Spark is much-advance cluster computing engine than MapReduce. Moreover, Spark can handle any type of requirements (batch, interactive, iterative, streaming, graph) while MapReduce limits to Batch processing. Also, Spark is one of the favorite choices of data scientist. So, Apache Spark is growing very quickly and replacing MapReduce. The framework Apache Flink surpasses Apache Spark. To know the difference, please read the comparison on Hadoop vs Spark vs Flink.
If you have any query about Apache Spark vs Hadoop MapReduce, So, feel free to share with us. We will be glad to solve your queries.
See Also-
If you are Happy with DataFlair, do not forget to make us happy with your positive feedback on Google


If some one wishes to be updated with most recent Big data technologies then he must be pay a visit this web
site and be up to date daily.
Very descriptive blog, I loved that bit. Will there be a part 2?
Wonderful blog! I found it while browsing on Yahoo. Nice differences between Spark and Map Reduce. Please share some differences between Spark and Flink as well.
Thanks
Some really interesting info on difference between spark and map reduce, well written.
Hello, this weekend is good in support of me, for the reason that this moment i am reading this fantastic informative post on Spark vs Hadoop here at my house.
when you compared spark with storm you said that its non-real time but now you are saying its for realtime analytics